Composite Distributed Learning and Synchronization of Nonlinear Multi-Agent Systems with Complete Uncertain Dynamics
2403.00987
0
0
Abstract
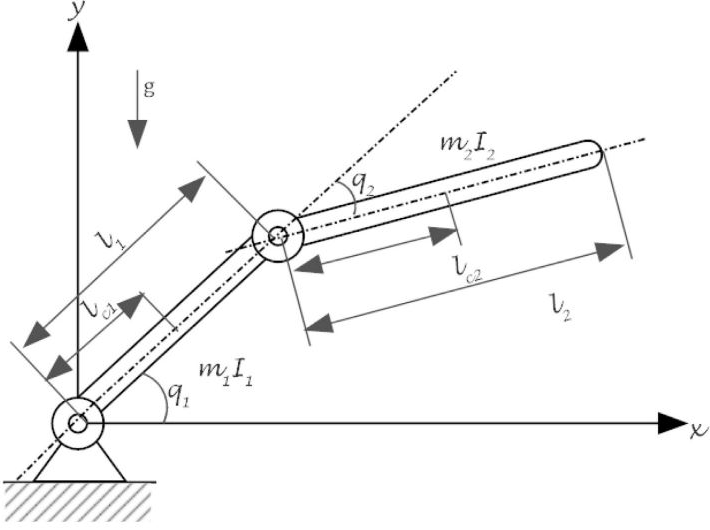
This paper addresses the problem of composite synchronization and learning control in a network of multi-agent robotic manipulator systems with heterogeneous nonlinear uncertainties under a leader-follower framework. A novel two-layer distributed adaptive learning control strategy is introduced, comprising a first-layer distributed cooperative estimator and a second-layer decentralized deterministic learning controller. The first layer is to facilitate each robotic agent's estimation of the leader's information. The second layer is responsible for both controlling individual robot agents to track desired reference trajectories and accurately identifying/learning their nonlinear uncertain dynamics. The proposed distributed learning control scheme represents an advancement in the existing literature due to its ability to manage robotic agents with completely uncertain dynamics including uncertain mass matrices. This allows the robotic control to be environment-independent which can be used in various settings, from underwater to space where identifying system dynamics parameters is challenging. The stability and parameter convergence of the closed-loop system are rigorously analyzed using the Lyapunov method. Numerical simulations validate the effectiveness of the proposed scheme.
Create account to get full access
Overview
- This paper proposes a composite distributed learning and synchronization framework for nonlinear multi-agent systems with complete uncertain dynamics.
- The framework combines distributed learning and synchronization to achieve coordinated behavior among agents with unknown dynamics.
- The approach uses neural networks to approximate the unknown dynamics and a distributed synchronization protocol to coordinate the agents.
- Theoretical analysis and simulation results demonstrate the effectiveness of the proposed framework in achieving consensus and tracking desired trajectories.
Plain English Explanation
In this paper, the researchers developed a new way for groups of interconnected robots or "agents" to work together, even when the inner workings of each agent are completely unknown. This is a common challenge in multi-agent systems, where you have many autonomous agents that need to coordinate their actions.
The key idea is to combine two important techniques: distributed learning and synchronization. Distributed learning allows each agent to independently learn its own unknown dynamics using neural networks. Meanwhile, the synchronization protocol helps the agents coordinate their behavior and reach a consensus, even though they don't know the details of each other's inner workings.
This composite approach has several advantages. It can handle agents with completely unknown and potentially nonlinear dynamics, which is a more realistic scenario than assuming the agents have perfect models of their dynamics. Additionally, the distributed nature of the framework allows the agents to learn and synchronize in a decentralized way, without relying on a central controller.
The researchers provided theoretical analysis and simulations to demonstrate that their framework can effectively achieve consensus and trajectory tracking for the multi-agent system, even with the complete uncertainty in the agent dynamics. This work could have important implications for the design of robust and adaptive multi-agent systems, such as swarm robotics or distributed autonomous systems.
Technical Explanation
The paper presents a composite distributed learning and synchronization framework for nonlinear multi-agent systems with completely uncertain dynamics. The key elements of the proposed approach are:
-
Distributed Learning: Each agent uses a neural network to approximate its own unknown dynamics. This avoids the need for precise mathematical models of the agent dynamics, which can be difficult to obtain in practice.
-
Distributed Synchronization: The agents follow a distributed synchronization protocol to coordinate their behavior and reach a consensus, despite the lack of knowledge about each other's dynamics.
The researchers provide a theoretical analysis to prove the convergence and stability properties of the proposed framework. This includes establishing bounds on the learning error and synchronization error, as well as showing that the agents can track desired trajectories.
Simulation results are presented to validate the effectiveness of the approach. The simulations demonstrate the agents' ability to reach consensus and track reference trajectories, even when the agent dynamics are completely unknown and potentially nonlinear.
Critical Analysis
The paper makes a valuable contribution by addressing the challenge of coordinating multi-agent systems with completely uncertain dynamics, which is a common scenario in real-world applications. The proposed composite framework that combines distributed learning and synchronization is a novel and promising approach.
One potential limitation of the work is that it assumes the agents have access to their own state information, which may not always be the case in practical settings. Additionally, the theoretical analysis assumes some simplifying assumptions, such as the availability of a common reference trajectory, which may not hold in more general scenarios.
