Coarse-Fine View Attention Alignment-Based GAN for CT Reconstruction from Biplanar X-Rays

0
Sign in to get full access
Overview
- Presents a Coarse-Fine View Attention Alignment-Based Generative Adversarial Network (CVAA-GAN) for reconstructing 3D CT images from biplanar X-ray images
- Key innovations include a coarse-to-fine view attention alignment module and a generator-discriminator architecture for effective training
- Aims to improve upon existing methods for CT reconstruction from limited-view X-ray data
Plain English Explanation
This paper introduces a new machine learning model called CVAA-GAN that can reconstruct 3D computed tomography (CT) images from just two X-ray images taken from different angles. The core idea is to use an attention-based approach to "align" the information from the two X-ray views, allowing the model to effectively combine them and generate an accurate 3D reconstruction.
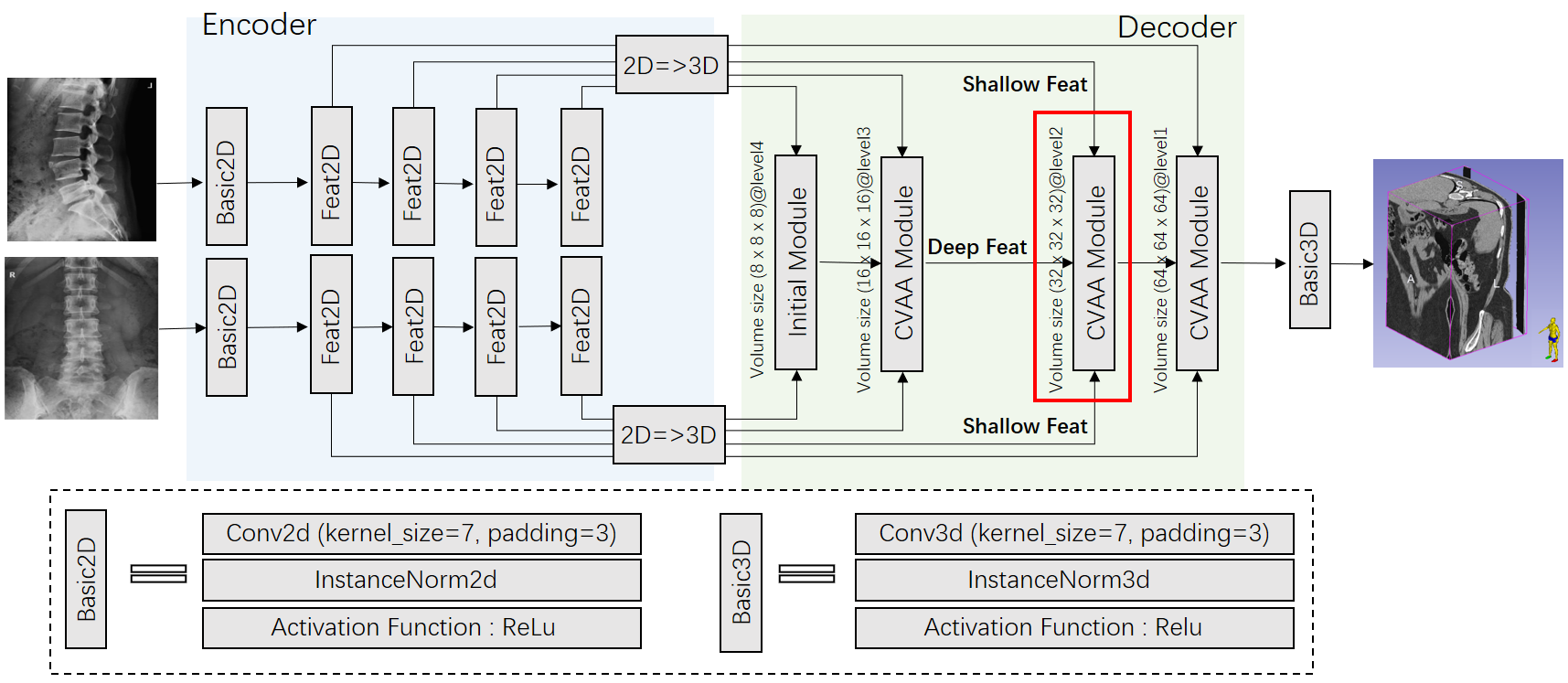
The CVAA-GAN architecture starts by processing the X-ray images at a coarse level to get a rough initial reconstruction. It then refines this coarse reconstruction by focusing the model's attention on the relevant parts of the X-ray images through a "view attention alignment" module. This allows the model to selectively integrate the complementary information from the two views to produce a high-quality 3D CT image.
