Co-Speech Gesture Video Generation via Motion-Decoupled Diffusion Model
2404.01862
0
1
Abstract
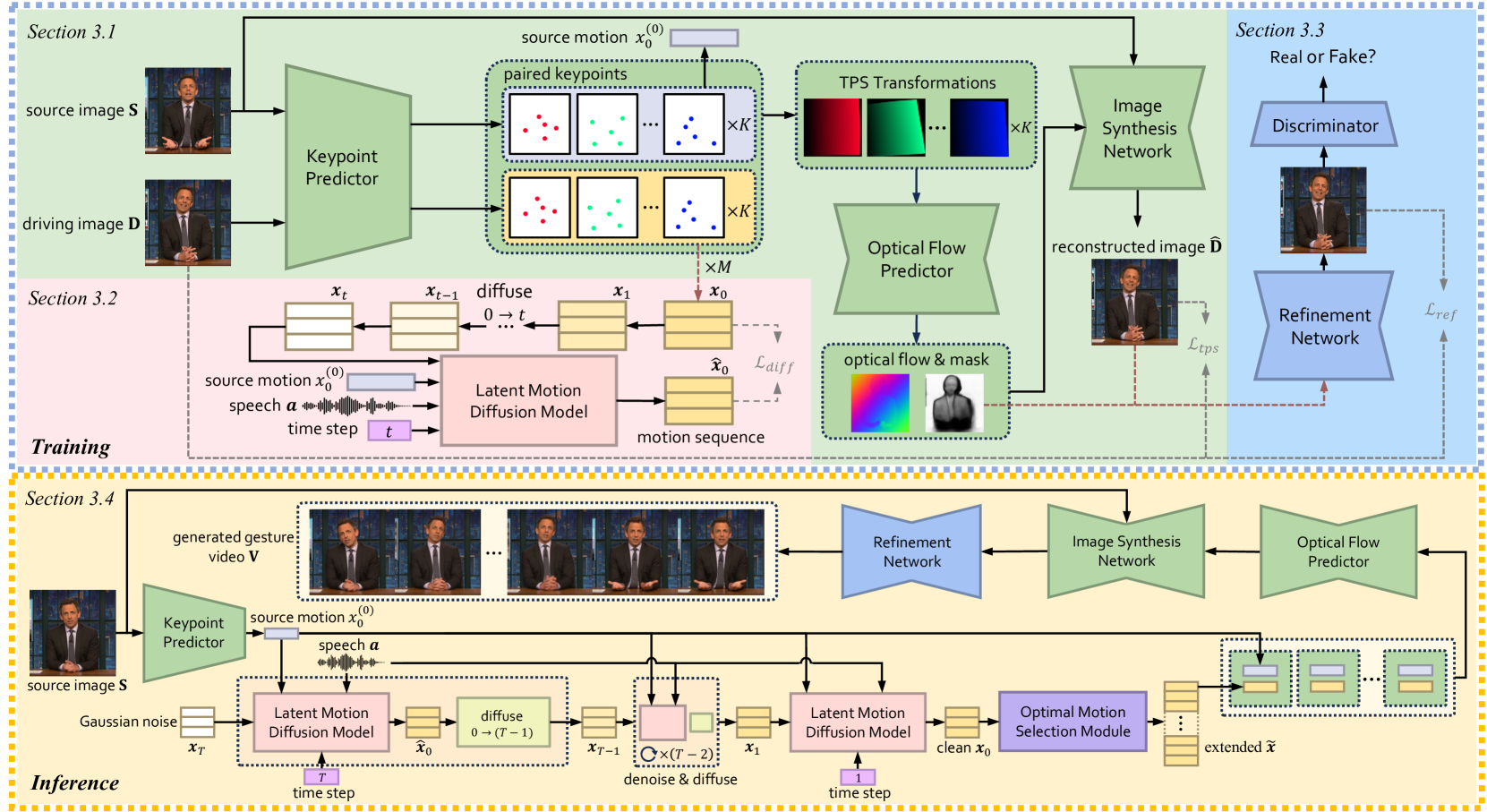
Co-speech gestures, if presented in the lively form of videos, can achieve superior visual effects in human-machine interaction. While previous works mostly generate structural human skeletons, resulting in the omission of appearance information, we focus on the direct generation of audio-driven co-speech gesture videos in this work. There are two main challenges: 1) A suitable motion feature is needed to describe complex human movements with crucial appearance information. 2) Gestures and speech exhibit inherent dependencies and should be temporally aligned even of arbitrary length. To solve these problems, we present a novel motion-decoupled framework to generate co-speech gesture videos. Specifically, we first introduce a well-designed nonlinear TPS transformation to obtain latent motion features preserving essential appearance information. Then a transformer-based diffusion model is proposed to learn the temporal correlation between gestures and speech, and performs generation in the latent motion space, followed by an optimal motion selection module to produce long-term coherent and consistent gesture videos. For better visual perception, we further design a refinement network focusing on missing details of certain areas. Extensive experimental results show that our proposed framework significantly outperforms existing approaches in both motion and video-related evaluations. Our code, demos, and more resources are available at https://github.com/thuhcsi/S2G-MDDiffusion.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a novel method for generating co-speech gesture videos using a motion-decoupled diffusion model.
