Communication-Efficient Training Workload Balancing for Decentralized Multi-Agent Learning
2405.00839
0
0

Abstract
Decentralized Multi-agent Learning (DML) enables collaborative model training while preserving data privacy. However, inherent heterogeneity in agents' resources (computation, communication, and task size) may lead to substantial variations in training time. This heterogeneity creates a bottleneck, lengthening the overall training time due to straggler effects and potentially wasting spare resources of faster agents. To minimize training time in heterogeneous environments, we present a Communication-Efficient Training Workload Balancing for Decentralized Multi-Agent Learning (ComDML), which balances the workload among agents through a decentralized approach. Leveraging local-loss split training, ComDML enables parallel updates, where slower agents offload part of their workload to faster agents. To minimize the overall training time, ComDML optimizes the workload balancing by jointly considering the communication and computation capacities of agents, which hinges upon integer programming. A dynamic decentralized pairing scheduler is developed to efficiently pair agents and determine optimal offloading amounts. We prove that in ComDML, both slower and faster agents' models converge, for convex and non-convex functions. Furthermore, extensive experimental results on popular datasets (CIFAR-10, CIFAR-100, and CINIC-10) and their non-I.I.D. variants, with large models such as ResNet-56 and ResNet-110, demonstrate that ComDML can significantly reduce the overall training time while maintaining model accuracy, compared to state-of-the-art methods. ComDML demonstrates robustness in heterogeneous environments, and privacy measures can be seamlessly integrated for enhanced data protection.
Create account to get full access
Overview
- The paper proposes a communication-efficient training workload balancing approach for decentralized multi-agent learning
- Key ideas include federated learning, edge computing, and heterogeneous agents
- The goal is to improve training efficiency by balancing workloads and reducing communication overhead
Plain English Explanation
This research paper focuses on a communication-efficient approach to training decentralized multi-agent learning systems. In these systems, multiple autonomous agents collaborate to learn a shared model, but they may have different computational capabilities and be located in different physical locations.
The researchers recognized that effectively distributing the training workload across these heterogeneous agents is crucial for efficient learning. Their proposed method aims to balance the workload while minimizing the amount of communication required between agents. This is important because excessive communication can slow down the training process and limit the scalability of the system.
The approach leverages concepts from federated learning and edge computing, allowing agents to perform local computations and only share essential information. This helps reduce the overall communication overhead and makes the system more resilient to network issues or agent failures.
By carefully managing the workload distribution and communication patterns, the researchers believe they can achieve more efficient training for decentralized multi-agent learning systems. This could have applications in areas like collaborative optimization of wireless communication and computing resources, distributed iterative training of deep learning models, and other settings where distributed, communication-constrained learning is required.
Technical Explanation
The paper presents a communication-efficient training workload balancing approach for decentralized multi-agent learning. The key idea is to distribute the training workload across heterogeneous agents while minimizing the amount of communication required between them.
The proposed method leverages concepts from federated learning and edge computing. Agents perform local computations on their own data, and they only share essential information with the other agents, rather than transmitting the entire model or dataset. This helps reduce the overall communication overhead and makes the system more robust to network issues or agent failures.
The authors develop a mathematical formulation to model the training process and the communication costs. They then propose an optimization-based approach to determine the optimal workload distribution and communication patterns. The goal is to minimize the training time while staying within the communication budget.
The researchers evaluate their approach through extensive simulations and compare it to alternative methods. They demonstrate that their technique can achieve significant improvements in training efficiency, especially in scenarios with heterogeneous agents and limited communication resources.
Critical Analysis
The paper presents a well-designed and thorough approach to addressing the challenge of communication-efficient training in decentralized multi-agent learning systems. The researchers have clearly identified a relevant problem and developed a sophisticated solution that leverages key concepts from federated learning and edge computing.
One potential area for further research is the scalability of the proposed method. While the simulations show promising results, it would be valuable to assess the performance of the approach in larger-scale, real-world scenarios with hundreds or thousands of agents. The computational complexity of the optimization algorithm may become a limiting factor as the system grows in size.
Additionally, the paper does not fully explore the robustness of the approach to factors such as agent failures, data drift, or changes in the network topology. Incorporating mechanisms to handle these dynamic conditions could further improve the practical applicability of the method.
Finally, the authors could provide more insights into the tradeoffs and design choices involved in their approach. For example, a deeper discussion of the impact of different communication budgets or the sensitivity of the results to the choice of hyperparameters could help readers better understand the strengths and limitations of the proposed technique.
Overall, the research presented in this paper represents a valuable contribution to the field of decentralized multi-agent learning, and the ideas and techniques could have significant implications for a wide range of applications where communication-efficient distributed learning is required.
