Coalitions of Large Language Models Increase the Robustness of AI Agents

0

Sign in to get full access
Overview
- Large language models (LLMs) are powerful AI systems that can perform a wide range of natural language tasks.
- This paper explores the use of coalitions of LLMs to increase the robustness and reliability of AI agents.
- The researchers demonstrate that combining multiple LLMs can enhance an agent's performance and make it more resistant to adversarial attacks or other failures.
Plain English Explanation
The paper discusses the idea of using coalitions of large language models to make AI agents more robust and reliable. Large language models (LLMs) are extremely capable AI systems that can perform a variety of language-related tasks, such as answering questions, generating text, and even understanding complex concepts.
The researchers hypothesized that by combining multiple LLMs, they could create AI agents that are more resistant to failures or adversarial attacks. The key idea is that if one LLM in the coalition makes a mistake or produces an unreliable output, the other LLMs in the coalition can "check" and "correct" the agent's behavior, helping to maintain its overall performance and reliability.
The researchers conducted experiments to test this hypothesis, and their results showed that AI agents powered by coalitions of LLMs were indeed more robust and less susceptible to various types of failures or attacks. This suggests that this approach could be a promising way to build more reliable and trustworthy AI systems in the future.
Technical Explanation
The paper presents a novel approach to enhancing the robustness of AI agents by leveraging coalitions of large language models. The researchers hypothesized that combining multiple LLMs could make AI agents more resistant to adversarial attacks, model failures, or other types of errors.
To test this hypothesis, the researchers designed a series of experiments in which they created AI agents powered by either a single LLM or a coalition of multiple LLMs. They then subjected these agents to various challenges, such as adversarial attacks or the introduction of noise or errors into the input data.
The results of the experiments showed that the AI agents powered by coalitions of LLMs consistently outperformed those relying on a single LLM. The coalition-based agents were more robust to adversarial attacks, more accurate in their responses, and less susceptible to catastrophic failures when faced with unexpected or corrupted inputs.
The researchers attribute this improved performance to the inherent diversity and complementarity of the LLMs within the coalition. When one LLM in the coalition produces an unreliable or erroneous output, the other LLMs can "cross-check" and "correct" it, ensuring the overall agent behavior remains stable and reliable.
Critical Analysis
The paper presents a thoughtful and well-designed study on the potential benefits of using coalitions of large language models to enhance the robustness of AI agents. The researchers have articulated a clear hypothesis and conducted a comprehensive set of experiments to test it, providing evidence to support their claims.
However, the paper does not address some potential limitations or caveats of this approach. For example, the researchers do not discuss the computational and resource requirements of maintaining and coordinating a coalition of LLMs, which could be a significant practical challenge, especially for resource-constrained applications.
Additionally, the paper does not explore the potential for emergent behaviors or unintended consequences that could arise from the interaction of multiple LLMs within a coalition. As these systems become more complex, it will be important to carefully study and monitor their behaviors to ensure they remain safe and reliable.
Overall, the paper makes a compelling case for the use of LLM coalitions to improve the robustness of AI agents, but further research is needed to fully understand the implications and limitations of this approach.
Conclusion
This paper presents a novel approach to enhancing the robustness and reliability of AI agents by leveraging coalitions of large language models. The researchers have demonstrated that combining multiple LLMs can make AI agents more resistant to adversarial attacks, model failures, and other challenges, potentially paving the way for the development of more trustworthy and reliable AI systems.
While the paper provides strong evidence to support the benefits of this approach, it also highlights the need for further research to address potential practical and technical challenges. As the field of AI continues to evolve, understanding how to build robust and dependable systems will be crucial for ensuring the safe and ethical deployment of these technologies in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Coalitions of Large Language Models Increase the Robustness of AI Agents
Prattyush Mangal, Carol Mak, Theo Kanakis, Timothy Donovan, Dave Braines, Edward Pyzer-Knapp
The emergence of Large Language Models (LLMs) have fundamentally altered the way we interact with digital systems and have led to the pursuit of LLM powered AI agents to assist in daily workflows. LLMs, whilst powerful and capable of demonstrating some emergent properties, are not logical reasoners and often struggle to perform well at all sub-tasks carried out by an AI agent to plan and execute a workflow. While existing studies tackle this lack of proficiency by generalised pretraining at a huge scale or by specialised fine-tuning for tool use, we assess if a system comprising of a coalition of pretrained LLMs, each exhibiting specialised performance at individual sub-tasks, can match the performance of single model agents. The coalition of models approach showcases its potential for building robustness and reducing the operational costs of these AI agents by leveraging traits exhibited by specific models. Our findings demonstrate that fine-tuning can be mitigated by considering a coalition of pretrained models and believe that this approach can be applied to other non-agentic systems which utilise LLMs.
Read more8/6/2024
0
Exploring Autonomous Agents through the Lens of Large Language Models: A Review
Saikat Barua
Large Language Models (LLMs) are transforming artificial intelligence, enabling autonomous agents to perform diverse tasks across various domains. These agents, proficient in human-like text comprehension and generation, have the potential to revolutionize sectors from customer service to healthcare. However, they face challenges such as multimodality, human value alignment, hallucinations, and evaluation. Techniques like prompting, reasoning, tool utilization, and in-context learning are being explored to enhance their capabilities. Evaluation platforms like AgentBench, WebArena, and ToolLLM provide robust methods for assessing these agents in complex scenarios. These advancements are leading to the development of more resilient and capable autonomous agents, anticipated to become integral in our digital lives, assisting in tasks from email responses to disease diagnosis. The future of AI, with LLMs at the forefront, is promising.
