Federated Multi-Agent DRL for Radio Resource Management in Industrial 6G in-X subnetworks
2406.07383
0
0

Abstract
Recently, 6G in-X subnetworks have been proposed as low-power short-range radio cells to support localized extreme wireless connectivity inside entities such as industrial robots, vehicles, and the human body. Deployment of in-X subnetworks within these entities may result in rapid changes in interference levels and thus, varying link quality. This paper investigates distributed dynamic channel allocation to mitigate inter-subnetwork interference in dense in-factory deployments of 6G in-X subnetworks. This paper introduces two new techniques, Federated Multi-Agent Double Deep Q-Network (F-MADDQN) and Federated Multi-Agent Deep Proximal Policy Optimization (F-MADPPO), for channel allocation in 6G in-X subnetworks. These techniques are based on a client-to-server horizontal federated reinforcement learning framework. The methods require sharing only local model weights with a centralized gNB for federated aggregation thereby preserving local data privacy and security. Simulations were conducted using a practical indoor factory environment proposed by 5G-ACIA and 3GPP models for in-factory environments. The results showed that the proposed methods achieved slightly better performance than baseline schemes with significantly reduced signaling overhead compared to the baseline solutions. The schemes also showed better robustness and generalization ability to changes in deployment densities and propagation parameters.
Create account to get full access
Overview
- The paper proposes a federated multi-agent deep reinforcement learning (DRL) framework for optimizing radio resource management in industrial 6G subnetworks.
- The approach uses a decentralized architecture to enable efficient resource allocation while preserving user privacy.
- Experiments demonstrate the framework's ability to outperform centralized approaches in terms of throughput, fairness, and energy efficiency.
Plain English Explanation
The paper introduces a new way to manage wireless communication resources in the next generation of 6G industrial networks. In these networks, there are many different devices and sensors that need to share the available radio frequencies and wireless bandwidth. Designing efficient resource allocation for these complex systems is a major challenge.
The researchers propose using a technique called federated multi-agent deep reinforcement learning. This allows each device or sensor to independently learn how to use the resources effectively, without sharing sensitive data with a central controller. This distributed approach is more scalable and privacy-preserving compared to centralized schemes.
Through experiments, the authors demonstrate that their federated DRL framework can outperform traditional centralized resource management in terms of key metrics like network throughput, fairness, and energy efficiency. This suggests the approach could be very useful for efficiently utilizing wireless resources in future industrial 6G networks with many connected devices.
Technical Explanation
The paper presents a federated multi-agent deep reinforcement learning (DRL) framework for optimizing radio resource management in industrial 6G subnetworks. The decentralized architecture allows each agent (e.g. device or sensor) to independently learn an optimal resource allocation policy without the need to share sensitive data with a central controller.
The framework consists of multiple DRL agents, each controlling the radio resources for its local subnetwork. The agents interact with a shared environment and are trained using a federated learning approach, where a global model is iteratively updated by aggregating gradients from the local agents. This preserves user privacy while enabling efficient resource allocation.
The authors evaluate the proposed framework against centralized baselines on metrics like throughput, fairness, and energy efficiency. The results demonstrate significant performance advantages of the federated DRL approach, particularly in scenarios with heterogeneous devices and network dynamics. The distributed nature of the framework also makes it more scalable compared to centralized schemes.
Critical Analysis
The paper provides a comprehensive evaluation of the proposed federated DRL framework and highlights its advantages over centralized resource management approaches. However, the authors do acknowledge several limitations and areas for future work.
One key limitation is the assumption of perfect channel state information, which may not hold in practical industrial 6G environments. Addressing imperfect or partial observability would be an important extension to improve the framework's real-world applicability.
Additionally, the authors do not consider the overhead and convergence time of the federated learning process, which could be an important factor in highly dynamic industrial networks. Exploring techniques to accelerate federated training would be a valuable direction for future research.
Overall, the paper presents a promising approach for efficient and privacy-preserving radio resource management in future industrial 6G networks. However, further work is needed to address the identified limitations and fully realize the potential of the federated DRL framework.
Conclusion
This paper introduces a novel federated multi-agent deep reinforcement learning framework for optimizing radio resource management in industrial 6G subnetworks. The decentralized architecture enables efficient resource allocation while preserving user privacy, and experiments demonstrate significant performance advantages over centralized baselines.
The work represents an important step towards realizing the vision of intelligent and flexible wireless networks for future industrial applications. By leveraging federated learning, the framework can adaptively manage resources in complex, dynamic environments without compromising the privacy of connected devices and sensors.