Conclusion
This research paper introduces a communication-efficient training workload balancing approach for decentralized multi-agent learning systems. The key innovation is the ability to distribute the training workload across heterogeneous agents while minimizing the communication overhead, leveraging concepts from federated learning and edge computing.
The proposed method has the potential to significantly improve the efficiency and scalability of decentralized learning systems, which are increasingly important in a wide range of applications, from collaborative optimization of wireless and computing resources to distributed training of deep learning models. By carefully managing the workload distribution and communication patterns, the researchers demonstrate that they can achieve faster training times and more robust performance, even in the face of constrained communication resources and heterogeneous agent capabilities.
While the paper presents a strong technical foundation and promising results, further research is needed to fully explore the scalability and robustness of the approach in real-world scenarios. Nonetheless, this work represents an important step forward in the field of decentralized multi-agent learning and could have significant implications for the development of efficient, communication-constrained distributed learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Communication-Efficient Large-Scale Distributed Deep Learning: A Comprehensive Survey
Feng Liang, Zhen Zhang, Haifeng Lu, Victor C. M. Leung, Yanyi Guo, Xiping Hu
0
0
With the rapid growth in the volume of data sets, models, and devices in the domain of deep learning, there is increasing attention on large-scale distributed deep learning. In contrast to traditional distributed deep learning, the large-scale scenario poses new challenges that include fault tolerance, scalability of algorithms and infrastructures, and heterogeneity in data sets, models, and resources. Due to intensive synchronization of models and sharing of data across GPUs and computing nodes during distributed training and inference processes, communication efficiency becomes the bottleneck for achieving high performance at a large scale. This article surveys the literature over the period of 2018-2023 on algorithms and technologies aimed at achieving efficient communication in large-scale distributed deep learning at various levels, including algorithms, frameworks, and infrastructures. Specifically, we first introduce efficient algorithms for model synchronization and communication data compression in the context of large-scale distributed training. Next, we introduce efficient strategies related to resource allocation and task scheduling for use in distributed training and inference. After that, we present the latest technologies pertaining to modern communication infrastructures used in distributed deep learning with a focus on examining the impact of the communication overhead in a large-scale and heterogeneous setting. Finally, we conduct a case study on the distributed training of large language models at a large scale to illustrate how to apply these technologies in real cases. This article aims to offer researchers a comprehensive understanding of the current landscape of large-scale distributed deep learning and to reveal promising future research directions toward communication-efficient solutions in this scope.
4/10/2024

Communication-Efficient and Privacy-Preserving Decentralized Meta-Learning
Hansi Yang, James T. Kwok
0
0
Distributed learning, which does not require gathering training data in a central location, has become increasingly important in the big-data era. In particular, random-walk-based decentralized algorithms are flexible in that they do not need a central server trusted by all clients and do not require all clients to be active in all iterations. However, existing distributed learning algorithms assume that all learning clients share the same task. In this paper, we consider the more difficult meta-learning setting, in which different clients perform different (but related) tasks with limited training data. To reduce communication cost and allow better privacy protection, we propose LoDMeta (Local Decentralized Meta-learning) with the use of local auxiliary optimization parameters and random perturbations on the model parameter. Theoretical results are provided on both convergence and privacy analysis. Empirical results on a number of few-shot learning data sets demonstrate that LoDMeta has similar meta-learning accuracy as centralized meta-learning algorithms, but does not require gathering data from each client and is able to better protect data privacy for each client.
6/21/2024
📈
A Communication- and Memory-Aware Model for Load Balancing Tasks
Jonathan Lifflander, Philippe P. Pebay, Nicole L. Slattengren, Pierre L. Pebay, Robert A. Pfeiffer, Joseph D. Kotulski, Sean T. McGovern
0
0
While load balancing in distributed-memory computing has been well-studied, we present an innovative approach to this problem: a unified, reduced-order model that combines three key components to describe work in a distributed system: computation, communication, and memory. Our model enables an optimizer to explore complex tradeoffs in task placement, such as increased parallelism at the expense of data replication, which increases memory usage. We propose a fully distributed, heuristic-based load balancing optimization algorithm, and demonstrate that it quickly finds close-to-optimal solutions. We formalize the complex optimization problem as a mixed-integer linear program, and compare it to our strategy. Finally, we show that when applied to an electromagnetics code, our approach obtains up to 2.3x speedups for the imbalanced execution.
