Common Sense Reasoning for Deepfake Detection

0

Sign in to get full access
Overview
- This paper proposes a common-sense reasoning approach to detecting deepfake videos by analyzing visual and contextual cues.
- The authors develop a Deepfake Detection Visual Question Answering (VQA) model that can identify inconsistencies and anomalies in deepfake videos.
- The model is trained on a large dataset of real and synthetic videos, and is able to outperform existing deepfake detection methods.
Plain English Explanation
The paper focuses on using common-sense reasoning to detect deepfake videos - videos that have been digitally manipulated to show someone saying or doing something they didn't actually do. The key idea is to look for subtle inconsistencies or unusual details in the video that a human viewer might notice, but that might be missed by standard deepfake detection algorithms.
The researchers developed a model called Deepfake Detection VQA that analyzes both the visual content of the video and the surrounding context. For example, it might notice that the person's mouth movements don't quite sync up with the audio, or that the lighting and shadows in the scene don't look quite right. By picking up on these kinds of clues, the model is able to distinguish real videos from deepfakes with a high degree of accuracy.
This approach is valuable because deepfake technology is becoming more and more advanced, making it harder for traditional detection methods to keep up. By tapping into human-like reasoning about what "makes sense" in a video, the Deepfake Detection VQA model can stay one step ahead of the deepfake creators. This could be an important tool for identifying and combating the spread of misinformation and fake news fueled by deepfake videos.
Technical Explanation
The paper proposes a novel approach to deepfake detection called Deepfake Detection Visual Question Answering (VQA). The key idea is to leverage common-sense reasoning about the visual and contextual cues in a video to identify inconsistencies and anomalies that are indicative of a deepfake.
The Deepfake Detection VQA model is built on top of a pre-trained VQA architecture, which is fine-tuned on a large dataset of real and synthetic videos. The model is trained to answer questions about the content and plausibility of the video, such as "Does the person's mouth movements match the audio?" or "Is the lighting consistent throughout the scene?"
By analyzing both the visual information and the contextual cues, the model is able to pick up on subtle discrepancies that a human viewer might notice, but which may not be detected by standard deepfake detection algorithms that focus solely on low-level visual features.
The authors evaluate their approach on several benchmark deepfake detection datasets and show that the Deepfake Detection VQA model outperforms existing state-of-the-art methods. They also provide detailed analysis and case studies to shed light on the model's decision-making process and the types of cues it uses to distinguish real from fake videos.
Critical Analysis
The paper presents a promising approach to deepfake detection that leverages common-sense reasoning about visual and contextual cues. However, there are a few potential limitations and areas for further research:
-
The model's performance may be sensitive to the specific types of deepfakes it was trained on. It remains to be seen how well it would generalize to new, unseen deepfake techniques that emerge in the future.
-
The dataset used for training and evaluation, while large, may not fully capture the diversity of real-world deepfake videos. More work is needed to ensure the model's robustness across a wide range of deepfake styles and scenarios.
-
The paper does not delve deeply into the interpretability of the model's decision-making process. Providing more transparency into how the model arrives at its predictions could help build trust and facilitate further research in this area.
Despite these limitations, the Deepfake Detection VQA approach represents an important step forward in the arms race against deepfake technology. By combining computer vision techniques with human-like common-sense reasoning, this work opens up new avenues for detecting and mitigating the spread of manipulated media. Further research and refinement of this approach could yield valuable tools for safeguarding the integrity of digital content.
Conclusion
This paper presents a novel deepfake detection method that leverages common-sense reasoning about visual and contextual cues in videos. By training a Deepfake Detection VQA model to analyze the plausibility and consistency of video content, the authors demonstrate an effective approach for distinguishing real videos from synthetic deepfakes.
The key strength of this work is its ability to tap into the human-like understanding of what "makes sense" in a video, going beyond low-level visual features to identify subtle inconsistencies that may indicate a deepfake. As deepfake technology continues to advance, this type of common-sense reasoning could prove invaluable for staying ahead of the curve and preserving the integrity of digital media.