The key advantage of this approach is that it can generate accurate 3D reconstructions from just two X-ray images, which is much less data than traditional CT scanners require. This could enable faster, cheaper, and more accessible medical imaging in settings where full CT scans are not feasible.
Technical Explanation
The CVAA-GAN consists of a generator network and a discriminator network. The generator takes as input a pair of biplanar X-ray images and outputs a reconstructed 3D CT image.
The core innovation is the coarse-to-fine view attention alignment (CVAA) module within the generator. This module first processes the X-ray images at a coarse level to produce an initial 3D reconstruction. It then refines this coarse output by selectively attending to the relevant regions of the input X-ray images. This allows the model to effectively combine the complementary information from the two views to generate an accurate final 3D CT image.
The discriminator network is trained to distinguish the generator's reconstructions from ground truth CT scans. This adversarial training process encourages the generator to produce reconstructions that are indistinguishable from real CT images, leading to higher quality outputs.
The authors evaluate CVAA-GAN on several medical imaging datasets and show that it outperforms previous state-of-the-art methods for CT reconstruction from biplanar X-rays. The model is able to generate high-fidelity 3D CT images from just two input X-ray views.
Critical Analysis
The CVAA-GAN represents an interesting and promising approach to the challenging problem of 3D CT reconstruction from limited-view 2D X-ray data. However, the paper does not fully address some important limitations and caveats:
- The model was only evaluated on a few specific medical imaging datasets, so its generalization to a wider range of anatomies and imaging conditions is unclear.
- The paper does not provide a detailed analysis of the model's failure cases or limitations, which would be important for understanding its practical applicability.
- While the CVAA module is a clever technical innovation, the overall GAN-based training procedure can be unstable and difficult to optimize in practice.
- The computational and memory requirements of the model are not discussed, which is an important practical consideration for real-world deployment.
Further research is needed to better understand the strengths, weaknesses, and broader applicability of the CVAA-GAN approach. Exploring alternative architectures, training techniques, and evaluation on more diverse datasets could help strengthen the contribution of this work.
Conclusion
The CVAA-GAN presents a novel deep learning-based approach for reconstructing 3D CT images from just two input X-ray views. By introducing a coarse-to-fine view attention alignment module, the model is able to effectively combine the complementary information from the biplanar X-rays to generate high-quality 3D reconstructions.
This work has important implications for improving the accessibility and efficiency of medical imaging, as it could enable 3D CT scans to be obtained using much less data than traditional methods. Further development and real-world deployment of CVAA-GAN could lead to significant benefits for healthcare, such as faster diagnoses, reduced radiation exposure, and expanded access to advanced imaging capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Coarse-Fine View Attention Alignment-Based GAN for CT Reconstruction from Biplanar X-Rays
Zhi Qiao, Hanqiang Ouyang, Dongheng Chu, Huishu Yuan, Xiantong Zhen, Pei Dong, Zhen Qian
For surgical planning and intra-operation imaging, CT reconstruction using X-ray images can potentially be an important alternative when CT imaging is not available or not feasible. In this paper, we aim to use biplanar X-rays to reconstruct a 3D CT image, because biplanar X-rays convey richer information than single-view X-rays and are more commonly used by surgeons. Different from previous studies in which the two X-ray views were treated indifferently when fusing the cross-view data, we propose a novel attention-informed coarse-to-fine cross-view fusion method to combine the features extracted from the orthogonal biplanar views. This method consists of a view attention alignment sub-module and a fine-distillation sub-module that are designed to work together to highlight the unique or complementary information from each of the views. Experiments have demonstrated the superiority of our proposed method over the SOTA methods.