- The proposed approach separates the generation of body motion and hand gestures, allowing for more natural and expressive animation.
- The model is trained on a large dataset of human speakers and can generate realistic gesture animations that synchronize with given speech.
Plain English Explanation
The researchers have developed a new way to create videos of people making gestures and movements while speaking. Typically, generating these types of animated videos is challenging because the body motions and hand gestures need to be carefully coordinated with the spoken words.
The key insight of this work is to treat the generation of body motion and hand gestures as two separate tasks. By decoupling these two components, the model can generate more natural and expressive animations that sync up better with the audio. The researchers trained their system on a large dataset of real people speaking and gesturing, allowing it to learn the patterns and timing between speech and movement.
When provided with a new audio clip, the model can then produce a corresponding video of a digital character making appropriate gestures and motions. This could be useful for creating more lifelike animations in video games, films, virtual assistants, and other applications where human-like movement is important.
Technical Explanation
The proposed approach utilizes a diffusion model architecture that is decoupled into separate components for body motion and hand gestures. The body motion model takes the speech audio as input and generates a sequence of full-body poses, while the hand gesture model generates the hand shapes and movements.
These two generation processes are trained independently but are coordinated through the use of shared latent representations. This allows the hand gestures to be conditioned on the body motions, ensuring the final animation is coherent and synchronized with the speech.
The researchers collected a large dataset of videos showing people speaking and gesturing, which was used to train the diffusion models. Extensive experiments demonstrated that the motion-decoupled approach outperforms prior gesture generation methods in terms of realism and alignment with the audio.
Critical Analysis
The paper provides a thorough technical explanation of the proposed architecture and its training process. The results show that the decoupled generation of body motion and hand gestures can indeed lead to more natural-looking animations compared to prior work.
One limitation mentioned is that the current model does not take into account the semantic meaning of the speech, which could further improve the expressiveness and relevance of the generated gestures. Additionally, the dataset used for training was limited to a single speaker, so further research would be needed to assess the generalization capabilities of the approach.
It would also be interesting to see how this framework could be extended to generate full-body motions beyond just the hands and arms, such as facial expressions and whole-body posture changes. Incorporating such elements could make the animated characters even more lifelike and compelling.
Overall, this work presents a promising step forward in the field of expressive gesture generation for virtual avatars and animations. The motion-decoupled diffusion model offers a novel and effective solution to a challenging problem in computer graphics and animation.
Conclusion
The paper introduces a new method for generating co-speech gesture videos using a diffusion model architecture that separates the generation of body motion and hand gestures. This decoupled approach allows the system to produce more natural and synchronized animations that closely match the input speech audio.
