Comparing supervised learning dynamics: Deep neural networks match human data efficiency but show a generalisation lag

0
👨🏫
Sign in to get full access
Overview
- Compares the learning dynamics of deep neural networks (DNNs) and human observers in image classification tasks
- Focuses on the process of how object category representations emerge, rather than just the final performance
- Develops a constrained supervised learning environment to align the learning conditions between DNNs and humans
- Evaluates and compares how well the learned representations can be generalized to previously unseen test data across the entire learning process
Plain English Explanation
This research paper looks at how the way deep neural networks and humans learn to classify images is similar and different. Often, studies just compare the final performance of DNNs and humans on image classification tasks. But this paper digs deeper into the
The researchers set up a controlled learning environment where both DNNs and human participants learned to classify images. They matched the starting conditions, the input data, and the feedback provided to make the learning process as similar as possible between the two. Then, they tracked how well the learned representations could be applied to new, unseen images throughout the entire learning process.
The results show that DNNs can be just as
Technical Explanation
The researchers developed a constrained supervised learning environment to directly compare the learning dynamics of DNNs and human observers. They aligned the starting conditions, input modality (images), available training data, and feedback provided to ensure the learning-relevant factors were matched as closely as possible.
Across the entire learning process, the team evaluated how well the learned representations could be generalized to previously unseen test data. This allowed them to track and compare the emergence of object category representations in both DNNs and humans.
The results indicate that DNNs can demonstrate a level of data efficiency comparable to human learners, challenging some common assumptions in the field. However, the paper also reveals key representational differences - while DNNs go through a "generalization lag" where they first learn task-specific representations before transferring that knowledge, humans appear to immediately acquire generalizable representations without that preliminary phase.
Critical Analysis
The paper provides a valuable contribution by directly comparing the learning dynamics of DNNs and humans, moving beyond just comparing final task performance. By aligning the learning conditions, the researchers were able to isolate differences in how the representations emerge over time.
That said, the study is limited to a specific image classification task and learning environment. It's unclear how generalizable the findings are to other domains or real-world learning scenarios. The paper also acknowledges that the human experiments only involved a small sample size, and future work should explore these dynamics with larger and more diverse populations.
Additionally, while the paper highlights interesting representational differences, it does not delve deeply into
Conclusion
This research represents an important step forward in understanding the similarities and differences in how DNNs and humans learn to classify visual information. By focusing on the
The findings have implications for developing AI systems that can learn as flexibly and efficiently as humans, as well as for understanding the relationship between biological and artificial neural networks. Continued research in this direction, exploring the underlying representations and evolutionary dynamics of learning, could lead to important advances in both cognitive science and artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👨🏫
0
Comparing supervised learning dynamics: Deep neural networks match human data efficiency but show a generalisation lag
Lukas S. Huber, Fred W. Mast, Felix A. Wichmann
Recent research has seen many behavioral comparisons between humans and deep neural networks (DNNs) in the domain of image classification. Often, comparison studies focus on the end-result of the learning process by measuring and comparing the similarities in the representations of object categories once they have been formed. However, the process of how these representations emerge -- that is, the behavioral changes and intermediate stages observed during the acquisition -- is less often directly and empirically compared. Here we report a detailed investigation of the learning dynamics in human observers and various classic and state-of-the-art DNNs. We develop a constrained supervised learning environment to align learning-relevant conditions such as starting point, input modality, available input data and the feedback provided. Across the whole learning process we evaluate and compare how well learned representations can be generalized to previously unseen test data. Comparisons across the entire learning process indicate that DNNs demonstrate a level of data efficiency comparable to human learners, challenging some prevailing assumptions in the field. However, our results also reveal representational differences: while DNNs' learning is characterized by a pronounced generalisation lag, humans appear to immediately acquire generalizable representations without a preliminary phase of learning training set-specific information that is only later transferred to novel data.
