Towards Variable and Coordinated Holistic Co-Speech Motion Generation
2404.00368
0
0
Abstract
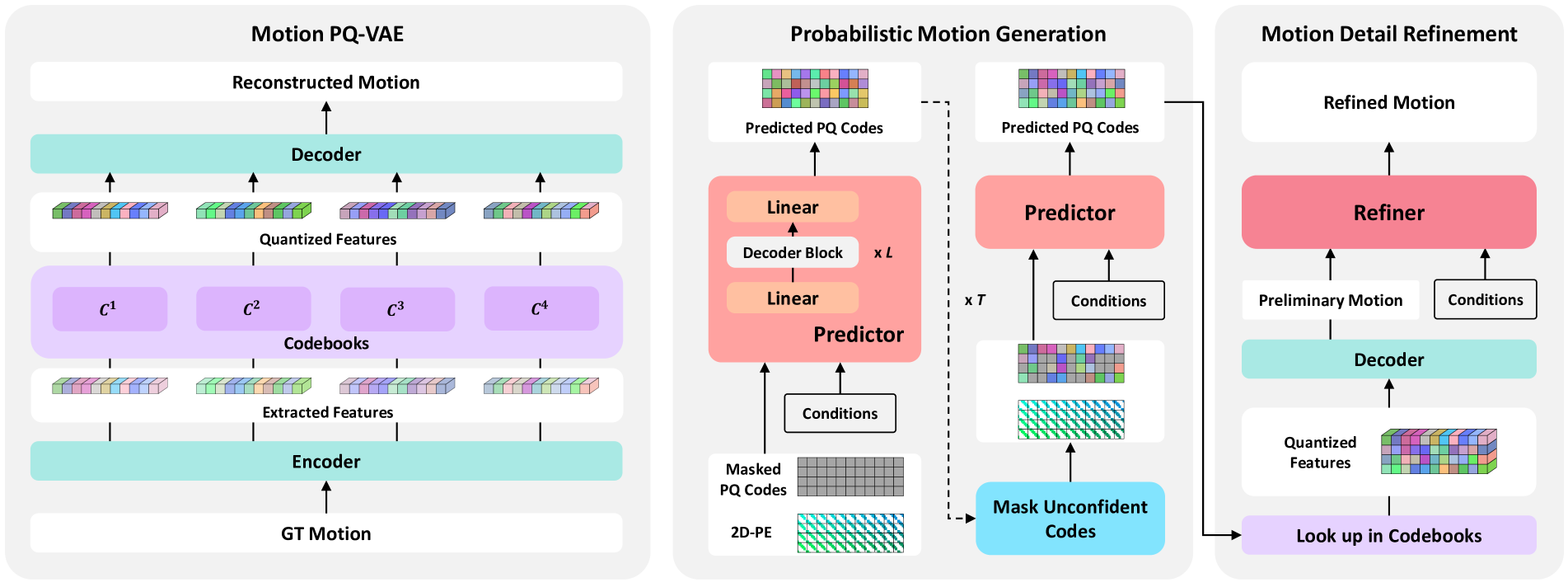
This paper addresses the problem of generating lifelike holistic co-speech motions for 3D avatars, focusing on two key aspects: variability and coordination. Variability allows the avatar to exhibit a wide range of motions even with similar speech content, while coordination ensures a harmonious alignment among facial expressions, hand gestures, and body poses. We aim to achieve both with ProbTalk, a unified probabilistic framework designed to jointly model facial, hand, and body movements in speech. ProbTalk builds on the variational autoencoder (VAE) architecture and incorporates three core designs. First, we introduce product quantization (PQ) to the VAE, which enriches the representation of complex holistic motion. Second, we devise a novel non-autoregressive model that embeds 2D positional encoding into the product-quantized representation, thereby preserving essential structure information of the PQ codes. Last, we employ a secondary stage to refine the preliminary prediction, further sharpening the high-frequency details. Coupling these three designs enables ProbTalk to generate natural and diverse holistic co-speech motions, outperforming several state-of-the-art methods in qualitative and quantitative evaluations, particularly in terms of realism. Our code and model will be released for research purposes at https://feifeifeiliu.github.io/probtalk/.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a novel approach to generating coordinated and variable co-speech motion for virtual characters.
