CodecFake: Enhancing Anti-Spoofing Models Against Deepfake Audios from Codec-Based Speech Synthesis Systems

0

Sign in to get full access
Overview
- This paper proposes a novel anti-spoofing model called "CodecFake" to enhance detection of deepfake audios generated by codec-based speech synthesis systems.
- The authors introduce a new dataset, "CodecFake", which contains real and deepfake audio samples created using various codecs, to train and evaluate their model.
- They show that CodecFake outperforms existing anti-spoofing models in detecting deepfake audios, particularly those generated by codec-based speech synthesis systems.
Plain English Explanation
The paper focuses on developing a new system, called CodecFake, to detect fake audio recordings that were generated using artificial intelligence (AI) techniques, specifically "deepfake" audios. Deepfake audios are created by using AI models to synthesize human-like speech, often by imitating the voice of a real person.
The key innovation in this paper is that the authors recognized a weakness in existing anti-spoofing models - they don't perform as well at detecting deepfake audios that were created using specific audio compression techniques called "codecs". To address this, the researchers created a new dataset called "CodecFake" that contains real and deepfake audio samples generated using various codecs. They then trained their CodecFake model on this dataset and showed that it outperforms other anti-spoofing models at detecting deepfake audios, especially those created with codec-based speech synthesis systems.
This is an important advancement because as deepfake technology becomes more sophisticated, it's crucial to have robust systems that can reliably identify fake audio recordings. The CodecFake model developed in this paper represents a step forward in protecting against the malicious use of deepfake audio, which could be used for things like impersonating real people or spreading misinformation.
Technical Explanation
The authors propose a novel anti-spoofing model called "CodecFake" to enhance detection of deepfake audios generated by codec-based speech synthesis systems. They introduce a new dataset, "CodecFake", which contains real and deepfake audio samples created using various codecs, to train and evaluate their model.
The CodecFake model is designed to capture the unique artifacts introduced by codec-based speech synthesis systems, which existing anti-spoofing models may struggle to detect. The authors use a combination of convolutional neural networks (CNNs) and recurrent neural networks (RNNs) to extract features from the audio samples that are indicative of real or deepfake speech.
Through extensive experiments, the researchers demonstrate that the CodecFake model outperforms state-of-the-art anti-spoofing models, such as MLAAD, Neural Codec-based Adversarial Sample Detection, and SceneFake, in detecting deepfake audios, particularly those generated by codec-based speech synthesis systems. The authors also evaluate the robustness of their model against various attack scenarios, such as noise, compression, and adversarial attacks.
Critical Analysis
The authors have made a compelling case for the need to develop more robust anti-spoofing models that can effectively detect deepfake audios generated by codec-based speech synthesis systems. The introduction of the CodecFake dataset and the demonstration of the CodecFake model's superior performance are valuable contributions to the field of audio anti-spoofing.
However, the paper does not address some potential limitations of the CodecFake model. For instance, it's unclear how well the model would generalize to deepfake audios generated by speech synthesis systems that use different techniques or technologies beyond codec-based methods. Additionally, the authors do not discuss the computational complexity or real-time inference capabilities of the CodecFake model, which could be important factors for practical deployment.
Furthermore, the paper does not explore the potential for adversarial attacks specifically targeting the CodecFake model. As deepfake technology continues to evolve, it's crucial to consider the long-term resiliency of anti-spoofing models against increasingly sophisticated attack strategies.
Conclusion
The CodecFake model proposed in this paper represents a significant advancement in the field of audio anti-spoofing, particularly in the context of detecting deepfake audios generated by codec-based speech synthesis systems. By introducing the CodecFake dataset and demonstrating the superior performance of their model, the authors have made an important contribution to the ongoing efforts to combat the malicious use of deepfake technology.