Read more7/15/2024
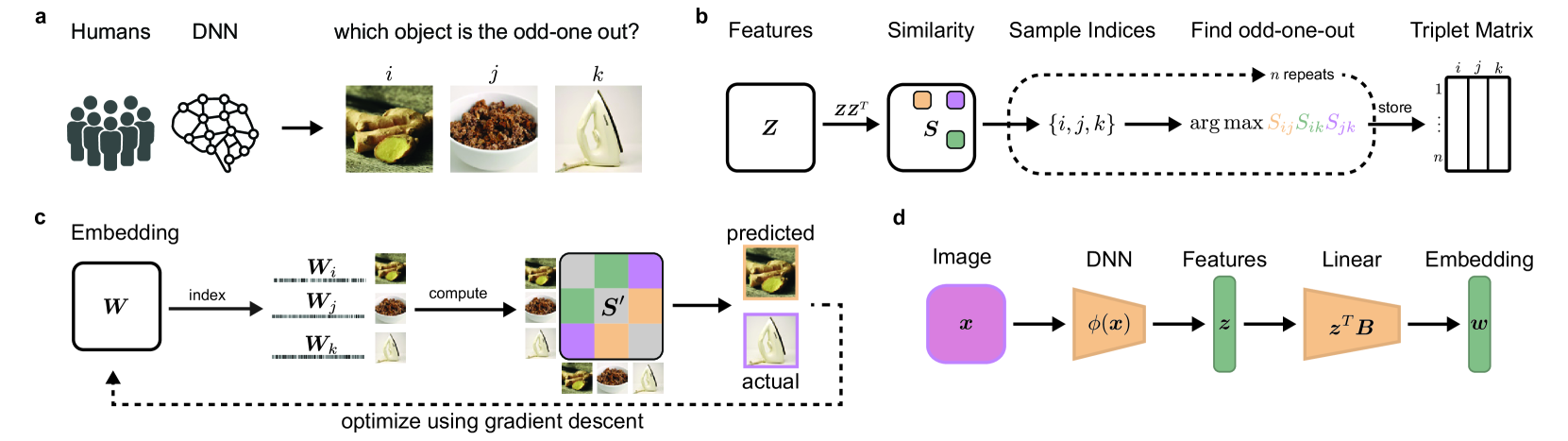
0
Dimensions underlying the representational alignment of deep neural networks with humans
Florian P. Mahner, Lukas Muttenthaler, Umut Guc{c}lu, Martin N. Hebart
Determining the similarities and differences between humans and artificial intelligence is an important goal both in machine learning and cognitive neuroscience. However, similarities in representations only inform us about the degree of alignment, not the factors that determine it. Drawing upon recent developments in cognitive science, we propose a generic framework for yielding comparable representations in humans and deep neural networks (DNN). Applying this framework to humans and a DNN model of natural images revealed a low-dimensional DNN embedding of both visual and semantic dimensions. In contrast to humans, DNNs exhibited a clear dominance of visual over semantic features, indicating divergent strategies for representing images. While in-silico experiments showed seemingly-consistent interpretability of DNN dimensions, a direct comparison between human and DNN representations revealed substantial differences in how they process images. By making representations directly comparable, our results reveal important challenges for representational alignment, offering a means for improving their comparability.
Read more6/28/2024
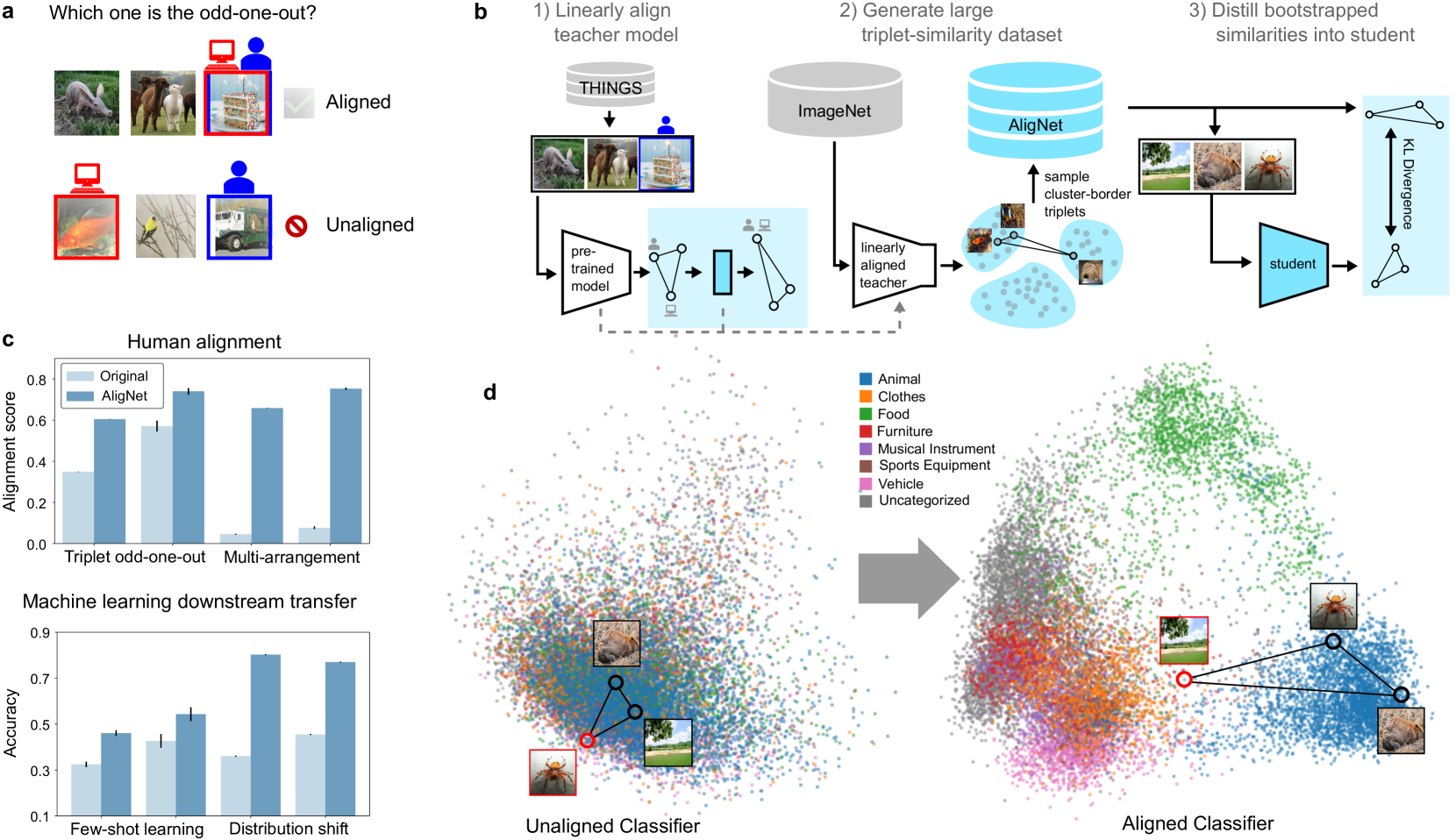
0
Aligning Machine and Human Visual Representations across Abstraction Levels
Lukas Muttenthaler, Klaus Greff, Frieda Born, Bernhard Spitzer, Simon Kornblith, Michael C. Mozer, Klaus-Robert Muller, Thomas Unterthiner, Andrew K. Lampinen
Deep neural networks have achieved success across a wide range of applications, including as models of human behavior in vision tasks. However, neural network training and human learning differ in fundamental ways, and neural networks often fail to generalize as robustly as humans do, raising questions regarding the similarity of their underlying representations. What is missing for modern learning systems to exhibit more human-like behavior? We highlight a key misalignment between vision models and humans: whereas human conceptual knowledge is hierarchically organized from fine- to coarse-scale distinctions, model representations do not