- The method aims to produce more natural and realistic motions that are synchronized with speech.
- The research explores techniques for generating diverse and expressive non-verbal behaviors that enhance the realism of virtual characters.
Plain English Explanation
This paper describes a new way to create animated virtual characters that move and gesture in a more natural and lifelike way when they speak. The researchers developed a system that can generate a wide range of different movements and body language that match up with the speech being delivered.
The goal is to make virtual characters, such as those found in video games, movies, or virtual assistants, appear more human-like and engaging when they interact with users. By using this approach, the characters can perform a diverse set of coordinated motions that feel spontaneous and in sync with their speech, rather than looking stiff or unnatural.
The key innovation is the ability to generate variable and expressive non-verbal behaviors that complement the character's speech in a coherent way. This helps to create more realistic and immersive virtual experiences.
Technical Explanation
The paper proposes a new framework for generating co-speech motion that aims to produce more natural and varied movements synchronized with speech. The approach uses a multi-stage neural network architecture that first extracts relevant features from the speech input, then generates a sequence of full-body motion that corresponds to the speech.
A key innovation is the use of a hierarchical representation that models the coordination between different body parts, allowing for more coherent and realistic motion. The system also incorporates techniques to increase the diversity of the generated motions, such as leveraging latent space sampling and adversarial training.
The researchers evaluate their approach on several public datasets and demonstrate that it outperforms previous state-of-the-art methods in terms of motion quality, expressiveness, and synchronization with speech.
Critical Analysis
The paper presents a promising approach to generating more natural and coordinated co-speech motion for virtual characters. The ability to produce diverse and expressive non-verbal behaviors that are synchronized with speech is an important advancement in creating more realistic and engaging virtual interactions.
However, the paper does not fully address some potential limitations of the approach. For example, the system may struggle to generalize to highly emotional or exaggerated speaking styles, which require even more sophisticated motion modeling. Additionally, the paper does not explore the impact of this technology on the user experience or potential societal implications of more lifelike virtual characters.
Further research is needed to understand the broader applications and limitations of this technology, as well as how it can be responsibly deployed to enhance virtual interactions while maintaining appropriate boundaries and safeguards.
Conclusion
This paper presents a novel framework for generating coordinated and variable co-speech motion for virtual characters. By modeling the hierarchical relationships between different body parts and leveraging techniques to increase motion diversity, the system can produce more natural and expressive non-verbal behaviors that are tightly synchronized with speech.
This advancement has the potential to significantly improve the realism and engagement of virtual characters in a wide range of applications, from video games and movies to virtual assistants and remote collaboration tools. As the technology continues to evolve, it will be important to carefully consider the societal implications and ensure that it is deployed in a responsible and ethical manner.
