Common pitfalls to avoid while using multiobjective optimization in machine learning
2405.01480
0
0
🛠️
Abstract
Recently, there has been an increasing interest in exploring the application of multiobjective optimization (MOO) in machine learning (ML). The interest is driven by the numerous situations in real-life applications where multiple objectives need to be optimized simultaneously. A key aspect of MOO is the existence of a Pareto set, rather than a single optimal solution, which illustrates the inherent trade-offs between objectives. Despite its potential, there is a noticeable lack of satisfactory literature that could serve as an entry-level guide for ML practitioners who want to use MOO. Hence, our goal in this paper is to produce such a resource. We critically review previous studies, particularly those involving MOO in deep learning (using Physics-Informed Neural Networks (PINNs) as a guiding example), and identify misconceptions that highlight the need for a better grasp of MOO principles in ML. Using MOO of PINNs as a case study, we demonstrate the interplay between the data loss and the physics loss terms. We highlight the most common pitfalls one should avoid while using MOO techniques in ML. We begin by establishing the groundwork for MOO, focusing on well-known approaches such as the weighted sum (WS) method, alongside more complex techniques like the multiobjective gradient descent algorithm (MGDA). Additionally, we compare the results obtained from the WS and MGDA with one of the most common evolutionary algorithms, NSGA-II. We emphasize the importance of understanding the specific problem, the objective space, and the selected MOO method, while also noting that neglecting factors such as convergence can result in inaccurate outcomes and, consequently, a non-optimal solution. Our goal is to offer a clear and practical guide for ML practitioners to effectively apply MOO, particularly in the context of DL.
Create account to get full access
Overview
- Multiobjective optimization (MOO) is an increasingly important technique in machine learning (ML) with real-world applications
- MOO involves optimizing multiple objectives simultaneously, leading to a Pareto set of solutions rather than a single optimal solution
- While MOO has potential, there is a lack of resources to guide ML practitioners on how to effectively apply it
Plain English Explanation
MOO is a way of solving problems where there are multiple goals or objectives that need to be balanced. For example, when designing a new car, the manufacturer might want to maximize fuel efficiency, minimize cost, and maximize safety - these are three competing objectives. In a single-objective optimization, you'd try to find the single best solution that optimizes one goal. But with MOO, you instead look for a set of good solutions that represent different trade-offs between the objectives.
This is useful in machine learning because many real-world problems have multiple, competing goals. For instance, a machine learning model for loan approvals might need to balance accuracy, fairness, and interpretability. MOO can help find models that represent different compromises between these objectives.
However, actually applying MOO techniques in machine learning can be challenging. The authors of this paper aim to provide a clear, practical guide to help ML practitioners effectively use MOO, especially in the context of deep learning models like Physics-Informed Neural Networks (PINNs).
Technical Explanation
The paper begins by reviewing previous work on using MOO in machine learning, particularly in deep learning applications. The authors identify some misconceptions and a need for a better understanding of MOO principles among ML practitioners.
Using PINNs as a case study, the paper demonstrates the interplay between the data loss and physics loss objectives in a MOO setting. It highlights common pitfalls to avoid when applying MOO techniques in ML.
The paper then covers well-known MOO approaches like the weighted sum (WS) method, as well as more advanced techniques like the multiobjective gradient descent algorithm (MGDA). It compares the results of these methods to the popular evolutionary algorithm NSGA-II.
The key message is that properly understanding the problem, the objective space, and the selected MOO method is crucial. Neglecting factors like convergence can lead to inaccurate and suboptimal solutions. The authors aim to provide a practical guide to help ML practitioners effectively apply MOO, especially in deep learning contexts.
Critical Analysis
The paper provides a valuable resource for ML practitioners looking to apply MOO techniques, especially in the context of deep learning models like PINNs. By highlighting common misconceptions and pitfalls, the authors help readers avoid potential issues when using MOO in their own work.
That said, the paper focuses primarily on the technical aspects of MOO and could potentially benefit from more discussion of the real-world implications and applications of these techniques. For example, how might MOO be used to enhance fairness and performance in machine learning models or enable collaborative Pareto set learning?
Additionally, the paper could explore ways to adapt multi-objectivized software configuration tuning for machine learning use cases, which could provide further insights for practitioners.
Overall, the paper is a strong technical resource, but could potentially be strengthened by a more holistic discussion of MOO's practical applications and impact in the field of machine learning.
Conclusion
This paper provides a much-needed guide for machine learning practitioners looking to apply multiobjective optimization (MOO) techniques, particularly in the context of deep learning models like Physics-Informed Neural Networks (PINNs).
By critically reviewing previous studies, identifying common misconceptions, and using PINNs as a case study, the authors offer a clear and practical resource to help ML practitioners effectively leverage MOO. The insights and recommendations provided can enable researchers and engineers to better balance competing objectives and find more optimal solutions for their real-world machine learning problems.