While the paper identifies some limitations that require further research, the proposed federated DRL approach shows great promise for enabling efficient and equitable utilization of wireless resources in the next generation of industrial 6G networks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
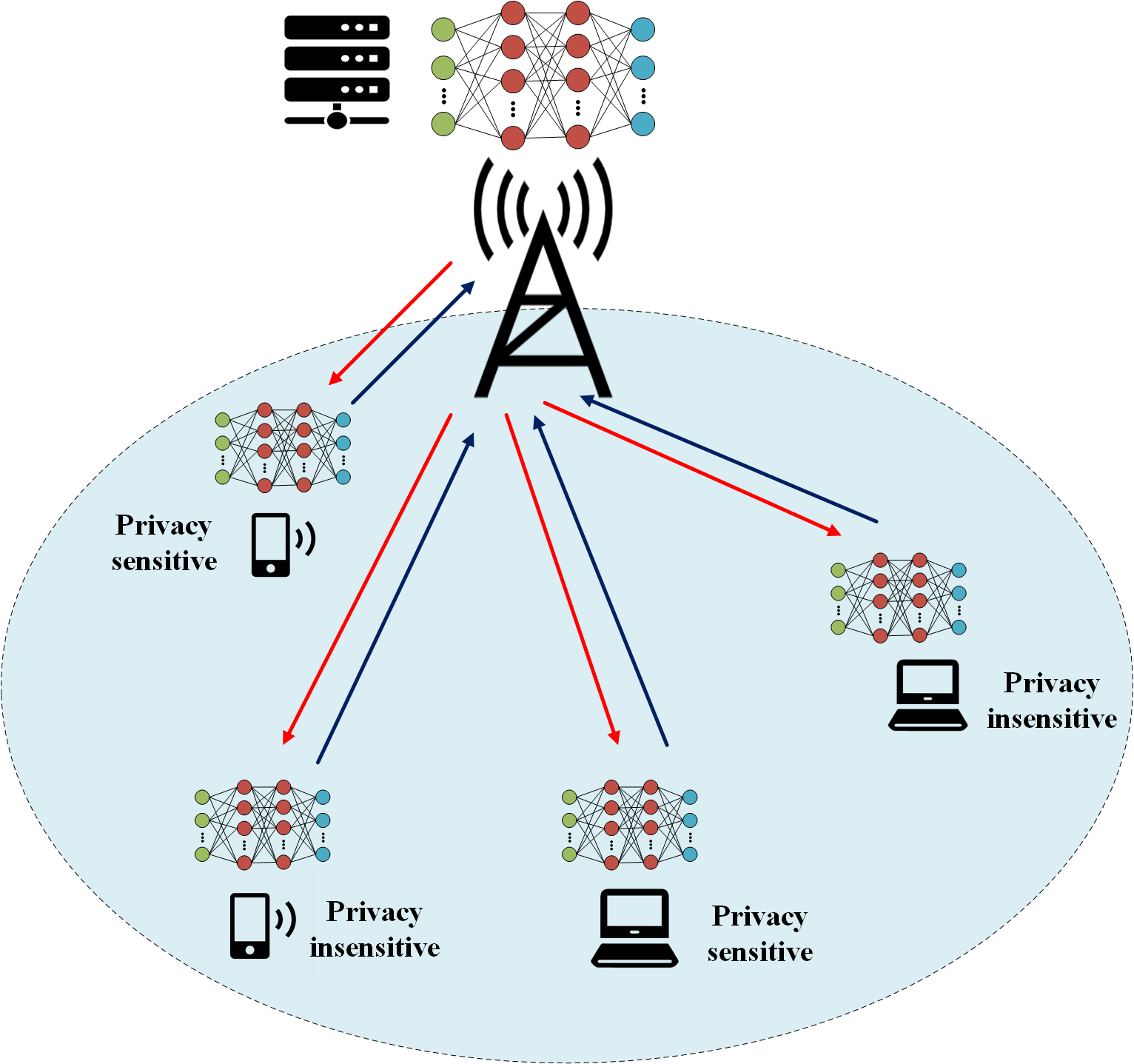
Collaborative Optimization of Wireless Communication and Computing Resource Allocation based on Multi-Agent Federated Weighting Deep Reinforcement Learning
Junjie Wu, Xuming Fang
0
0
As artificial intelligence (AI)-enabled wireless communication systems continue their evolution, distributed learning has gained widespread attention for its ability to offer enhanced data privacy protection, improved resource utilization, and enhanced fault tolerance within wireless communication applications. Federated learning further enhances the ability of resource coordination and model generalization across nodes based on the above foundation, enabling the realization of an AI-driven communication and computing integrated wireless network. This paper proposes a novel wireless communication system to cater to a personalized service needs of both privacy-sensitive and privacy-insensitive users. We design the system based on based on multi-agent federated weighting deep reinforcement learning (MAFWDRL). The system, while fulfilling service requirements for users, facilitates real-time optimization of local communication resources allocation and concurrent decision-making concerning computing resources. Additionally, exploration noise is incorporated to enhance the exploration process of off-policy deep reinforcement learning (DRL) for wireless channels. Federated weighting (FedWgt) effectively compensates for heterogeneous differences in channel status between communication nodes. Extensive simulation experiments demonstrate that the proposed scheme outperforms baseline methods significantly in terms of throughput, calculation latency, and energy consumption improvement.