Related Papers
Co-Speech Gesture Video Generation via Motion-Decoupled Diffusion Model
Xu He, Qiaochu Huang, Zhensong Zhang, Zhiwei Lin, Zhiyong Wu, Sicheng Yang, Minglei Li, Zhiyi Chen, Songcen Xu, Xiaofei Wu
0
0
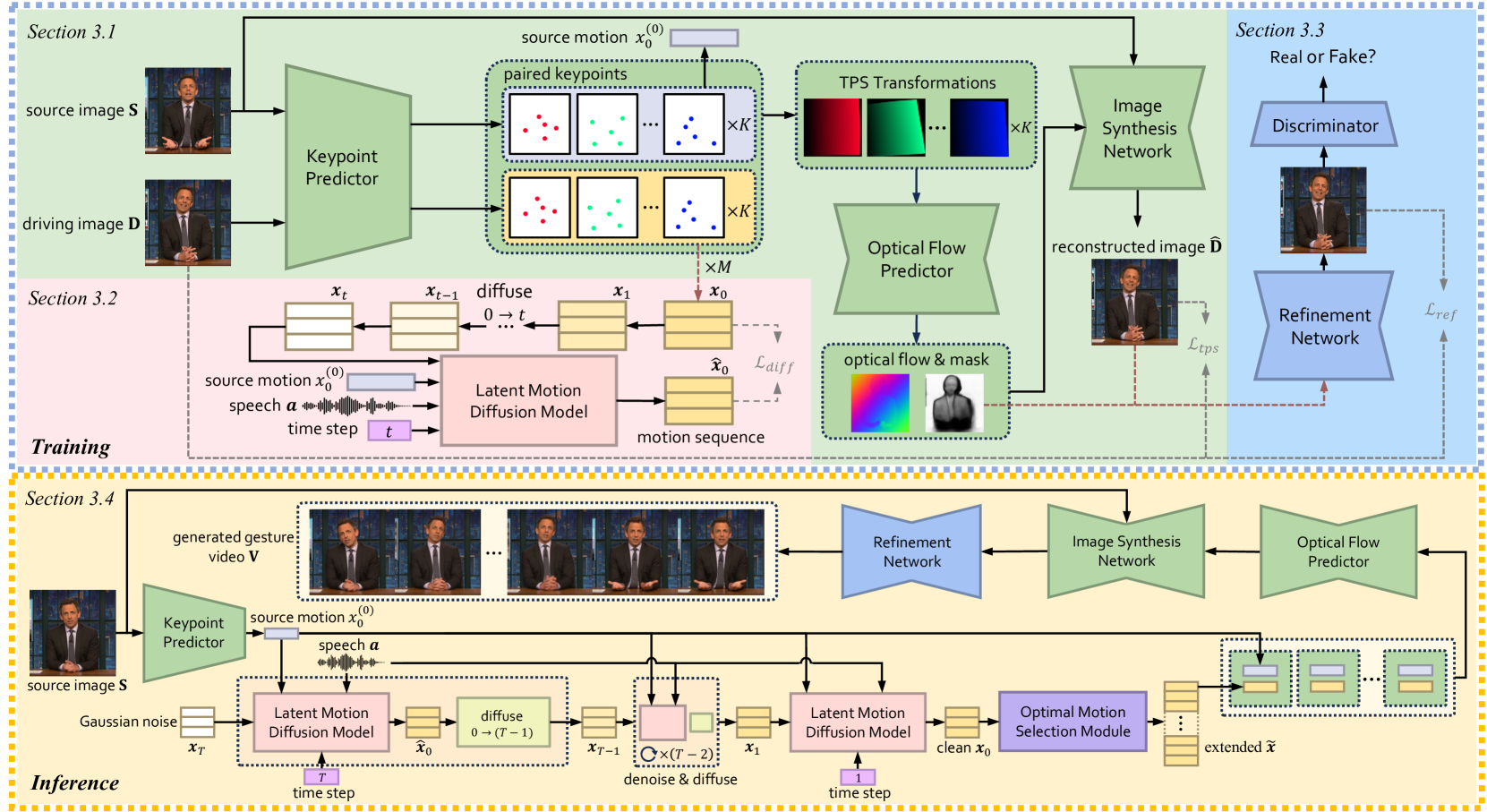
Co-speech gestures, if presented in the lively form of videos, can achieve superior visual effects in human-machine interaction. While previous works mostly generate structural human skeletons, resulting in the omission of appearance information, we focus on the direct generation of audio-driven co-speech gesture videos in this work. There are two main challenges: 1) A suitable motion feature is needed to describe complex human movements with crucial appearance information. 2) Gestures and speech exhibit inherent dependencies and should be temporally aligned even of arbitrary length. To solve these problems, we present a novel motion-decoupled framework to generate co-speech gesture videos. Specifically, we first introduce a well-designed nonlinear TPS transformation to obtain latent motion features preserving essential appearance information. Then a transformer-based diffusion model is proposed to learn the temporal correlation between gestures and speech, and performs generation in the latent motion space, followed by an optimal motion selection module to produce long-term coherent and consistent gesture videos. For better visual perception, we further design a refinement network focusing on missing details of certain areas. Extensive experimental results show that our proposed framework significantly outperforms existing approaches in both motion and video-related evaluations. Our code, demos, and more resources are available at https://github.com/thuhcsi/S2G-MDDiffusion.