accurately capture all these levels of abstraction. To address this misalignment, we first train a teacher model to imitate human judgments, then transfer human-like structure from its representations into pretrained state-of-the-art vision foundation models. These human-aligned models more accurately approximate human behavior and uncertainty across a wide range of similarity tasks, including a new dataset of human judgments spanning multiple levels of semantic abstractions. They also perform better on a diverse set of machine learning tasks, increasing generalization and out-of-distribution robustness. Thus, infusing neural networks with additional human knowledge yields a best-of-both-worlds representation that is both more consistent with human cognition and more practically useful, thus paving the way toward more robust, interpretable, and human-like artificial intelligence systems.
Read more9/11/2024

0
A comparison between humans and AI at recognizing objects in unusual poses
Netta Ollikka, Amro Abbas, Andrea Perin, Markku Kilpelainen, St'ephane Deny
Deep learning is closing the gap with human vision on several object recognition benchmarks. Here we investigate this gap for challenging images where objects are seen in unusual poses. We find that humans excel at recognizing objects in such poses. In contrast, state-of-the-art deep networks for vision (EfficientNet, SWAG, ViT, SWIN, BEiT, ConvNext) and state-of-the-art large vision-language models (Claude 3.5, Gemini 1.5, GPT-4) are systematically brittle on unusual poses, with the exception of Gemini showing excellent robustness in that condition. As we limit image exposure time, human performance degrades to the level of deep networks, suggesting that additional mental processes (requiring additional time) are necessary to identify objects in unusual poses. An analysis of error patterns of humans vs. networks reveals that even time-limited humans are dissimilar to feed-forward deep networks. In conclusion, our comparison reveals that humans and deep networks rely on different mechanisms for recognizing objects in unusual poses. Understanding the nature of the mental processes taking place during extra viewing time may be key to reproduce the robustness of human vision in silico.
Read more8/30/2024