Further research could explore extending the framework to handle more complex scenarios, such as distributionally robust policies or safety-critical control. Investigating the scalability of the approach as the number of agents increases would also be an important area for future work.
Conclusion
This paper presents a novel composite distributed learning and synchronization framework for coordinating the behavior of nonlinear multi-agent systems with completely uncertain dynamics. By combining distributed learning and synchronization, the proposed approach can achieve consensus and trajectory tracking without requiring precise models of the agent dynamics.
The theoretical analysis and simulation results demonstrate the effectiveness of the framework, which could have important implications for the design of robust and adaptive multi-agent systems. Further research could explore extensions and address potential limitations, ultimately contributing to the advancement of this important area of multi-agent coordination and control.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Learning Hierarchical Control For Multi-Agent Capacity-Constrained Systems
Charlott Vallon, Alessandro Pinto, Bartolomeo Stellato, Francesco Borrelli
0
0
This paper introduces a novel data-driven hierarchical control scheme for managing a fleet of nonlinear, capacity-constrained autonomous agents in an iterative environment. We propose a control framework consisting of a high-level dynamic task assignment and routing layer and low-level motion planning and tracking layer. Each layer of the control hierarchy uses a data-driven Model Predictive Control (MPC) policy, maintaining bounded computational complexity at each calculation of a new task assignment or actuation input. We utilize collected data to iteratively refine estimates of agent capacity usage, and update MPC policy parameters accordingly. Our approach leverages tools from iterative learning control to integrate learning at both levels of the hierarchy, and coordinates learning between levels in order to maintain closed-loop feasibility and performance improvement of the connected architecture.
4/12/2024

Distributed Motion Control of Multiple Mobile Manipulator System with Disturbance and Communication Delay
Wenhang Liu, Meng Ren, Kun Song, Michael Yu Wang, Zhenhua Xiong
0
0
In real-world object manipulation scenarios, multiple mobile manipulator systems may suffer from disturbances and asynchrony, leading to excessive interaction forces and causing object damage or emergency stops. This paper presents a novel distributed motion control approach aimed at reducing these unnecessary interaction forces. The control strategy only utilizes force information without the need for global position and velocity information. Disturbances are corrected through compensatory movements of the manipulators. Besides, the asymmetric, non-uniform, and time-varying communication delays between robots are also considered. The stability of the control law is rigorously proven by the Lyapunov theorem. Subsequently, the efficacy of the proposed control law is validated through simulations and experiments of collaborative object transportation by two robots. Experimental results demonstrate the effectiveness of the proposed control law in reducing interaction forces during object manipulation.
6/11/2024

Auto-Multilift: Distributed Learning and Control for Cooperative Load Transportation With Quadrotors
Bingheng Wang, Kuankuan Sima, Rui Huang, Lin Zhao
0
0
Designing motion control and planning algorithms for multilift systems remains challenging due to the complexities of dynamics, collision avoidance, actuator limits, and scalability. Existing methods that use optimization and distributed techniques effectively address these constraints and scalability issues. However, they often require substantial manual tuning, leading to suboptimal performance. This paper proposes Auto-Multilift, a novel framework that automates the tuning of model predictive controllers (MPCs) for multilift systems. We model the MPC cost functions with deep neural networks (DNNs), enabling fast online adaptation to various scenarios. We develop a distributed policy gradient algorithm to train these DNNs efficiently in a closed-loop manner. Central to our algorithm is distributed sensitivity propagation, which parallelizes gradient computation across quadrotors, focusing on actual system state sensitivities relative to key MPC parameters. We also provide theoretical guarantees for the convergence of this algorithm. Extensive simulations show rapid convergence and favorable scalability to a large number of quadrotors. Our method outperforms a state-of-the-art open-loop MPC tuning approach by effectively learning adaptive MPCs from trajectory tracking errors and handling the unique dynamics couplings within the multilift system. Additionally, our framework can learn an adaptive reference for reconfigurating the system when traversing through multiple narrow slots.
6/10/2024
Learning to Boost the Performance of Stable Nonlinear Systems
Luca Furieri, Clara Luc'ia Galimberti, Giancarlo Ferrari-Trecate
0
0
The growing scale and complexity of safety-critical control systems underscore the need to evolve current control architectures aiming for the unparalleled performances achievable through state-of-the-art optimization and machine learning algorithms. However, maintaining closed-loop stability while boosting the performance of nonlinear control systems using data-driven and deep-learning approaches stands as an important unsolved challenge. In this paper, we tackle the performance-boosting problem with closed-loop stability guarantees. Specifically, we establish a synergy between the Internal Model Control (IMC) principle for nonlinear systems and state-of-the-art unconstrained optimization approaches for learning stable dynamics. Our methods enable learning over arbitrarily deep neural network classes of performance-boosting controllers for stable nonlinear systems; crucially, we guarantee Lp closed-loop stability even if optimization is halted prematurely, and even when the ground-truth dynamics are unknown, with vanishing conservatism in the class of stabilizing policies as the model uncertainty is reduced to zero. We discuss the implementation details of the proposed control schemes, including distributed ones, along with the corresponding optimization procedures, demonstrating the potential of freely shaping the cost functions through several numerical experiments.
5/3/2024