4/3/2024
🛠️
Design Optimization of NOMA Aided Multi-STAR-RIS for Indoor Environments: A Convex Approximation Imitated Reinforcement Learning Approach
Yu Min Park, Sheikh Salman Hassan, Yan Kyaw Tun, Eui-Nam Huh, Walid Saad, Choong Seon Hong
0
0
Sixth-generation (6G) networks leverage simultaneously transmitting and reflecting reconfigurable intelligent surfaces (STAR-RISs) to overcome the limitations of traditional RISs. STAR-RISs offer 360-degree full-space coverage and optimized transmission and reflection for enhanced network performance and dynamic control of the indoor propagation environment. However, deploying STAR-RISs indoors presents challenges in interference mitigation, power consumption, and real-time configuration. In this work, a novel network architecture utilizing multiple access points (APs) and STAR-RISs is proposed for indoor communication. An optimization problem encompassing user assignment, access point beamforming, and STAR-RIS phase control for reflection and transmission is formulated. The inherent complexity of the formulated problem necessitates a decomposition approach for an efficient solution. This involves tackling different sub-problems with specialized techniques: a many-to-one matching algorithm is employed to assign users to appropriate access points, optimizing resource allocation. To facilitate efficient resource management, access points are grouped using a correlation-based K-means clustering algorithm. Multi-agent deep reinforcement learning (MADRL) is leveraged to optimize the control of the STAR-RIS. Within the proposed MADRL framework, a novel approach is introduced where each decision variable acts as an independent agent, enabling collaborative learning and decision-making. Additionally, the proposed MADRL approach incorporates convex approximation (CA). This technique utilizes suboptimal solutions from successive convex approximation (SCA) to accelerate policy learning for the agents, thereby leading to faster environment adaptation and convergence. Simulations demonstrate significant network utility improvements compared to baseline approaches.
6/21/2024
On Designing Multi-UAV aided Wireless Powered Dynamic Communication via Hierarchical Deep Reinforcement Learning
Ze Yu Zhao, Yue Ling Che, Sheng Luo, Gege Luo, Kaishun Wu, Victor C. M. Leung
0
0
This paper proposes a novel design on the wireless powered communication network (WPCN) in dynamic environments under the assistance of multiple unmanned aerial vehicles (UAVs). Unlike the existing studies, where the low-power wireless nodes (WNs) often conform to the coherent harvest-then-transmit protocol, under our newly proposed double-threshold based WN type updating rule, each WN can dynamically and repeatedly update its WN type as an E-node for non-linear energy harvesting over time slots or an I-node for transmitting data over sub-slots. To maximize the total transmission data size of all the WNs over T slots, each of the UAVs individually determines its trajectory and binary wireless energy transmission (WET) decisions over times slots and its binary wireless data collection (WDC) decisions over sub-slots, under the constraints of each UAV's limited on-board energy and each WN's node type updating rule. However, due to the UAVs' tightly-coupled trajectories with their WET and WDC decisions, as well as each WN's time-varying battery energy, this problem is difficult to solve optimally. We then propose a new multi-agent based hierarchical deep reinforcement learning (MAHDRL) framework with two tiers to solve the problem efficiently, where the soft actor critic (SAC) policy is designed in tier-1 to determine each UAV's continuous trajectory and binary WET decision over time slots, and the deep-Q learning (DQN) policy is designed in tier-2 to determine each UAV's binary WDC decisions over sub-slots under the given UAV trajectory from tier-1. Both of the SAC policy and the DQN policy are executed distributively at each UAV. Finally, extensive simulation results are provided to validate the outweighed performance of the proposed MAHDRL approach over various state-of-the-art benchmarks.
6/10/2024
🏅
Mobility-Aware Resource Allocation for mmWave IAB Networks: A Multi-Agent Reinforcement Learning Approach
Bibo Zhang, Ilario Filippini
0
0
MmWaves have been envisioned as a promising direction to provide Gbps wireless access. However, they are susceptible to high path losses and blockages, which directional antennas can only partially mitigate. That makes mmWave networks coverage-limited, thus requiring dense deployments. Integrated access and backhaul (IAB) architectures have emerged as a cost-effective solution for network densification. Resource allocation in mmWave IAB networks must face big challenges to cope with heavy temporal dynamics, such as intermittent links caused by user mobility and blockages from moving obstacles. This makes it extremely difficult to find optimal and adaptive solutions. In this article, exploiting the distributed structure of the problem, we propose a Multi-Agent Reinforcement Learning (MARL) framework to optimize user throughput via flow routing and link scheduling in mmWave IAB networks characterized by user mobility and link outages generated by moving obstacles. The proposed approach implicitly captures the environment dynamics, coordinates the interference, and manages the buffer levels of IAB relay nodes. We design different MARL components, considering full-duplex and half-duplex IAB-nodes. In addition, we provide a communication and coordination scheme for RL agents in an online training framework, addressing the feasibility issues of practical systems. Numerical results show the effectiveness of the proposed approach.
4/24/2024