The technical details and experimental results demonstrate the effectiveness of this novel framework, which could have significant applications in areas like virtual assistants, film/game production, and human-robot interaction where realistic human-like movement is crucial. While there are some limitations to address, this work represents an important advance in the state-of-the-art for expressive gesture generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
Audio is all in one: speech-driven gesture synthetics using WavLM pre-trained model
Fan Zhang, Naye Ji, Fuxing Gao, Siyuan Zhao, Zhaohan Wang, Shunman Li
0
0
The generation of co-speech gestures for digital humans is an emerging area in the field of virtual human creation. Prior research has made progress by using acoustic and semantic information as input and adopting classify method to identify the person's ID and emotion for driving co-speech gesture generation. However, this endeavour still faces significant challenges. These challenges go beyond the intricate interplay between co-speech gestures, speech acoustic, and semantics; they also encompass the complexities associated with personality, emotion, and other obscure but important factors. This paper introduces diffmotion-v2, a speech-conditional diffusion-based and non-autoregressive transformer-based generative model with WavLM pre-trained model. It can produce individual and stylized full-body co-speech gestures only using raw speech audio, eliminating the need for complex multimodal processing and manually annotated. Firstly, considering that speech audio not only contains acoustic and semantic features but also conveys personality traits, emotions, and more subtle information related to accompanying gestures, we pioneer the adaptation of WavLM, a large-scale pre-trained model, to extract low-level and high-level audio information. Secondly, we introduce an adaptive layer norm architecture in the transformer-based layer to learn the relationship between speech information and accompanying gestures. Extensive subjective evaluation experiments are conducted on the Trinity, ZEGGS, and BEAT datasets to confirm the WavLM and the model's ability to synthesize natural co-speech gestures with various styles.
4/16/2024
🗣️
Bridge to Non-Barrier Communication: Gloss-Prompted Fine-grained Cued Speech Gesture Generation with Diffusion Model
Wentao Lei, Li Liu, Jun Wang
0
0
Cued Speech (CS) is an advanced visual phonetic encoding system that integrates lip reading with hand codings, enabling people with hearing impairments to communicate efficiently. CS video generation aims to produce specific lip and gesture movements of CS from audio or text inputs. The main challenge is that given limited CS data, we strive to simultaneously generate fine-grained hand and finger movements, as well as lip movements, meanwhile the two kinds of movements need to be asynchronously aligned. Existing CS generation methods are fragile and prone to poor performance due to template-based statistical models and careful hand-crafted pre-processing to fit the models. Therefore, we propose a novel Gloss-prompted Diffusion-based CS Gesture generation framework (called GlossDiff). Specifically, to integrate additional linguistic rules knowledge into the model. we first introduce a bridging instruction called textbf{Gloss}, which is an automatically generated descriptive text to establish a direct and more delicate semantic connection between spoken language and CS gestures. Moreover, we first suggest rhythm is an important paralinguistic feature for CS to improve the communication efficacy. Therefore, we propose a novel Audio-driven Rhythmic Module (ARM) to learn rhythm that matches audio speech. Moreover, in this work, we design, record, and publish the first Chinese CS dataset with four CS cuers. Extensive experiments demonstrate that our method quantitatively and qualitatively outperforms current state-of-the-art (SOTA) methods. We release the code and data at https://glossdiff.github.io/.
5/1/2024

A Unified Editing Method for Co-Speech Gesture Generation via Diffusion Inversion
Zeyu Zhao, Nan Gao, Zhi Zeng, Guixuan Zhang, Jie Liu, Shuwu Zhang
0
0
Diffusion models have shown great success in generating high-quality co-speech gestures for interactive humanoid robots or digital avatars from noisy input with the speech audio or text as conditions. However, they rarely focus on providing rich editing capabilities for content creators other than high-level specialized measures like style conditioning. To resolve this, we propose a unified framework utilizing diffusion inversion that enables multi-level editing capabilities for co-speech gesture generation without re-training. The method takes advantage of two key capabilities of invertible diffusion models. The first is that through inversion, we can reconstruct the intermediate noise from gestures and regenerate new gestures from the noise. This can be used to obtain gestures with high-level similarities to the original gestures for different speech conditions. The second is that this reconstruction reduces activation caching requirements during gradient calculation, making the direct optimization on input noises possible on current hardware with limited memory. With different loss functions designed for, e.g., joint rotation or velocity, we can control various low-level details by automatically tweaking the input noises through optimization. Extensive experiments on multiple use cases show that this framework succeeds in unifying high-level and low-level co-speech gesture editing.
