Collaborative Optimization of Wireless Communication and Computing Resource Allocation based on Multi-Agent Federated Weighting Deep Reinforcement Learning
2404.01638
0
0
Abstract
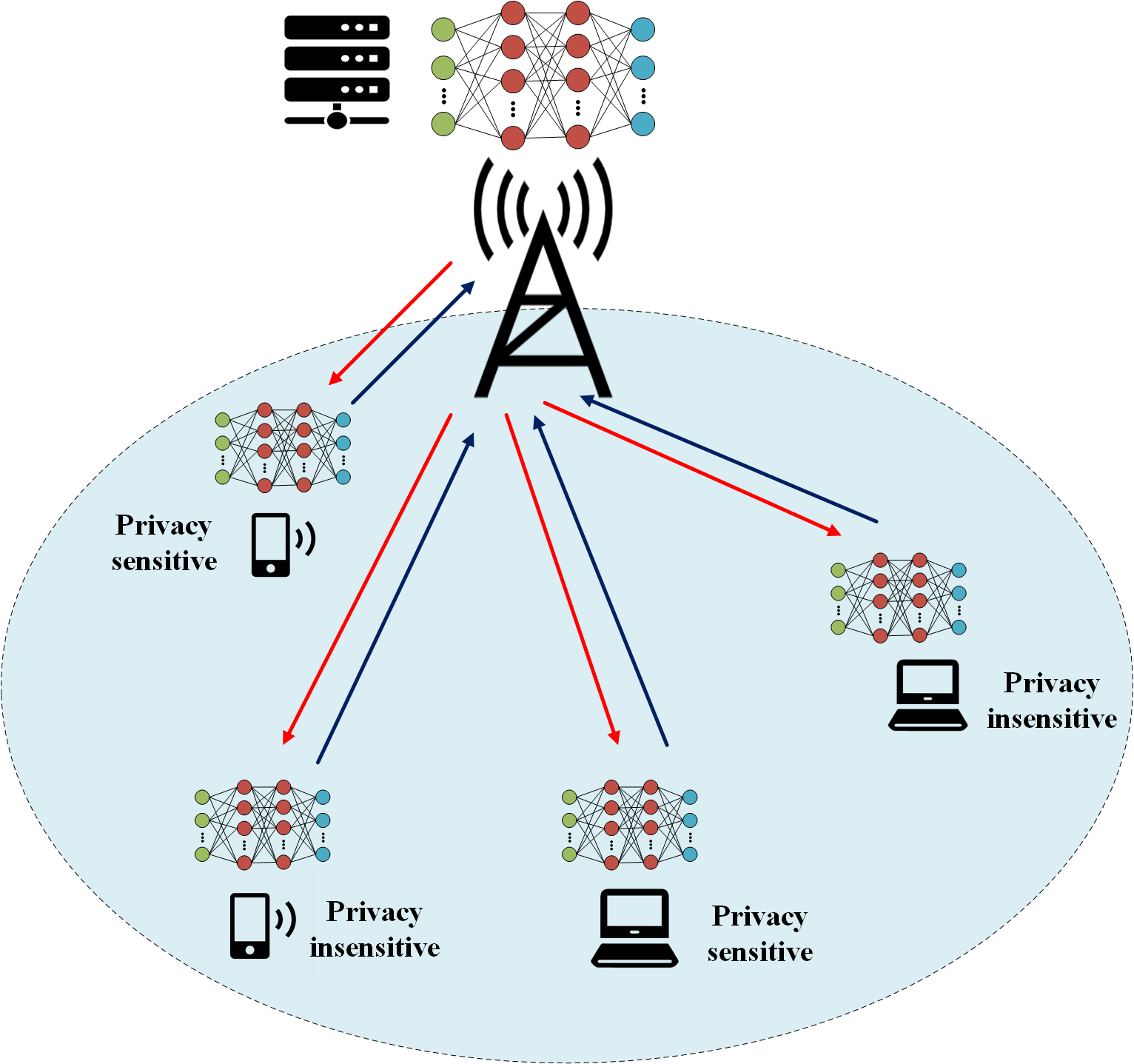
As artificial intelligence (AI)-enabled wireless communication systems continue their evolution, distributed learning has gained widespread attention for its ability to offer enhanced data privacy protection, improved resource utilization, and enhanced fault tolerance within wireless communication applications. Federated learning further enhances the ability of resource coordination and model generalization across nodes based on the above foundation, enabling the realization of an AI-driven communication and computing integrated wireless network. This paper proposes a novel wireless communication system to cater to a personalized service needs of both privacy-sensitive and privacy-insensitive users. We design the system based on based on multi-agent federated weighting deep reinforcement learning (MAFWDRL). The system, while fulfilling service requirements for users, facilitates real-time optimization of local communication resources allocation and concurrent decision-making concerning computing resources. Additionally, exploration noise is incorporated to enhance the exploration process of off-policy deep reinforcement learning (DRL) for wireless channels. Federated weighting (FedWgt) effectively compensates for heterogeneous differences in channel status between communication nodes. Extensive simulation experiments demonstrate that the proposed scheme outperforms baseline methods significantly in terms of throughput, calculation latency, and energy consumption improvement.
