Complexity-Aware Deep Symbolic Regression with Robust Risk-Seeking Policy Gradients

0
Sign in to get full access
Overview
- This paper presents a novel approach to deep symbolic regression that aims to learn complex mathematical expressions while considering their complexity.
- It introduces a robust risk-seeking policy gradient method to guide the search towards more expressive and interpretable models.
- The proposed technique is evaluated on a range of benchmark problems and compared to existing symbolic regression algorithms.
Plain English Explanation
The paper describes a new way to automatically discover mathematical equations from data. This is called "symbolic regression," and it's useful for modeling complex phenomena in science and engineering.
The key innovation is the use of a "risk-seeking" approach to guide the search for equations. Normally, symbolic regression algorithms try to find the simplest equation that fits the data well. But this paper argues that sometimes more complex equations are needed to capture important patterns. The risk-seeking policy gradient method encourages the algorithm to explore more complex solutions, while still favoring those that fit the data.
This allows the algorithm to find mathematical expressions that are both accurate and interpretable - you can look at the equation and understand how it works, rather than just treating it as a black box. The paper shows that this complexity-aware approach outperforms existing symbolic regression methods on a variety of benchmark problems.
Technical Explanation
The paper introduces a new deep symbolic regression algorithm that aims to balance model accuracy and complexity. It builds on previous work in generative pre-trained transformer and context-aware symbolic regression, incorporating a robust risk-seeking policy gradient method to guide the search towards more expressive and interpretable models.
The key technical contributions include:
- A complexity-aware loss function that penalizes overly simple solutions, encouraging the model to explore more complex mathematical expressions.
- A novel risk-seeking policy gradient algorithm that biases the search towards solutions with higher complexity and accuracy, rather than just favoring the simplest model.
- Extensive empirical evaluation on a range of benchmark problems, comparing the proposed method to recent symbolic regression algorithms and demonstrating its superior performance.
The paper also discusses the importance of interpretable models in scientific and engineering applications, where understanding the underlying mathematical relationships is crucial.
Critical Analysis
The paper makes a strong case for the value of complexity-aware symbolic regression, showing that it can lead to more accurate and interpretable models than existing approaches. However, the authors acknowledge that the risk-seeking policy gradient method can be computationally more expensive and may require careful hyperparameter tuning.
Additionally, the paper does not explore the potential limitations of the proposed technique, such as its performance on very high-dimensional problems or its robustness to noisy or incomplete data. Further research would be needed to fully understand the strengths and weaknesses of this approach.
It would also be interesting to see how the complexity-aware symbolic regression method compares to other techniques for balancing model complexity and performance, such as regularization or multi-objective optimization.
Conclusion
This paper presents a novel approach to deep symbolic regression that aims to learn complex mathematical expressions while considering their interpretability. By incorporating a robust risk-seeking policy gradient method, the proposed algorithm is able to outperform existing symbolic regression techniques on a range of benchmark problems.
The complexity-aware approach developed in this work has the potential to significantly impact fields that rely on accurate and interpretable mathematical models, such as physics, chemistry, and engineering. Further research and real-world applications of this technique could lead to important scientific and technological advancements.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Complexity-Aware Deep Symbolic Regression with Robust Risk-Seeking Policy Gradients
Zachary Bastiani, Robert M. Kirby, Jacob Hochhalter, Shandian Zhe
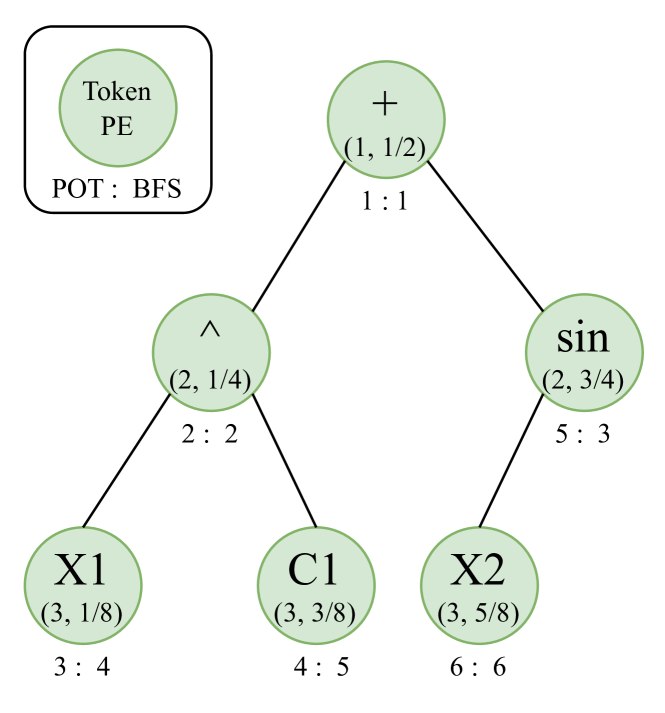
This paper proposes a novel deep symbolic regression approach to enhance the robustness and interpretability of data-driven mathematical expression discovery. Despite the success of the state-of-the-art method, DSR, it is built on recurrent neural networks, purely guided by data fitness, and potentially meet tail barriers, which can zero out the policy gradient and cause inefficient model updates. To overcome these limitations, we use transformers in conjunction with breadth-first-search to improve the learning performance. We use Bayesian information criterion (BIC) as the reward function to explicitly account for the expression complexity and optimize the trade-off between interpretability and data fitness. We propose a modified risk-seeking policy that not only ensures the unbiasness of the gradient, but also removes the tail barriers, thus ensuring effective updates from top performers. Through a series of benchmarks and systematic experiments, we demonstrate the advantages of our approach.