4/26/2024
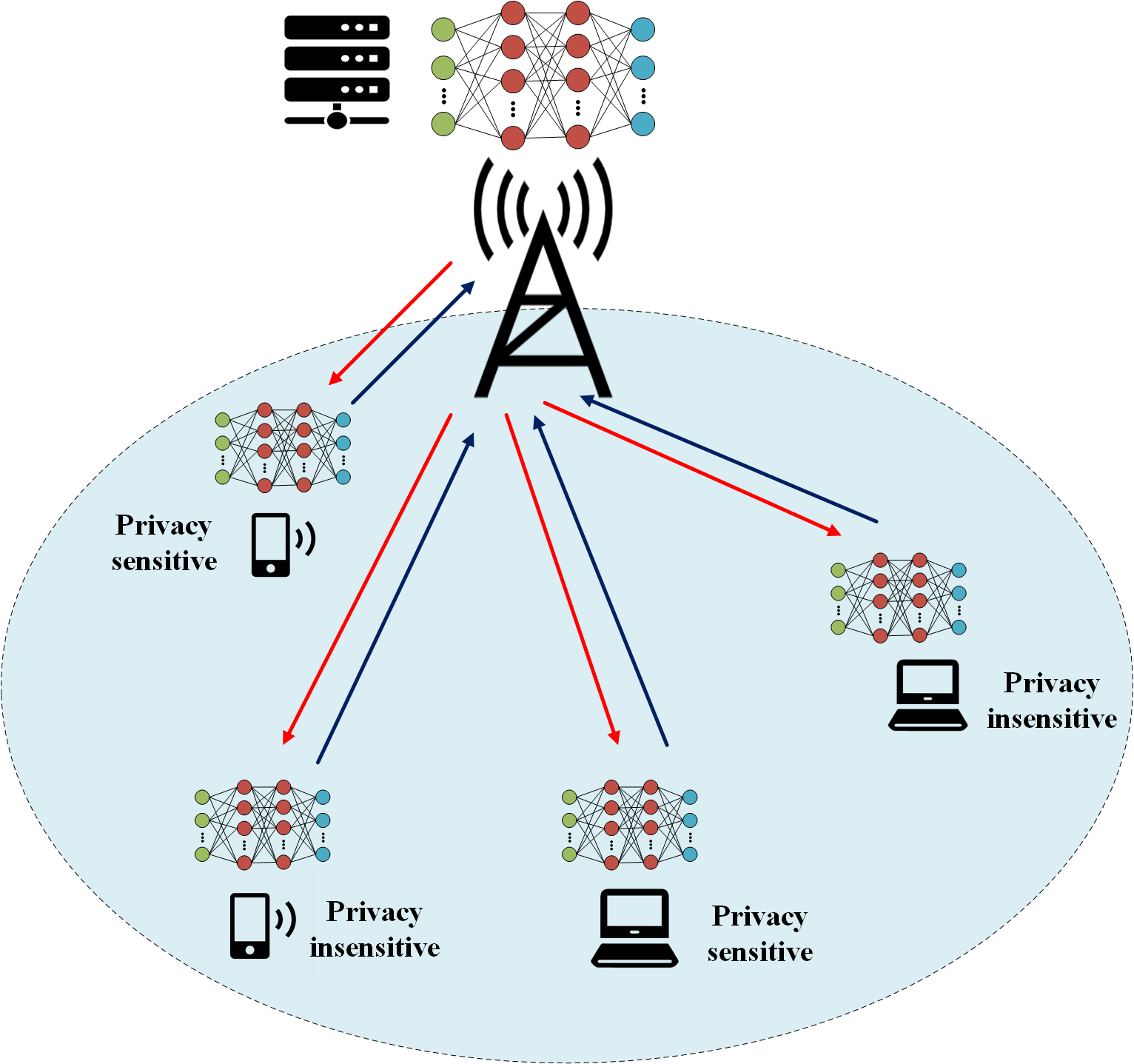
Collaborative Optimization of Wireless Communication and Computing Resource Allocation based on Multi-Agent Federated Weighting Deep Reinforcement Learning
Junjie Wu, Xuming Fang
0
0
As artificial intelligence (AI)-enabled wireless communication systems continue their evolution, distributed learning has gained widespread attention for its ability to offer enhanced data privacy protection, improved resource utilization, and enhanced fault tolerance within wireless communication applications. Federated learning further enhances the ability of resource coordination and model generalization across nodes based on the above foundation, enabling the realization of an AI-driven communication and computing integrated wireless network. This paper proposes a novel wireless communication system to cater to a personalized service needs of both privacy-sensitive and privacy-insensitive users. We design the system based on based on multi-agent federated weighting deep reinforcement learning (MAFWDRL). The system, while fulfilling service requirements for users, facilitates real-time optimization of local communication resources allocation and concurrent decision-making concerning computing resources. Additionally, exploration noise is incorporated to enhance the exploration process of off-policy deep reinforcement learning (DRL) for wireless channels. Federated weighting (FedWgt) effectively compensates for heterogeneous differences in channel status between communication nodes. Extensive simulation experiments demonstrate that the proposed scheme outperforms baseline methods significantly in terms of throughput, calculation latency, and energy consumption improvement.
4/3/2024