While there are some limitations that warrant further research, the Deepfake Detection VQA model represents an important step forward in the fight against misinformation and manipulation. By combining computer vision with common-sense understanding, this work opens up new possibilities for building robust and trustworthy deepfake detection systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Common Sense Reasoning for Deepfake Detection
Yue Zhang, Ben Colman, Xiao Guo, Ali Shahriyari, Gaurav Bharaj
State-of-the-art deepfake detection approaches rely on image-based features extracted via neural networks. While these approaches trained in a supervised manner extract likely fake features, they may fall short in representing unnatural `non-physical' semantic facial attributes -- blurry hairlines, double eyebrows, rigid eye pupils, or unnatural skin shading. However, such facial attributes are easily perceived by humans and used to discern the authenticity of an image based on human common sense. Furthermore, image-based feature extraction methods that provide visual explanations via saliency maps can be hard to interpret for humans. To address these challenges, we frame deepfake detection as a Deepfake Detection VQA (DD-VQA) task and model human intuition by providing textual explanations that describe common sense reasons for labeling an image as real or fake. We introduce a new annotated dataset and propose a Vision and Language Transformer-based framework for the DD-VQA task. We also incorporate text and image-aware feature alignment formulation to enhance multi-modal representation learning. As a result, we improve upon existing deepfake detection models by integrating our learned vision representations, which reason over common sense knowledge from the DD-VQA task. We provide extensive empirical results demonstrating that our method enhances detection performance, generalization ability, and language-based interpretability in the deepfake detection task.
Read more7/19/2024
🌿
0
Parents and Children: Distinguishing Multimodal DeepFakes from Natural Images
Roberto Amoroso, Davide Morelli, Marcella Cornia, Lorenzo Baraldi, Alberto Del Bimbo, Rita Cucchiara
Recent advancements in diffusion models have enabled the generation of realistic deepfakes from textual prompts in natural language. While these models have numerous benefits across various sectors, they have also raised concerns about the potential misuse of fake images and cast new pressures on fake image detection. In this work, we pioneer a systematic study on deepfake detection generated by state-of-the-art diffusion models. Firstly, we conduct a comprehensive analysis of the performance of contrastive and classification-based visual features, respectively extracted from CLIP-based models and ResNet or ViT-based architectures trained on image classification datasets. Our results demonstrate that fake images share common low-level cues, which render them easily recognizable. Further, we devise a multimodal setting wherein fake images are synthesized by different textual captions, which are used as seeds for a generator. Under this setting, we quantify the performance of fake detection strategies and introduce a contrastive-based disentangling method that lets us analyze the role of the semantics of textual descriptions and low-level perceptual cues. Finally, we release a new dataset, called COCOFake, containing about 1.2M images generated from the original COCO image-caption pairs using two recent text-to-image diffusion models, namely Stable Diffusion v1.4 and v2.0.
Read more5/22/2024

0
An Analysis of Recent Advances in Deepfake Image Detection in an Evolving Threat Landscape
Sifat Muhammad Abdullah, Aravind Cheruvu, Shravya Kanchi, Taejoong Chung, Peng Gao, Murtuza Jadliwala, Bimal Viswanath
Deepfake or synthetic images produced using deep generative models pose serious risks to online platforms. This has triggered several research efforts to accurately detect deepfake images, achieving excellent performance on publicly available deepfake datasets. In this work, we study 8 state-of-the-art detectors and argue that they are far from being ready for deployment due to two recent developments. First, the emergence of lightweight methods to customize large generative models, can enable an attacker to create many customized generators (to create deepfakes), thereby substantially increasing the threat surface. We show that existing defenses fail to generalize well to such emph{user-customized generative models} that are publicly available today. We discuss new machine learning approaches based on content-agnostic features, and ensemble modeling to improve generalization performance against user-customized models. Second, the emergence of textit{vision foundation models} -- machine learning models trained on broad data that can be easily adapted to several downstream tasks -- can be misused by attackers to craft adversarial deepfakes that can evade existing defenses. We propose a simple adversarial attack that leverages existing foundation models to craft adversarial samples textit{without adding any adversarial noise}, through careful semantic manipulation of the image content. We highlight the vulnerabilities of several defenses against our attack, and explore directions leveraging advanced foundation models and adversarial training to defend against this new threat.