As deepfake technology continues to evolve, the need for robust and reliable anti-spoofing solutions will only become more pressing. The insights and techniques developed in this paper could serve as a valuable foundation for further research and development in this critical area of study.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CodecFake: Enhancing Anti-Spoofing Models Against Deepfake Audios from Codec-Based Speech Synthesis Systems
Haibin Wu, Yuan Tseng, Hung-yi Lee
Current state-of-the-art (SOTA) codec-based audio synthesis systems can mimic anyone's voice with just a 3-second sample from that specific unseen speaker. Unfortunately, malicious attackers may exploit these technologies, causing misuse and security issues. Anti-spoofing models have been developed to detect fake speech. However, the open question of whether current SOTA anti-spoofing models can effectively counter deepfake audios from codec-based speech synthesis systems remains unanswered. In this paper, we curate an extensive collection of contemporary SOTA codec models, employing them to re-create synthesized speech. This endeavor leads to the creation of CodecFake, the first codec-based deepfake audio dataset. Additionally, we verify that anti-spoofing models trained on commonly used datasets cannot detect synthesized speech from current codec-based speech generation systems. The proposed CodecFake dataset empowers these models to counter this challenge effectively.
Read more6/12/2024
🌀
0
Audio Anti-Spoofing Detection: A Survey
Menglu Li, Yasaman Ahmadiadli, Xiao-Ping Zhang
The availability of smart devices leads to an exponential increase in multimedia content. However, the rapid advancements in deep learning have given rise to sophisticated algorithms capable of manipulating or creating multimedia fake content, known as Deepfake. Audio Deepfakes pose a significant threat by producing highly realistic voices, thus facilitating the spread of misinformation. To address this issue, numerous audio anti-spoofing detection challenges have been organized to foster the development of anti-spoofing countermeasures. This survey paper presents a comprehensive review of every component within the detection pipeline, including algorithm architectures, optimization techniques, application generalizability, evaluation metrics, performance comparisons, available datasets, and open-source availability. For each aspect, we conduct a systematic evaluation of the recent advancements, along with discussions on existing challenges. Additionally, we also explore emerging research topics on audio anti-spoofing, including partial spoofing detection, cross-dataset evaluation, and adversarial attack defence, while proposing some promising research directions for future work. This survey paper not only identifies the current state-of-the-art to establish strong baselines for future experiments but also guides future researchers on a clear path for understanding and enhancing the audio anti-spoofing detection mechanisms.
