A Comprehensive Survey on Self-Supervised Learning for Recommendation
2404.03354
0
0

Abstract
Recommender systems play a crucial role in tackling the challenge of information overload by delivering personalized recommendations based on individual user preferences. Deep learning techniques, such as RNNs, GNNs, and Transformer architectures, have significantly propelled the advancement of recommender systems by enhancing their comprehension of user behaviors and preferences. However, supervised learning methods encounter challenges in real-life scenarios due to data sparsity, resulting in limitations in their ability to learn representations effectively. To address this, self-supervised learning (SSL) techniques have emerged as a solution, leveraging inherent data structures to generate supervision signals without relying solely on labeled data. By leveraging unlabeled data and extracting meaningful representations, recommender systems utilizing SSL can make accurate predictions and recommendations even when confronted with data sparsity. In this paper, we provide a comprehensive review of self-supervised learning frameworks designed for recommender systems, encompassing a thorough analysis of over 170 papers. We conduct an exploration of nine distinct scenarios, enabling a comprehensive understanding of SSL-enhanced recommenders in different contexts. For each domain, we elaborate on different self-supervised learning paradigms, namely contrastive learning, generative learning, and adversarial learning, so as to present technical details of how SSL enhances recommender systems in various contexts. We consistently maintain the related open-source materials at https://github.com/HKUDS/Awesome-SSLRec-Papers.
Create account to get full access
Overview
- This paper provides a comprehensive survey on self-supervised learning (SSL) techniques for recommendation systems.
- SSL is an approach that allows models to learn useful representations from data without the need for manual labeling.
- The survey covers various SSL methods and their applications in different recommendation domains, highlighting the benefits and challenges of using SSL for recommendation.
Plain English Explanation
Self-supervised learning (SSL) is a technique that allows machine learning models to learn useful information from data without the need for manual labeling. In the context of recommendation systems, SSL can be used to help the model understand the patterns and relationships in the data, which can then be used to make better recommendations.
The paper surveys a wide range of SSL methods and how they have been applied to different recommendation domains, such as predicting gradient is better, contrastive credibility propagation, personalized recommendation via prompting large language models, and autonomous agents. The authors highlight the benefits of using SSL, such as the ability to learn from large amounts of unlabeled data and the potential to improve the performance of recommendation systems. They also discuss the challenges and limitations of SSL for recommendation, such as the need to design appropriate pretext tasks and the potential for overfitting.
Technical Explanation
The paper provides a comprehensive survey on the use of self-supervised learning (SSL) techniques for recommendation systems. SSL is a machine learning approach that allows models to learn useful representations from data without the need for manual labeling. In the context of recommendation, SSL can be used to help the model understand the underlying patterns and relationships in the data, which can then be leveraged to make better recommendations.
The authors cover a wide range of SSL methods and how they have been applied to different recommendation domains, such as predicting gradient is better, contrastive credibility propagation, personalized recommendation via prompting large language models, and autonomous agents. The paper discusses the various pretext tasks, architectures, and training strategies used in these SSL-based recommendation systems, as well as the performance gains and insights obtained from these approaches.
Critical Analysis
The paper provides a comprehensive and well-structured survey of SSL techniques for recommendation systems, highlighting both the benefits and challenges of using SSL in this domain. The authors acknowledge that while SSL can help learn useful representations from large amounts of unlabeled data, there is a need to carefully design pretext tasks that are well-aligned with the end recommendation task. Additionally, the authors note that overfitting to the pretext task is a potential issue that needs to be addressed.
One area that could be further explored is the cross-domain sequential recommendation problem, where SSL techniques could potentially be leveraged to learn representations that capture the underlying patterns and dependencies across different domains. The paper could also discuss the ethical considerations and potential biases that may arise from the use of SSL in recommendation systems.