4/4/2024
Towards Variable and Coordinated Holistic Co-Speech Motion Generation
Yifei Liu, Qiong Cao, Yandong Wen, Huaiguang Jiang, Changxing Ding
0
0
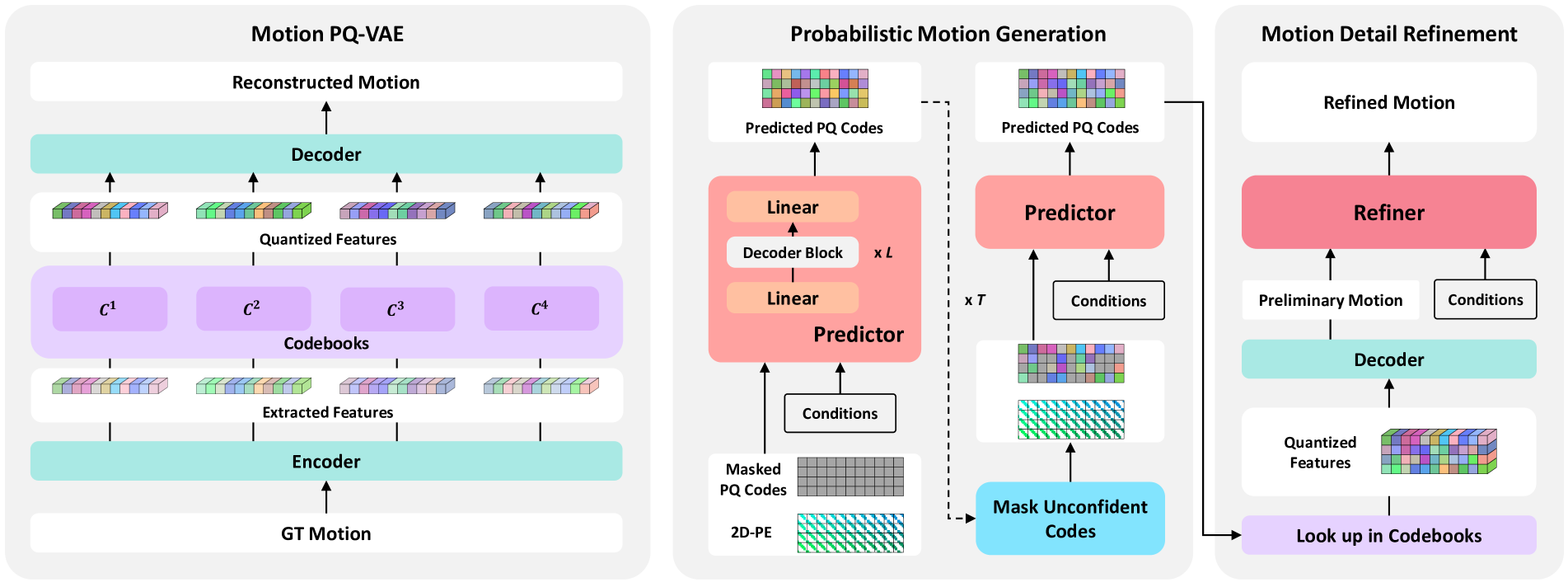
This paper addresses the problem of generating lifelike holistic co-speech motions for 3D avatars, focusing on two key aspects: variability and coordination. Variability allows the avatar to exhibit a wide range of motions even with similar speech content, while coordination ensures a harmonious alignment among facial expressions, hand gestures, and body poses. We aim to achieve both with ProbTalk, a unified probabilistic framework designed to jointly model facial, hand, and body movements in speech. ProbTalk builds on the variational autoencoder (VAE) architecture and incorporates three core designs. First, we introduce product quantization (PQ) to the VAE, which enriches the representation of complex holistic motion. Second, we devise a novel non-autoregressive model that embeds 2D positional encoding into the product-quantized representation, thereby preserving essential structure information of the PQ codes. Last, we employ a secondary stage to refine the preliminary prediction, further sharpening the high-frequency details. Coupling these three designs enables ProbTalk to generate natural and diverse holistic co-speech motions, outperforming several state-of-the-art methods in qualitative and quantitative evaluations, particularly in terms of realism. Our code and model will be released for research purposes at https://feifeifeiliu.github.io/probtalk/.
4/16/2024