Clustering Survival Data using a Mixture of Non-parametric Experts
2405.15934
0
0

Abstract
Survival analysis aims to predict the timing of future events across various fields, from medical outcomes to customer churn. However, the integration of clustering into survival analysis, particularly for precision medicine, remains underexplored. This study introduces SurvMixClust, a novel algorithm for survival analysis that integrates clustering with survival function prediction within a unified framework. SurvMixClust learns latent representations for clustering while also predicting individual survival functions using a mixture of non-parametric experts. Our evaluations on five public datasets show that SurvMixClust creates balanced clusters with distinct survival curves, outperforms clustering baselines, and competes with non-clustering survival models in predictive accuracy, as measured by the time-dependent c-index and log-rank metrics.
Create account to get full access
Overview
- This paper proposes a novel method for clustering survival data using a mixture of non-parametric experts.
- The method aims to identify distinct survival patterns within a heterogeneous population, which can provide valuable insights for healthcare and other applications.
- The model is designed to be interpretable, allowing for the identification of important features that contribute to the survival patterns.
Plain English Explanation
The paper describes a new way to analyze survival data, which is information about how long people or things survive before a certain event occurs, such as death or device failure. The researchers developed a Clustering Survival Data using a Mixture of Non-parametric Experts model that can identify different groups or "clusters" within the survival data, each with its own unique survival pattern.
This is useful because in many real-world situations, a population or group of people or objects may have very different survival experiences, even if they appear similar on the surface. By uncovering these hidden survival patterns, the model can provide valuable insights that could inform healthcare decisions, product design, and other applications.
The key aspect of this model is that it is "interpretable," meaning the researchers can understand which factors or features are most important in determining the different survival patterns. This is in contrast to some "black box" machine learning models that can make accurate predictions but don't explain how they arrived at those predictions.
By making the model interpretable, the researchers can gain a deeper understanding of the underlying drivers of the survival patterns, which can lead to more informed and targeted interventions or strategies.
Technical Explanation
The proposed Clustering Survival Data using a Mixture of Non-parametric Experts model is a novel approach for analyzing survival data that combines several key elements:
-
Mixture Model: The model uses a mixture of multiple sub-models, each representing a distinct survival pattern or "cluster" within the data. This allows the model to capture the heterogeneity in the population, rather than assuming a single survival distribution.
-
Non-parametric Experts: Each sub-model, or "expert," is a non-parametric model, meaning it does not make assumptions about the underlying survival distribution. This provides flexibility in modeling complex, real-world survival patterns.
-
Interpretability: The model is designed to be interpretable, allowing the researchers to identify the key features that contribute to the different survival patterns. This is achieved through the use of a sparse, regularized model structure.
The model is trained using a Bayesian inference approach, which provides a probabilistic framework for estimating the model parameters and cluster assignments. This allows for the quantification of uncertainty in the results, which can be important for critical applications like healthcare.
The paper demonstrates the effectiveness of the proposed model through experiments on both synthetic and real-world survival datasets, including applications in cancer survival prediction and multimodal survival analysis. The results show that the model can outperform existing methods in terms of both predictive performance and interpretability.
Critical Analysis
The paper provides a comprehensive and well-designed study, but there are a few potential limitations and areas for further research:
-
Computational Complexity: The Bayesian inference approach used in the model can be computationally intensive, especially for large-scale datasets. The authors mention that they use variational inference techniques to mitigate this, but the scalability of the model may still be a concern in some applications.
-
Feature Selection: While the model is designed to be interpretable, the authors note that the feature selection process can still be challenging, particularly when dealing with high-dimensional data. Further research may be needed to improve the feature selection and interpretation capabilities of the model.
-
Validation on Diverse Datasets: The experiments in the paper focus on a limited number of datasets, primarily in the healthcare domain. It would be valuable to assess the model's performance and interpretability on a wider range of survival datasets from different application areas to further validate its generalizability.
-
Temporal Dynamics: The current model does not explicitly account for the temporal dynamics of survival data, which can be an important consideration in many real-world scenarios. Extending the model to better handle time-varying covariates or time-dependent survival patterns could be an area for future research.
Overall, the Clustering Survival Data using a Mixture of Non-parametric Experts model represents a promising approach for analyzing complex survival data and could have significant implications for various fields, particularly healthcare and product design. The authors have made a valuable contribution to the field of survival analysis, and the model's interpretability and flexibility make it an attractive option for researchers and practitioners.
Conclusion
The paper presents a novel Clustering Survival Data using a Mixture of Non-parametric Experts model that can identify distinct survival patterns within a heterogeneous population. The key strengths of the model are its interpretability, which allows for the identification of important features driving the survival patterns, and its flexibility in modeling complex, real-world survival data.