Read more6/12/2024
🌐
0
A Neural-Guided Dynamic Symbolic Network for Exploring Mathematical Expressions from Data
Wenqiang Li, Weijun Li, Lina Yu, Min Wu, Linjun Sun, Jingyi Liu, Yanjie Li, Shu Wei, Yusong Deng, Meilan Hao
Symbolic regression (SR) is a powerful technique for discovering the underlying mathematical expressions from observed data. Inspired by the success of deep learning, recent deep generative SR methods have shown promising results. However, these methods face difficulties in processing high-dimensional problems and learning constants due to the large search space, and they don't scale well to unseen problems. In this work, we propose DySymNet, a novel neural-guided Dynamic Symbolic Network for SR. Instead of searching for expressions within a large search space, we explore symbolic networks with various structures, guided by reinforcement learning, and optimize them to identify expressions that better-fitting the data. Based on extensive numerical experiments on low-dimensional public standard benchmarks and the well-known SRBench with more variables, DySymNet shows clear superiority over several representative baseline models. Open source code is available at https://github.com/AILWQ/DySymNet.
Read more6/4/2024
0
Generative Pre-Trained Transformer for Symbolic Regression Base In-Context Reinforcement Learning
Yanjie Li, Weijun Li, Lina Yu, Min Wu, Jingyi Liu, Wenqiang Li, Meilan Hao, Shu Wei, Yusong Deng
The mathematical formula is the human language to describe nature and is the essence of scientific research. Finding mathematical formulas from observational data is a major demand of scientific research and a major challenge of artificial intelligence. This area is called symbolic regression. Originally symbolic regression was often formulated as a combinatorial optimization problem and solved using GP or reinforcement learning algorithms. These two kinds of algorithms have strong noise robustness ability and good Versatility. However, inference time usually takes a long time, so the search efficiency is relatively low. Later, based on large-scale pre-training data proposed, such methods use a large number of synthetic data points and expression pairs to train a Generative Pre-Trained Transformer(GPT). Then this GPT can only need to perform one forward propagation to obtain the results, the advantage is that the inference speed is very fast. However, its performance is very dependent on the training data and performs poorly on data outside the training set, which leads to poor noise robustness and Versatility of such methods. So, can we combine the advantages of the above two categories of SR algorithms? In this paper, we propose textbf{FormulaGPT}, which trains a GPT using massive sparse reward learning histories of reinforcement learning-based SR algorithms as training data. After training, the SR algorithm based on reinforcement learning is distilled into a Transformer. When new test data comes, FormulaGPT can directly generate a reinforcement learning process and automatically update the learning policy in context. Tested on more than ten datasets including SRBench, formulaGPT achieves the state-of-the-art performance in fitting ability compared with four baselines. In addition, it achieves satisfactory results in noise robustness, versatility, and inference efficiency.
Read more4/10/2024

0
SymbolNet: Neural Symbolic Regression with Adaptive Dynamic Pruning
Ho Fung Tsoi, Vladimir Loncar, Sridhara Dasu, Philip Harris
Contrary to genetic programming, the neural network approach to symbolic regression can efficiently handle high-dimensional inputs and leverage gradient methods for faster equation searching. Common ways of constraining expression complexity often involve multistage pruning with fine-tuning, which can result in significant performance loss. In this work, we propose $tt{SymbolNet}$, a neural network approach to symbolic regression in a novel framework that allows dynamic pruning of model weights, input features, and mathematical operators in a single training process, where both training loss and expression complexity are optimized simultaneously. We introduce a sparsity regularization term for each pruning type, which can adaptively adjust its strength, leading to convergence at a target sparsity ratio. Unlike most existing symbolic regression methods that struggle with datasets containing more than $mathcal{O}(10)$ inputs, we demonstrate the effectiveness of our model on the LHC jet tagging task (16 inputs), MNIST (784 inputs), and SVHN (3072 inputs). Our approach enables symbolic regression to achieve fast inference with nanosecond-scale latency on FPGAs for high-dimensional datasets in environments with stringent computational resource constraints, such as the high-energy physics experiments at the LHC.
Read more8/15/2024