Create account to get full access
Overview
- This paper proposes a collaborative optimization framework for wireless communication and computing resource allocation using multi-agent federated weighting deep reinforcement learning (MAFWDRL).
- The goal is to improve the performance and energy efficiency of AI-enabled wireless communication systems while protecting user privacy.
- The framework combines distributed learning, multi-agent coordination, and deep reinforcement learning to optimize the allocation of wireless and computing resources.
Plain English Explanation
The paper presents a new way to manage the wireless communication and computing resources in AI-powered wireless systems. Traditional methods often struggle to balance performance, energy efficiency, and user privacy.
The researchers propose using a technique called multi-agent federated weighting deep reinforcement learning (MAFWDRL). This approach has several key features:
-
Distributed learning: Instead of a central controller, the system uses multiple "agents" that learn independently and share their knowledge. This helps protect user privacy since data doesn't need to be sent to a central location.
-
Multi-agent coordination: The different agents work together to make decisions about how to best use the available wireless and computing resources. This coordination helps improve overall system performance.
-
Deep reinforcement learning: The agents use a powerful AI technique called deep reinforcement learning to learn how to optimize resource allocation through trial-and-error. This allows them to adapt to changing conditions over time.
By combining these elements, the MAFWDRL framework can find a balance between high performance, energy efficiency, and privacy protection in AI-based wireless systems. This could lead to better user experiences and more sustainable wireless networks.
Technical Explanation
The paper presents a collaborative optimization framework for wireless communication and computing resource allocation using multi-agent federated weighting deep reinforcement learning (MAFWDRL).
The system model consists of multiple wireless users, edge computing servers, and a cloud data center. Each user has an agent that manages their wireless and computing resources using MAFWDRL. The agents learn independently but share their learned models in a federated manner to protect user privacy.
The optimization problem aims to minimize a weighted sum of the total system energy consumption and the total communication delay, subject to constraints on computing, communication, and user fairness. The MAFWDRL approach allows the agents to learn an optimal resource allocation policy through trial-and-error in a decentralized manner.
Key architectural elements of the MAFWDRL framework include:
- Federated learning: User data never leaves their local device, and the agents only share their learned models.
- Multi-agent coordination: Agents share their models and collaborate to optimize the overall system performance.
- Deep reinforcement learning: Agents use deep neural networks to learn an optimal resource allocation policy from interactions with the environment.
The experimental results demonstrate that the MAFWDRL framework can achieve significant improvements in energy efficiency and latency compared to benchmark methods, while also providing stronger user privacy protections.
Critical Analysis
The paper provides a comprehensive technical description of the proposed MAFWDRL framework and validates its performance through extensive simulations. The combination of distributed learning, multi-agent coordination, and deep reinforcement learning appears to be a promising approach for optimizing wireless communication and computing resource allocation in AI-enabled systems.
However, the paper does not discuss several important practical considerations. For example, it does not address how the framework would scale to very large numbers of users or handle heterogeneous device capabilities. The authors also do not explore potential vulnerabilities or security issues that could arise from the distributed learning architecture.