As MOO continues to grow in importance for the field of machine learning, this paper serves as a valuable entry point for practitioners seeking to expand their toolkit and unlock the benefits of this powerful optimization approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
Multi-Objective Hyperparameter Optimization in Machine Learning -- An Overview
Florian Karl, Tobias Pielok, Julia Moosbauer, Florian Pfisterer, Stefan Coors, Martin Binder, Lennart Schneider, Janek Thomas, Jakob Richter, Michel Lang, Eduardo C. Garrido-Merch'an, Juergen Branke, Bernd Bischl
0
0
Hyperparameter optimization constitutes a large part of typical modern machine learning workflows. This arises from the fact that machine learning methods and corresponding preprocessing steps often only yield optimal performance when hyperparameters are properly tuned. But in many applications, we are not only interested in optimizing ML pipelines solely for predictive accuracy; additional metrics or constraints must be considered when determining an optimal configuration, resulting in a multi-objective optimization problem. This is often neglected in practice, due to a lack of knowledge and readily available software implementations for multi-objective hyperparameter optimization. In this work, we introduce the reader to the basics of multi-objective hyperparameter optimization and motivate its usefulness in applied ML. Furthermore, we provide an extensive survey of existing optimization strategies, both from the domain of evolutionary algorithms and Bayesian optimization. We illustrate the utility of MOO in several specific ML applications, considering objectives such as operating conditions, prediction time, sparseness, fairness, interpretability and robustness.
6/7/2024
📊
Data vs. Physics: The Apparent Pareto Front of Physics-Informed Neural Networks
Franz M. Rohrhofer, Stefan Posch, Clemens Go{ss}nitzer, Bernhard C. Geiger
0
0
Physics-informed neural networks (PINNs) have emerged as a promising deep learning method, capable of solving forward and inverse problems governed by differential equations. Despite their recent advance, it is widely acknowledged that PINNs are difficult to train and often require a careful tuning of loss weights when data and physics loss functions are combined by scalarization of a multi-objective (MO) problem. In this paper, we aim to understand how parameters of the physical system, such as characteristic length and time scales, the computational domain, and coefficients of differential equations affect MO optimization and the optimal choice of loss weights. Through a theoretical examination of where these system parameters appear in PINN training, we find that they effectively and individually scale the loss residuals, causing imbalances in MO optimization with certain choices of system parameters. The immediate effects of this are reflected in the apparent Pareto front, which we define as the set of loss values achievable with gradient-based training and visualize accordingly. We empirically verify that loss weights can be used successfully to compensate for the scaling of system parameters, and enable the selection of an optimal solution on the apparent Pareto front that aligns well with the physically valid solution. We further demonstrate that by altering the system parameterization, the apparent Pareto front can shift and exhibit locally convex parts, resulting in a wider range of loss weights for which gradient-based training becomes successful. This work explains the effects of system parameters on MO optimization in PINNs, and highlights the utility of proposed loss weighting schemes.
6/11/2024
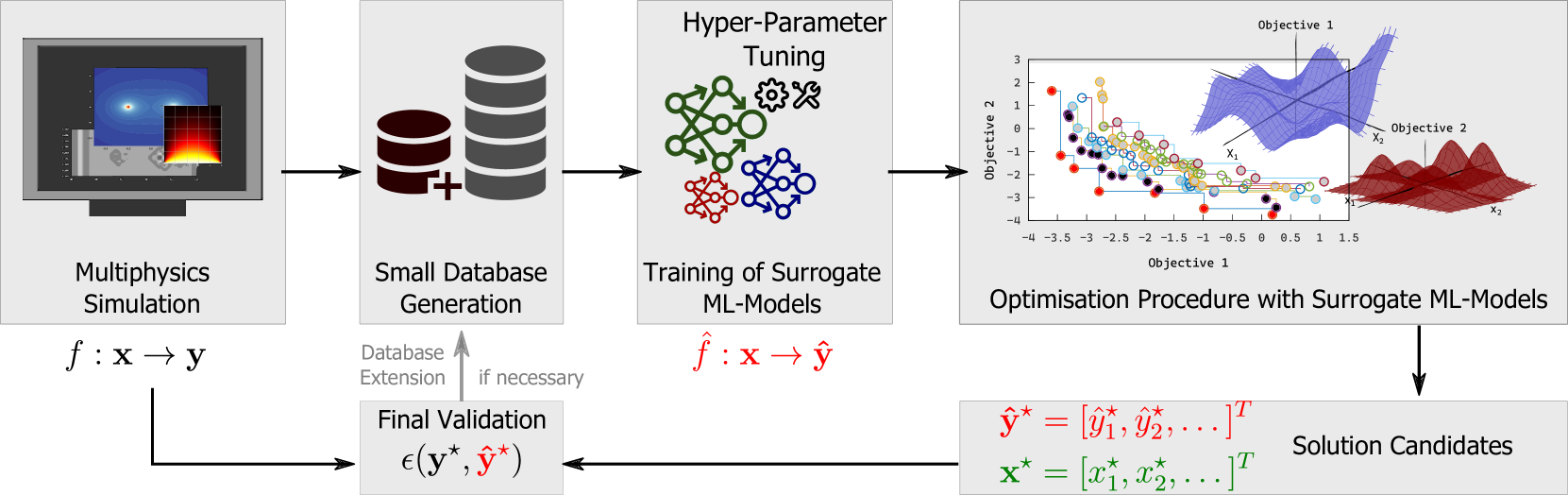
Enhancing Multi-Objective Optimization through Machine Learning-Supported Multiphysics Simulation
Diego Botache, Jens Decke, Winfried Ripken, Abhinay Dornipati, Franz Gotz-Hahn, Mohamed Ayeb, Bernhard Sick
0
0
This paper presents a methodological framework for training, self-optimising, and self-organising surrogate models to approximate and speed up multiobjective optimisation of technical systems based on multiphysics simulations. At the hand of two real-world datasets, we illustrate that surrogate models can be trained on relatively small amounts of data to approximate the underlying simulations accurately. Including explainable AI techniques allow for highlighting feature relevancy or dependencies and supporting the possible extension of the used datasets. One of the datasets was created for this paper and is made publicly available for the broader scientific community. Extensive experiments combine four machine learning and deep learning algorithms with an evolutionary optimisation algorithm. The performance of the combined training and optimisation pipeline is evaluated by verifying the generated Pareto-optimal results using the ground truth simulations. The results from our pipeline and a comprehensive evaluation strategy show the potential for efficiently acquiring solution candidates in multiobjective optimisation tasks by reducing the number of simulations and conserving a higher prediction accuracy, i.e., with a MAPE score under 5% for one of the presented use cases.