Read more4/23/2024
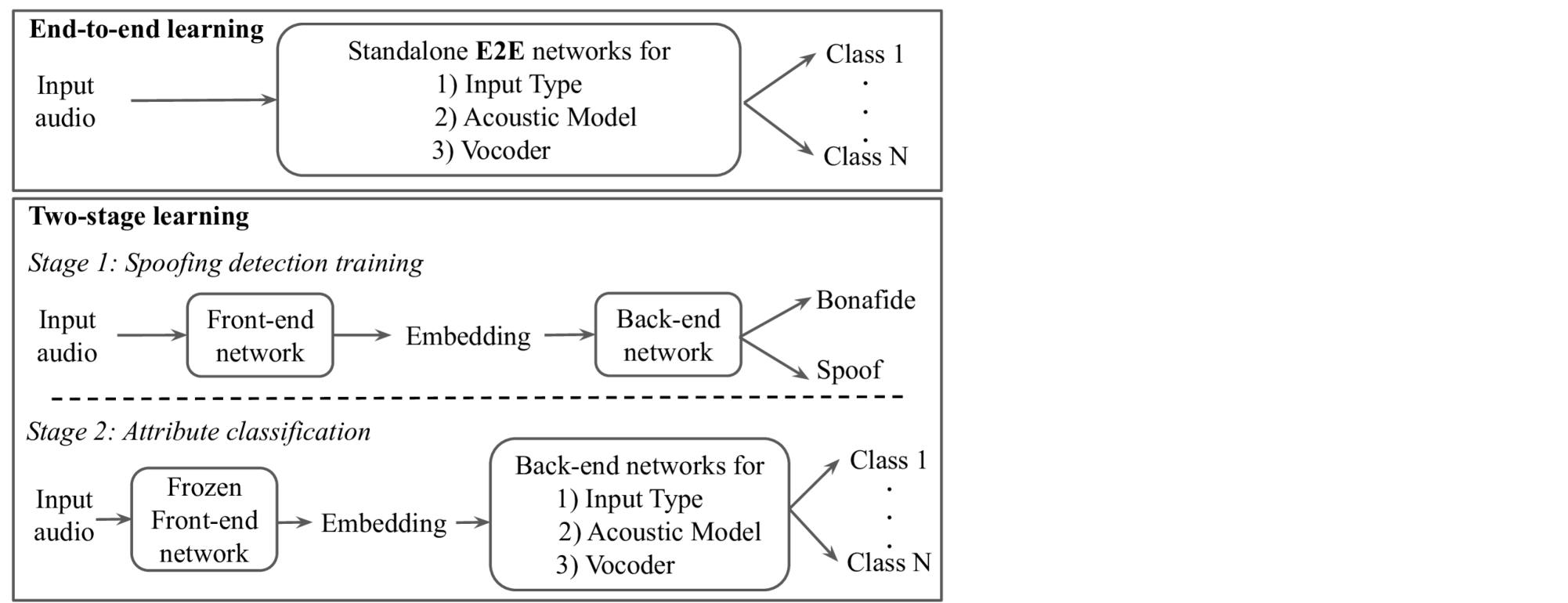
0
Source Tracing of Audio Deepfake Systems
Nicholas Klein, Tianxiang Chen, Hemlata Tak, Ricardo Casal, Elie Khoury
Recent progress in generative AI technology has made audio deepfakes remarkably more realistic. While current research on anti-spoofing systems primarily focuses on assessing whether a given audio sample is fake or genuine, there has been limited attention on discerning the specific techniques to create the audio deepfakes. Algorithms commonly used in audio deepfake generation, like text-to-speech (TTS) and voice conversion (VC), undergo distinct stages including input processing, acoustic modeling, and waveform generation. In this work, we introduce a system designed to classify various spoofing attributes, capturing the distinctive features of individual modules throughout the entire generation pipeline. We evaluate our system on two datasets: the ASVspoof 2019 Logical Access and the Multi-Language Audio Anti-Spoofing Dataset (MLAAD). Results from both experiments demonstrate the robustness of the system to identify the different spoofing attributes of deepfake generation systems.
Read more7/12/2024
🔎
0
The Codecfake Dataset and Countermeasures for the Universally Detection of Deepfake Audio
Yuankun Xie, Yi Lu, Ruibo Fu, Zhengqi Wen, Zhiyong Wang, Jianhua Tao, Xin Qi, Xiaopeng Wang, Yukun Liu, Haonan Cheng, Long Ye, Yi Sun
With the proliferation of Audio Language Model (ALM) based deepfake audio, there is an urgent need for generalized detection methods. ALM-based deepfake audio currently exhibits widespread, high deception, and type versatility, posing a significant challenge to current audio deepfake detection (ADD) models trained solely on vocoded data. To effectively detect ALM-based deepfake audio, we focus on the mechanism of the ALM-based audio generation method, the conversion from neural codec to waveform. We initially construct the Codecfake dataset, an open-source large-scale dataset, including 2 languages, over 1M audio samples, and various test conditions, focus on ALM-based audio detection. As countermeasure, to achieve universal detection of deepfake audio and tackle domain ascent bias issue of original SAM, we propose the CSAM strategy to learn a domain balanced and generalized minima. In our experiments, we first demonstrate that ADD model training with the Codecfake dataset can effectively detects ALM-based audio. Furthermore, our proposed generalization countermeasure yields the lowest average Equal Error Rate (EER) of 0.616% across all test conditions compared to baseline models. The dataset and associated code are available online.
Read more5/16/2024