Additionally, the paper focuses on simulation results and does not provide any real-world experimental validation. It would be valuable to see how the MAFWDRL framework performs in a live deployment with actual wireless users and edge computing infrastructure.
Overall, the research presents an innovative technical solution, but further work is needed to address the practical challenges of implementing such a system in real-world settings and to fully understand its security and scalability implications.
Conclusion
This paper introduces a collaborative optimization framework called MAFWDRL that uses distributed learning, multi-agent coordination, and deep reinforcement learning to improve the performance and energy efficiency of AI-enabled wireless communication systems while protecting user privacy.
The key advantages of the MAFWDRL approach are its ability to learn optimal resource allocation policies in a decentralized manner, its resilience to changes in the environment, and its strong privacy guarantees. The simulation results demonstrate significant improvements over benchmark methods.
While the technical details are impressive, the paper does not fully address important practical considerations such as scalability, security, and real-world validation. Further research and development will be needed to transition this framework from a theoretical concept to a deployable solution for next-generation wireless networks.
Overall, the MAFWDRL framework represents an innovative step forward in the quest to create efficient, intelligent, and privacy-preserving wireless communication systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

An Integrated Communication and Computing Scheme for Wi-Fi Networks based on Generative AI and Reinforcement Learning
Xinyang Du, Xuming Fang
0
0
The continuous evolution of future mobile communication systems is heading towards the integration of communication and computing, with Mobile Edge Computing (MEC) emerging as a crucial means of implementing Artificial Intelligence (AI) computation. MEC could enhance the computational performance of wireless edge networks by offloading computing-intensive tasks to MEC servers. However, in edge computing scenarios, the sparse sample problem may lead to high costs of time-consuming model training. This paper proposes an MEC offloading decision and resource allocation solution that combines generative AI and deep reinforcement learning (DRL) for the communication-computing integration scenario in the 802.11ax Wi-Fi network. Initially, the optimal offloading policy is determined by the joint use of the Generative Diffusion Model (GDM) and the Twin Delayed DDPG (TD3) algorithm. Subsequently, resource allocation is accomplished by using the Hungarian algorithm. Simulation results demonstrate that the introduction of Generative AI significantly reduces model training costs, and the proposed solution exhibits significant reductions in system task processing latency and total energy consumption costs.
4/23/2024

Federated Multi-Agent DRL for Radio Resource Management in Industrial 6G in-X subnetworks
Bjarke Madsen, Ramoni Adeogun
0
0
Recently, 6G in-X subnetworks have been proposed as low-power short-range radio cells to support localized extreme wireless connectivity inside entities such as industrial robots, vehicles, and the human body. Deployment of in-X subnetworks within these entities may result in rapid changes in interference levels and thus, varying link quality. This paper investigates distributed dynamic channel allocation to mitigate inter-subnetwork interference in dense in-factory deployments of 6G in-X subnetworks. This paper introduces two new techniques, Federated Multi-Agent Double Deep Q-Network (F-MADDQN) and Federated Multi-Agent Deep Proximal Policy Optimization (F-MADPPO), for channel allocation in 6G in-X subnetworks. These techniques are based on a client-to-server horizontal federated reinforcement learning framework. The methods require sharing only local model weights with a centralized gNB for federated aggregation thereby preserving local data privacy and security. Simulations were conducted using a practical indoor factory environment proposed by 5G-ACIA and 3GPP models for in-factory environments. The results showed that the proposed methods achieved slightly better performance than baseline schemes with significantly reduced signaling overhead compared to the baseline solutions. The schemes also showed better robustness and generalization ability to changes in deployment densities and propagation parameters.