4/3/2024
👨🏫
CSTalk: Correlation Supervised Speech-driven 3D Emotional Facial Animation Generation
Xiangyu Liang, Wenlin Zhuang, Tianyong Wang, Guangxing Geng, Guangyue Geng, Haifeng Xia, Siyu Xia
0
0
Speech-driven 3D facial animation technology has been developed for years, but its practical application still lacks expectations. The main challenges lie in data limitations, lip alignment, and the naturalness of facial expressions. Although lip alignment has seen many related studies, existing methods struggle to synthesize natural and realistic expressions, resulting in a mechanical and stiff appearance of facial animations. Even with some research extracting emotional features from speech, the randomness of facial movements limits the effective expression of emotions. To address this issue, this paper proposes a method called CSTalk (Correlation Supervised) that models the correlations among different regions of facial movements and supervises the training of the generative model to generate realistic expressions that conform to human facial motion patterns. To generate more intricate animations, we employ a rich set of control parameters based on the metahuman character model and capture a dataset for five different emotions. We train a generative network using an autoencoder structure and input an emotion embedding vector to achieve the generation of user-control expressions. Experimental results demonstrate that our method outperforms existing state-of-the-art methods.
4/30/2024
📈
Audio is all in one: speech-driven gesture synthetics using WavLM pre-trained model
Fan Zhang, Naye Ji, Fuxing Gao, Siyuan Zhao, Zhaohan Wang, Shunman Li
0
0
The generation of co-speech gestures for digital humans is an emerging area in the field of virtual human creation. Prior research has made progress by using acoustic and semantic information as input and adopting classify method to identify the person's ID and emotion for driving co-speech gesture generation. However, this endeavour still faces significant challenges. These challenges go beyond the intricate interplay between co-speech gestures, speech acoustic, and semantics; they also encompass the complexities associated with personality, emotion, and other obscure but important factors. This paper introduces diffmotion-v2, a speech-conditional diffusion-based and non-autoregressive transformer-based generative model with WavLM pre-trained model. It can produce individual and