Read more4/26/2024
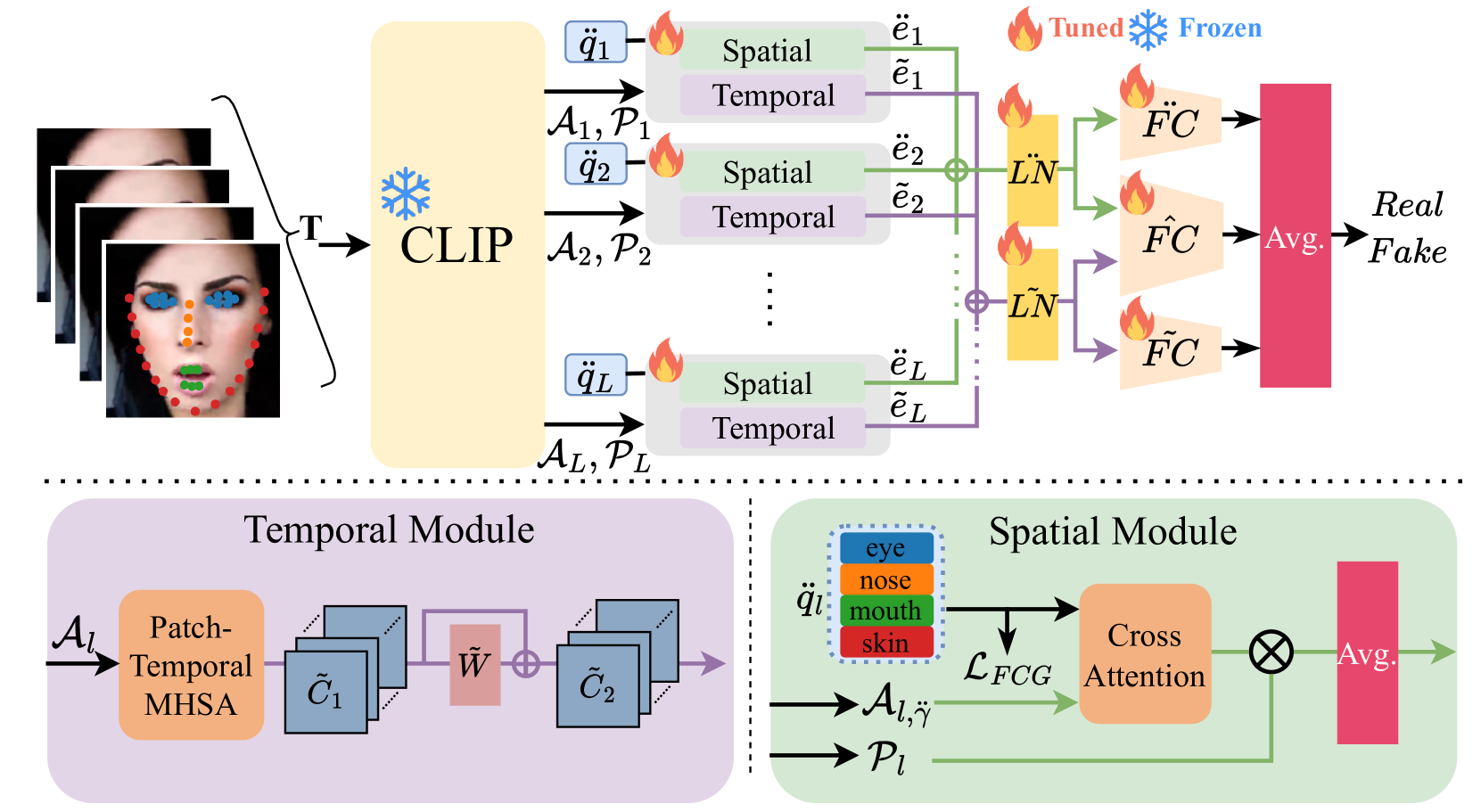
0
Towards More General Video-based Deepfake Detection through Facial Feature Guided Adaptation for Foundation Model
Yue-Hua Han, Tai-Ming Huang, Shu-Tzu Lo, Po-Han Huang, Kai-Lung Hua, Jun-Cheng Chen
With the rise of deep learning, generative models have enabled the creation of highly realistic synthetic images, presenting challenges due to their potential misuse. While research in Deepfake detection has grown rapidly in response, many detection methods struggle with unseen Deepfakes generated by new synthesis techniques. To address this generalisation challenge, we propose a novel Deepfake detection approach by adapting the Foundation Models with rich information encoded inside, specifically using the image encoder from CLIP which has demonstrated strong zero-shot capability for downstream tasks. Inspired by the recent advances of parameter efficient fine-tuning, we propose a novel side-network-based decoder to extract spatial and temporal cues from the given video clip, with the promotion of the Facial Component Guidance (FCG) to encourage the spatial feature to include features of key facial parts for more robust and general Deepfake detection. Through extensive cross-dataset evaluations, our approach exhibits superior effectiveness in identifying unseen Deepfake samples, achieving notable performance improvement even with limited training samples and manipulation types. Our model secures an average performance enhancement of 0.9% AUROC in cross-dataset assessments comparing with state-of-the-art methods, especially a significant lead of achieving 4.4% improvement on the challenging DFDC dataset.
Read more6/6/2024