Read more4/9/2024
💬
0
Apprentices to Research Assistants: Advancing Research with Large Language Models
M. Namvarpour, A. Razi
Large Language Models (LLMs) have emerged as powerful tools in various research domains. This article examines their potential through a literature review and firsthand experimentation. While LLMs offer benefits like cost-effectiveness and efficiency, challenges such as prompt tuning, biases, and subjectivity must be addressed. The study presents insights from experiments utilizing LLMs for qualitative analysis, highlighting successes and limitations. Additionally, it discusses strategies for mitigating challenges, such as prompt optimization techniques and leveraging human expertise. This study aligns with the 'LLMs as Research Tools' workshop's focus on integrating LLMs into HCI data work critically and ethically. By addressing both opportunities and challenges, our work contributes to the ongoing dialogue on their responsible application in research.
Read more4/10/2024
0
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
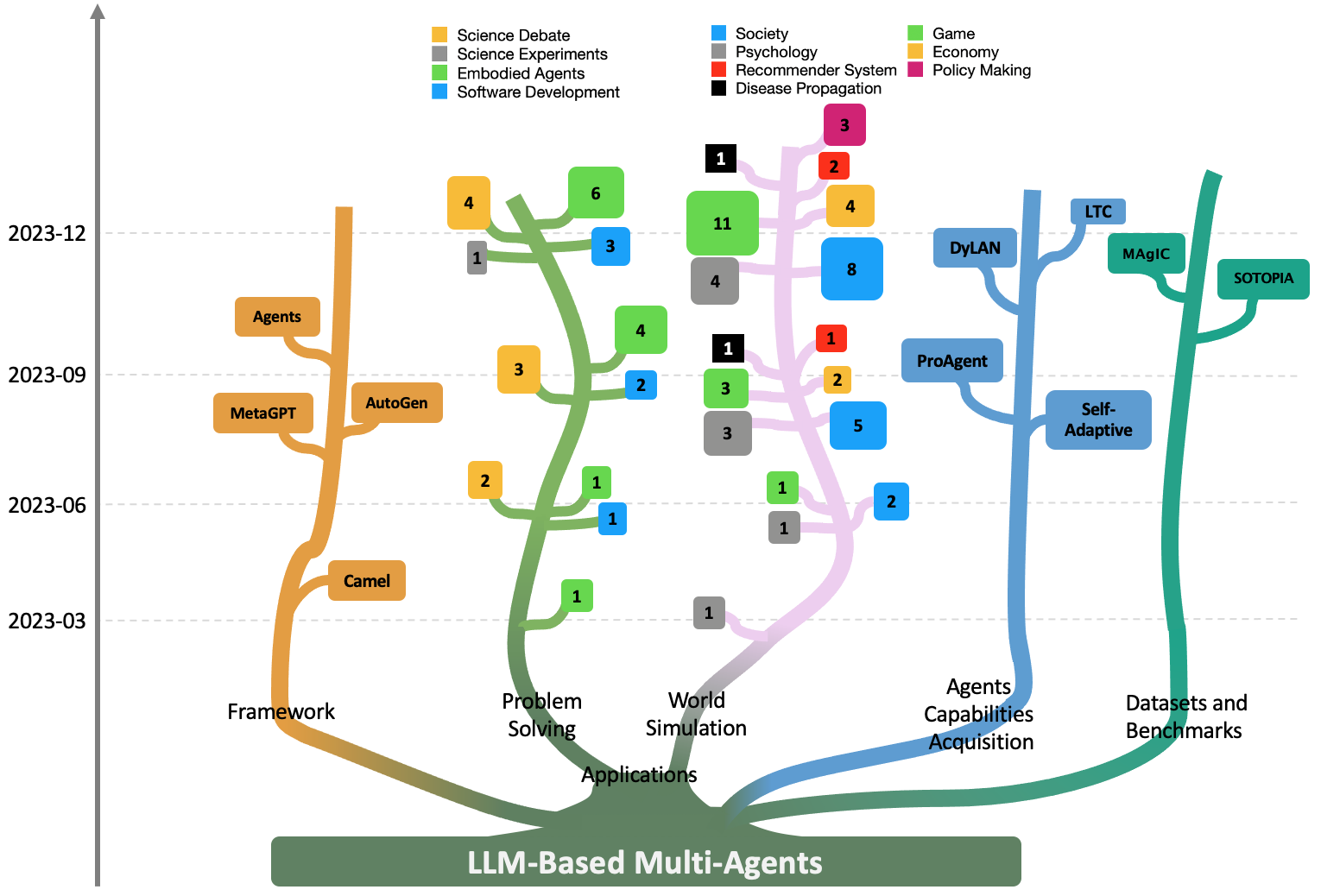
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V. Chawla, Olaf Wiest, Xiangliang Zhang
Large Language Models (LLMs) have achieved remarkable success across a wide array of tasks. Due to the impressive planning and reasoning abilities of LLMs, they have been used as autonomous agents to do many tasks automatically. Recently, based on the development of using one LLM as a single planning or decision-making agent, LLM-based multi-agent systems have achieved considerable progress in complex problem-solving and world simulation. To provide the community with an overview of this dynamic field, we present this survey to offer an in-depth discussion on the essential aspects of multi-agent systems based on LLMs, as well as the challenges. Our goal is for readers to gain substantial insights on the following questions: What domains and environments do LLM-based multi-agents simulate? How are these agents profiled and how do they communicate? What mechanisms contribute to the growth of agents' capacities? For those interested in delving into this field of study, we also summarize the commonly used datasets or benchmarks for them to have convenient access. To keep researchers updated on the latest studies, we maintain an open-source GitHub repository, dedicated to outlining the research on LLM-based multi-agent systems.
Read more4/22/2024