The experiments demonstrate the model's effectiveness in several applications, including cancer survival prediction and multimodal survival analysis. While the model has some potential limitations, such as computational complexity and feature selection challenges, the authors have made a significant contribution to the field of survival analysis, and the model's interpretability and versatility make it a valuable tool for researchers and practitioners in various domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
Deep Clustering Survival Machines with Interpretable Expert Distributions
Bojian Hou, Hongming Li, Zhicheng Jiao, Zhen Zhou, Hao Zheng, Yong Fan
0
0
Conventional survival analysis methods are typically ineffective to characterize heterogeneity in the population while such information can be used to assist predictive modeling. In this study, we propose a hybrid survival analysis method, referred to as deep clustering survival machines, that combines the discriminative and generative mechanisms. Similar to the mixture models, we assume that the timing information of survival data is generatively described by a mixture of certain numbers of parametric distributions, i.e., expert distributions. We learn weights of the expert distributions for individual instances according to their features discriminatively such that each instance's survival information can be characterized by a weighted combination of the learned constant expert distributions. This method also facilitates interpretable subgrouping/clustering of all instances according to their associated expert distributions. Extensive experiments on both real and synthetic datasets have demonstrated that the method is capable of obtaining promising clustering results and competitive time-to-event predicting performance.
4/9/2024
🧠
Neural Topic Models with Survival Supervision: Jointly Predicting Time-to-Event Outcomes and Learning How Clinical Features Relate
George H. Chen, Linhong Li, Ren Zuo, Amanda Coston, Jeremy C. Weiss
0
0
We present a neural network framework for learning a survival model to predict a time-to-event outcome while simultaneously learning a topic model that reveals feature relationships. In particular, we model each subject as a distribution over topics, where a topic could, for instance, correspond to an age group, a disorder, or a disease. The presence of a topic in a subject means that specific clinical features are more likely to appear for the subject. Topics encode information about related features and are learned in a supervised manner to predict a time-to-event outcome. Our framework supports combining many different topic and survival models; training the resulting joint survival-topic model readily scales to large datasets using standard neural net optimizers with minibatch gradient descent. For example, a special case is to combine LDA with a Cox model, in which case a subject's distribution over topics serves as the input feature vector to the Cox model. We explain how to address practical implementation issues that arise when applying these neural survival-supervised topic models to clinical data, including how to visualize results to assist clinical interpretation. We study the effectiveness of our proposed framework on seven clinical datasets on predicting time until death as well as hospital ICU length of stay, where we find that neural survival-supervised topic models achieve competitive accuracy with existing approaches while yielding interpretable clinical topics that explain feature relationships. Our code is available at: https://github.com/georgehc/survival-topics
6/6/2024

A Large-Scale Neutral Comparison Study of Survival Models on Low-Dimensional Data
Lukas Burk, John Zobolas, Bernd Bischl, Andreas Bender, Marvin N. Wright, Raphael Sonabend
0
0
This work presents the first large-scale neutral benchmark experiment focused on single-event, right-censored, low-dimensional survival data. Benchmark experiments are essential in methodological research to scientifically compare new and existing model classes through proper empirical evaluation. Existing benchmarks in the survival literature are often narrow in scope, focusing, for example, on high-dimensional data. Additionally, they may lack appropriate tuning or evaluation procedures, or are qualitative reviews, rather than quantitative comparisons. This comprehensive study aims to fill the gap by neutrally evaluating a broad range of methods and providing generalizable conclusions. We benchmark 18 models, ranging from classical statistical approaches to many common machine learning methods, on 32 publicly available datasets. The benchmark tunes for both a discrimination measure and a proper scoring rule to assess performance in different settings. Evaluating on 8 survival metrics, we assess discrimination, calibration, and overall predictive performance of the tested models. Using discrimination measures, we find that no method significantly outperforms the Cox model. However, (tuned) Accelerated Failure Time models were able to achieve significantly better results with respect to overall predictive performance as measured by the right-censored log-likelihood. Machine learning methods that performed comparably well include Oblique Random Survival Forests under discrimination, and Cox-based likelihood-boosting under overall predictive performance. We conclude that for predictive purposes in the standard survival analysis setting of low-dimensional, right-censored data, the Cox Proportional Hazards model remains a simple and robust method, sufficient for practitioners.