6/12/2024
On Designing Multi-UAV aided Wireless Powered Dynamic Communication via Hierarchical Deep Reinforcement Learning
Ze Yu Zhao, Yue Ling Che, Sheng Luo, Gege Luo, Kaishun Wu, Victor C. M. Leung
0
0
This paper proposes a novel design on the wireless powered communication network (WPCN) in dynamic environments under the assistance of multiple unmanned aerial vehicles (UAVs). Unlike the existing studies, where the low-power wireless nodes (WNs) often conform to the coherent harvest-then-transmit protocol, under our newly proposed double-threshold based WN type updating rule, each WN can dynamically and repeatedly update its WN type as an E-node for non-linear energy harvesting over time slots or an I-node for transmitting data over sub-slots. To maximize the total transmission data size of all the WNs over T slots, each of the UAVs individually determines its trajectory and binary wireless energy transmission (WET) decisions over times slots and its binary wireless data collection (WDC) decisions over sub-slots, under the constraints of each UAV's limited on-board energy and each WN's node type updating rule. However, due to the UAVs' tightly-coupled trajectories with their WET and WDC decisions, as well as each WN's time-varying battery energy, this problem is difficult to solve optimally. We then propose a new multi-agent based hierarchical deep reinforcement learning (MAHDRL) framework with two tiers to solve the problem efficiently, where the soft actor critic (SAC) policy is designed in tier-1 to determine each UAV's continuous trajectory and binary WET decision over time slots, and the deep-Q learning (DQN) policy is designed in tier-2 to determine each UAV's binary WDC decisions over sub-slots under the given UAV trajectory from tier-1. Both of the SAC policy and the DQN policy are executed distributively at each UAV. Finally, extensive simulation results are provided to validate the outweighed performance of the proposed MAHDRL approach over various state-of-the-art benchmarks.
6/10/2024
Personalized Wireless Federated Learning for Large Language Models
Feibo Jiang, Li Dong, Siwei Tu, Yubo Peng, Kezhi Wang, Kun Yang, Cunhua Pan, Dusit Niyato
0
0
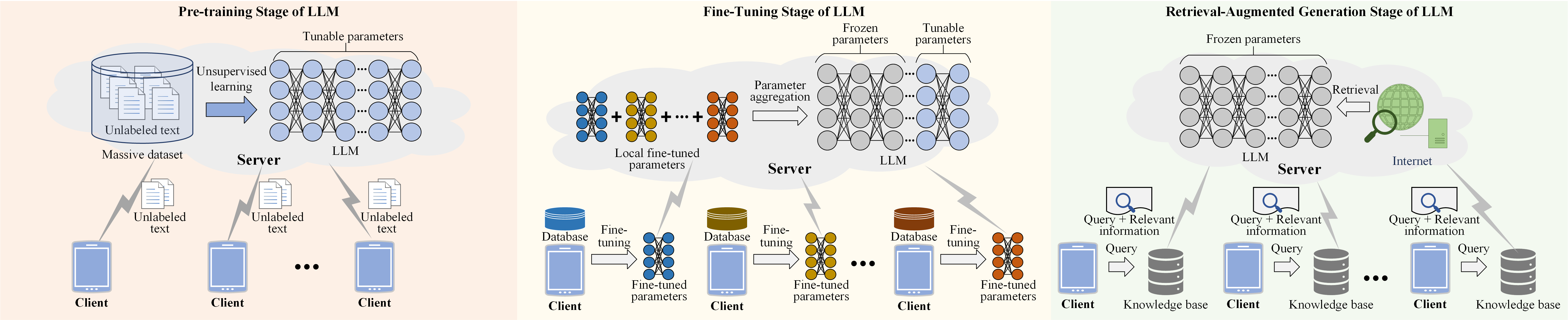
Large Language Models (LLMs) have revolutionized natural language processing tasks. However, their deployment in wireless networks still face challenges, i.e., a lack of privacy and security protection mechanisms. Federated Learning (FL) has emerged as a promising approach to address these challenges. Yet, it suffers from issues including inefficient handling with big and heterogeneous data, resource-intensive training, and high communication overhead. To tackle these issues, we first compare different learning stages and their features of LLMs in wireless networks. Next, we introduce two personalized wireless federated fine-tuning methods with low communication overhead, i.e., (1) Personalized Federated Instruction Tuning (PFIT), which employs reinforcement learning to fine-tune local LLMs with diverse reward models to achieve personalization; (2) Personalized Federated Task Tuning (PFTT), which can leverage global adapters and local Low-Rank Adaptations (LoRA) to collaboratively fine-tune local LLMs, where the local LoRAs can be applied to achieve personalization without aggregation. Finally, we perform simulations to demonstrate the effectiveness of the proposed two methods and comprehensively discuss open issues.
4/23/2024