4/4/2024
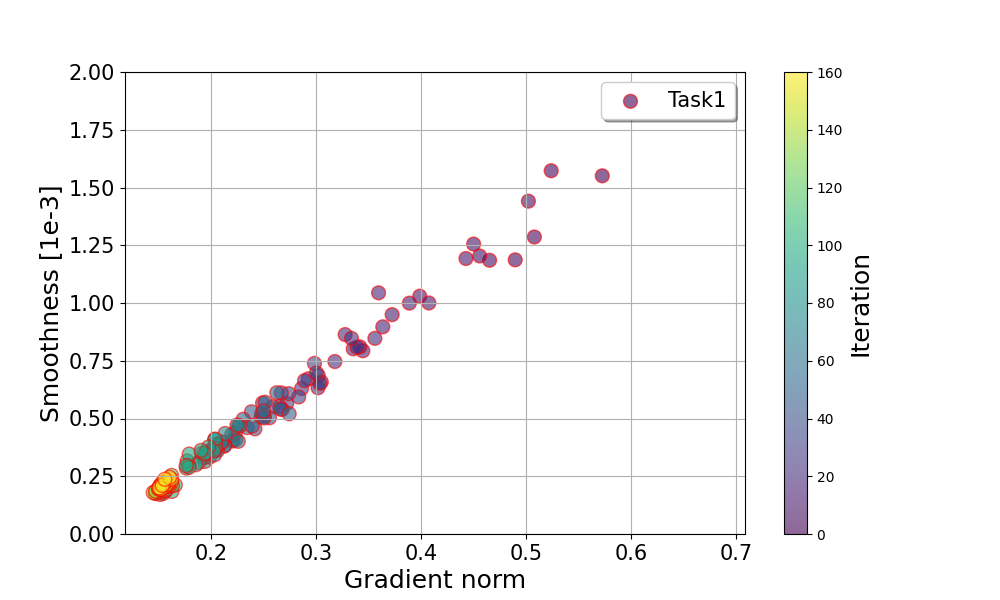
On the Convergence of Multi-objective Optimization under Generalized Smoothness
Qi Zhang, Peiyao Xiao, Kaiyi Ji, Shaofeng Zou
0
0
Multi-objective optimization (MOO) is receiving more attention in various fields such as multi-task learning. Recent works provide some effective algorithms with theoretical analysis but they are limited by the standard $L$-smooth or bounded-gradient assumptions, which are typically unsatisfactory for neural networks, such as recurrent neural networks (RNNs) and transformers. In this paper, we study a more general and realistic class of $ell$-smooth loss functions, where $ell$ is a general non-decreasing function of gradient norm. We develop two novel single-loop algorithms for $ell$-smooth MOO problems, Generalized Smooth Multi-objective Gradient descent (GSMGrad) and its stochastic variant, Stochastic Generalized Smooth Multi-objective Gradient descent (SGSMGrad), which approximate the conflict-avoidant (CA) direction that maximizes the minimum improvement among objectives. We provide a comprehensive convergence analysis of both algorithms and show that they converge to an $epsilon$-accurate Pareto stationary point with a guaranteed $epsilon$-level average CA distance (i.e., the gap between the updating direction and the CA direction) over all iterations, where totally $mathcal{O}(epsilon^{-2})$ and $mathcal{O}(epsilon^{-4})$ samples are needed for deterministic and stochastic settings, respectively. Our algorithms can also guarantee a tighter $epsilon$-level CA distance in each iteration using more samples. Moreover, we propose a practical variant of GSMGrad named GSMGrad-FA using only constant-level time and space, while achieving the same performance guarantee as GSMGrad. Our experiments validate our theory and demonstrate the effectiveness of the proposed methods.
6/14/2024