Read more8/20/2024

0
Diff2CT: Diffusion Learning to Reconstruct Spine CT from Biplanar X-Rays
Zhi Qiao, Xuhui Liu, Xiaopeng Wang, Runkun Liu, Xiantong Zhen, Pei Dong, Zhen Qian
Intraoperative CT imaging serves as a crucial resource for surgical guidance; however, it may not always be readily accessible or practical to implement. In scenarios where CT imaging is not an option, reconstructing CT scans from X-rays can offer a viable alternative. In this paper, we introduce an innovative method for 3D CT reconstruction utilizing biplanar X-rays. Distinct from previous research that relies on conventional image generation techniques, our approach leverages a conditional diffusion process to tackle the task of reconstruction. More precisely, we employ a diffusion-based probabilistic model trained to produce 3D CT images based on orthogonal biplanar X-rays. To improve the structural integrity of the reconstructed images, we incorporate a novel projection loss function. Experimental results validate that our proposed method surpasses existing state-of-the-art benchmarks in both visual image quality and multiple evaluative metrics. Specifically, our technique achieves a higher Structural Similarity Index (SSIM) of 0.83, a relative increase of 10%, and a lower Fr'echet Inception Distance (FID) of 83.43, which represents a relative decrease of 25%.
Read more8/22/2024

0
DiffuX2CT: Diffusion Learning to Reconstruct CT Images from Biplanar X-Rays
Xuhui Liu, Zhi Qiao, Runkun Liu, Hong Li, Juan Zhang, Xiantong Zhen, Zhen Qian, Baochang Zhang
Computed tomography (CT) is widely utilized in clinical settings because it delivers detailed 3D images of the human body. However, performing CT scans is not always feasible due to radiation exposure and limitations in certain surgical environments. As an alternative, reconstructing CT images from ultra-sparse X-rays offers a valuable solution and has gained significant interest in scientific research and medical applications. However, it presents great challenges as it is inherently an ill-posed problem, often compromised by artifacts resulting from overlapping structures in X-ray images. In this paper, we propose DiffuX2CT, which models CT reconstruction from orthogonal biplanar X-rays as a conditional diffusion process. DiffuX2CT is established with a 3D global coherence denoising model with a new, implicit conditioning mechanism. We realize the conditioning mechanism by a newly designed tri-plane decoupling generator and an implicit neural decoder. By doing so, DiffuX2CT achieves structure-controllable reconstruction, which enables 3D structural information to be recovered from 2D X-rays, therefore producing faithful textures in CT images. As an extra contribution, we collect a real-world lumbar CT dataset, called LumbarV, as a new benchmark to verify the clinical significance and performance of CT reconstruction from X-rays. Extensive experiments on this dataset and three more publicly available datasets demonstrate the effectiveness of our proposal.
Read more7/19/2024

0
Multi-view X-ray Image Synthesis with Multiple Domain Disentanglement from CT Scans
Lixing Tan, Shuang Song, Kangneng Zhou, Chengbo Duan, Lanying Wang, Huayang Ren, Linlin Liu, Wei Zhang, Ruoxiu Xiao
X-ray images play a vital role in the intraoperative processes due to their high resolution and fast imaging speed and greatly promote the subsequent segmentation, registration and reconstruction. However, over-dosed X-rays superimpose potential risks to human health to some extent. Data-driven algorithms from volume scans to X-ray images are restricted by the scarcity of paired X-ray and volume data. Existing methods are mainly realized by modelling the whole X-ray imaging procedure. In this study, we propose a learning-based approach termed CT2X-GAN to synthesize the X-ray images in an end-to-end manner using the content and style disentanglement from three different image domains. Our method decouples the anatomical structure information from CT scans and style information from unpaired real X-ray images/ digital reconstructed radiography (DRR) images via a series of decoupling encoders. Additionally, we introduce a novel consistency regularization term to improve the stylistic resemblance between synthesized X-ray images and real X-ray images. Meanwhile, we also impose a supervised process by computing the similarity of computed real DRR and synthesized DRR images. We further develop a pose attention module to fully strengthen the comprehensive information in the decoupled content code from CT scans, facilitating high-quality multi-view image synthesis in the lower 2D space. Extensive experiments were conducted on the publicly available CTSpine1K dataset and achieved 97.8350, 0.0842 and 3.0938 in terms of FID, KID and defined user-scored X-ray similarity, respectively. In comparison with 3D-aware methods ($pi$-GAN, EG3D), CT2X-GAN is superior in improving the synthesis quality and realistic to the real X-ray images.
Read more8/1/2024