stylized full-body co-speech gestures only using raw speech audio, eliminating the need for complex multimodal processing and manually annotated. Firstly, considering that speech audio not only contains acoustic and semantic features but also conveys personality traits, emotions, and more subtle information related to accompanying gestures, we pioneer the adaptation of WavLM, a large-scale pre-trained model, to extract low-level and high-level audio information. Secondly, we introduce an adaptive layer norm architecture in the transformer-based layer to learn the relationship between speech information and accompanying gestures. Extensive subjective evaluation experiments are conducted on the Trinity, ZEGGS, and BEAT datasets to confirm the WavLM and the model's ability to synthesize natural co-speech gestures with various styles.
4/16/2024
FlowVQTalker: High-Quality Emotional Talking Face Generation through Normalizing Flow and Quantization
Shuai Tan, Bin Ji, Ye Pan
0
0
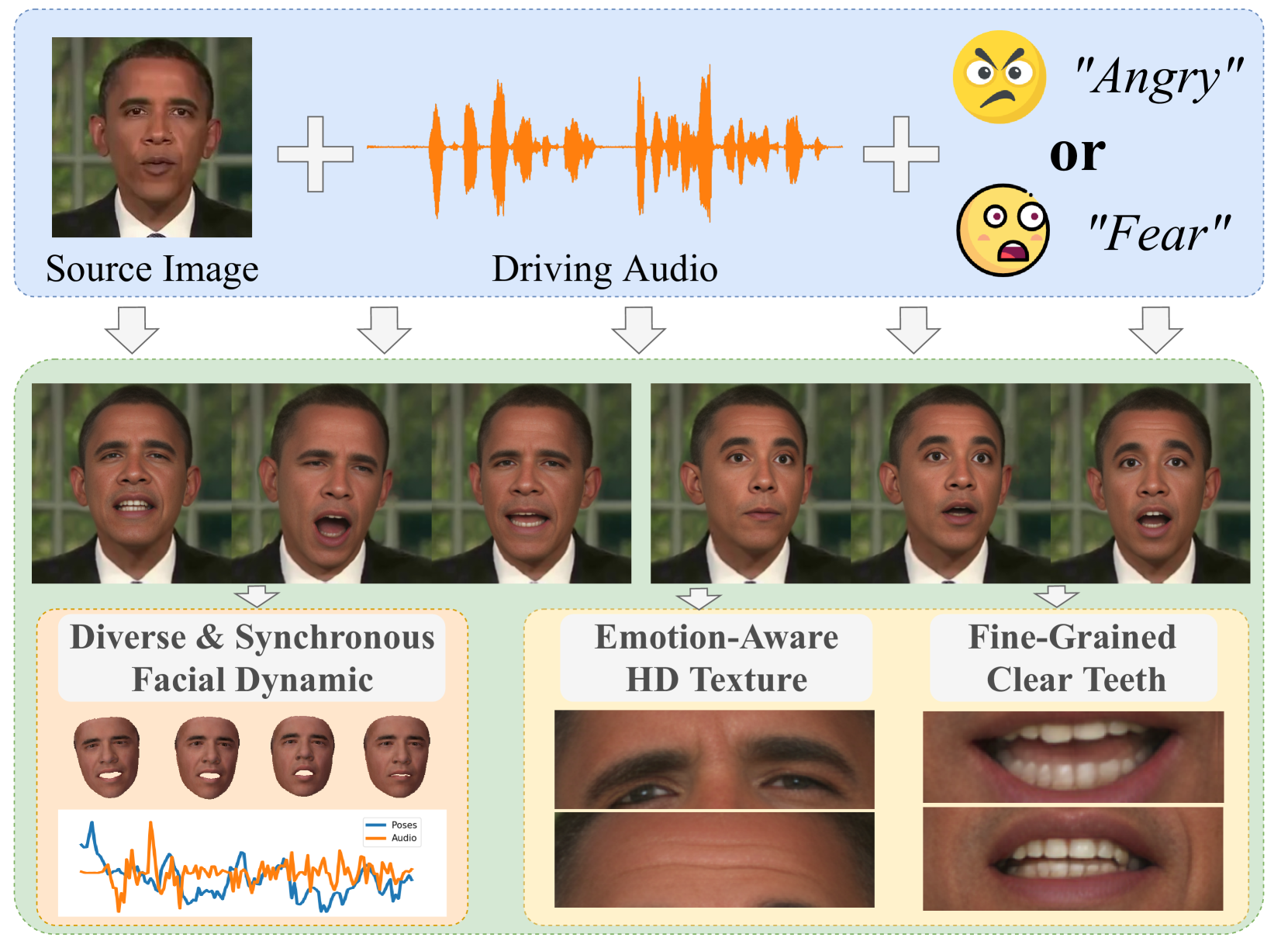
Generating emotional talking faces is a practical yet challenging endeavor. To create a lifelike avatar, we draw upon two critical insights from a human perspective: 1) The connection between audio and the non-deterministic facial dynamics, encompassing expressions, blinks, poses, should exhibit synchronous and one-to-many mapping. 2) Vibrant expressions are often accompanied by emotion-aware high-definition (HD) textures and finely detailed teeth. However, both aspects are frequently overlooked by existing methods. To this end, this paper proposes using normalizing Flow and Vector-Quantization modeling to produce emotional talking faces that satisfy both insights concurrently (FlowVQTalker). Specifically, we develop a flow-based coefficient generator that encodes the dynamics of facial emotion into a multi-emotion-class latent space represented as a mixture distribution. The generation process commences with random sampling from the modeled distribution, guided by the accompanying audio, enabling both lip-synchronization and the uncertain nonverbal facial cues generation. Furthermore, our designed vector-quantization image generator treats the creation of expressive facial images as a code query task, utilizing a learned codebook to provide rich, high-quality textures that enhance the emotional perception of the results. Extensive experiments are conducted to showcase the effectiveness of our approach.
4/24/2024