6/7/2024
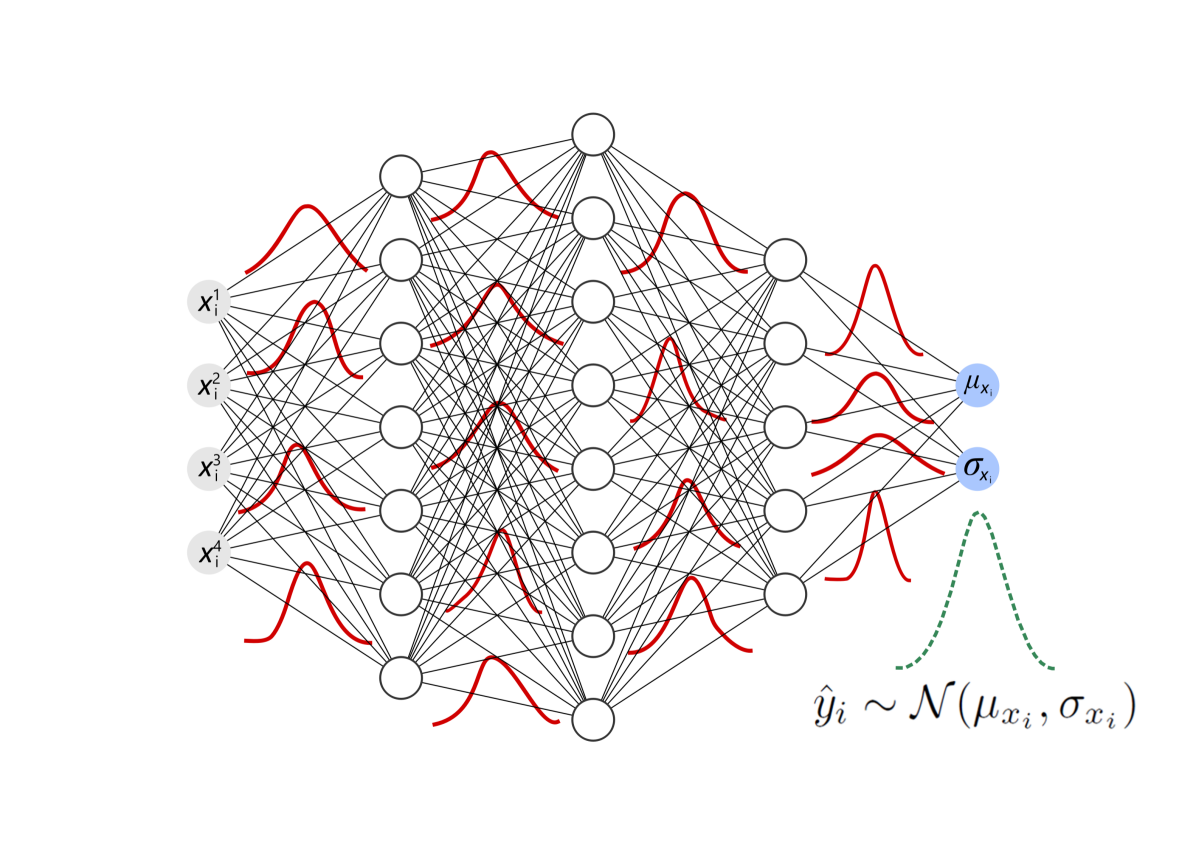
Bayesian Survival Analysis by Approximate Inference of Neural Networks
Christian Marius Lillelund, Martin Magris, Christian Fischer Pedersen
0
0
Variational Inference (VI) is a commonly used technique for approximate Bayesian inference and uncertainty estimation in deep learning models, yet it comes at a computational cost, as it doubles the number of trainable parameters to represent uncertainty. This rapidly becomes challenging in high-dimensional settings and motivates the use of alternative techniques for inference, such as Monte Carlo Dropout (MCD) or Spectral-normalized Neural Gaussian Process (SNGP). However, such methods have seen little adoption in survival analysis, and VI remains the prevalent approach for training probabilistic neural networks. In this paper, we investigate how to train deep probabilistic survival models in large datasets without introducing additional overhead in model complexity. To achieve this, we adopt three probabilistic approaches, namely VI, MCD, and SNGP, and evaluate them in terms of their prediction performance, calibration performance, and model complexity. In the context of probabilistic survival analysis, we investigate whether non-VI techniques can offer comparable or possibly improved prediction performance and uncertainty calibration compared to VI. In the MIMIC-IV dataset, we find that MCD aligns with VI in terms of the concordance index (0.748 vs. 0.743) and mean absolute error (254.9 vs. 254.7) using hinge loss, while providing C-calibrated uncertainty estimates. Moreover, our SNGP implementation provides D-calibrated survival functions in all datasets compared to VI (4/4 vs. 2/4, respectively). Our work encourages the use of techniques alternative to VI for survival analysis in high-dimensional datasets, where computational efficiency and overhead are of concern.
6/21/2024