Conclusion
This survey paper provides a comprehensive overview of the use of self-supervised learning (SSL) techniques for recommendation systems. The authors highlight the benefits of SSL, such as the ability to learn from large amounts of unlabeled data and the potential to improve recommendation performance. They also discuss the various SSL methods and their applications in different recommendation domains, as well as the challenges and limitations of using SSL for recommendation. The paper serves as a valuable resource for researchers and practitioners interested in exploring the use of SSL in the context of recommendation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
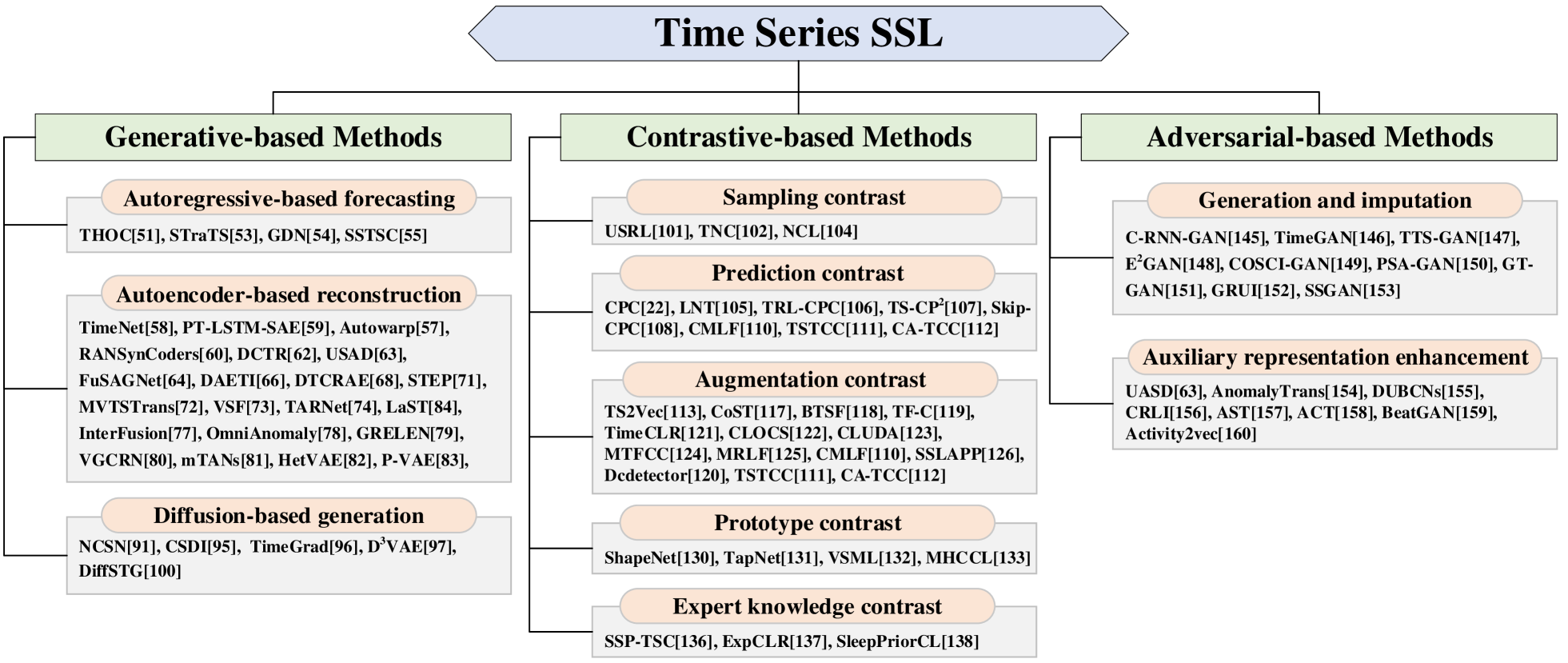
Self-Supervised Learning for Time Series Analysis: Taxonomy, Progress, and Prospects
Kexin Zhang, Qingsong Wen, Chaoli Zhang, Rongyao Cai, Ming Jin, Yong Liu, James Zhang, Yuxuan Liang, Guansong Pang, Dongjin Song, Shirui Pan
0
0
Self-supervised learning (SSL) has recently achieved impressive performance on various time series tasks. The most prominent advantage of SSL is that it reduces the dependence on labeled data. Based on the pre-training and fine-tuning strategy, even a small amount of labeled data can achieve high performance. Compared with many published self-supervised surveys on computer vision and natural language processing, a comprehensive survey for time series SSL is still missing. To fill this gap, we review current state-of-the-art SSL methods for time series data in this article. To this end, we first comprehensively review existing surveys related to SSL and time series, and then provide a new taxonomy of existing time series SSL methods by summarizing them from three perspectives: generative-based, contrastive-based, and adversarial-based. These methods are further divided into ten subcategories with detailed reviews and discussions about their key intuitions, main frameworks, advantages and disadvantages. To facilitate the experiments and validation of time series SSL methods, we also summarize datasets commonly used in time series forecasting, classification, anomaly detection, and clustering tasks. Finally, we present the future directions of SSL for time series analysis.
4/9/2024
🧠
SelfGNN: Self-Supervised Graph Neural Networks for Sequential Recommendation
Yuxi Liu, Lianghao Xia, Chao Huang
0
0
Sequential recommendation effectively addresses information overload by modeling users' temporal and sequential interaction patterns. To overcome the limitations of supervision signals, recent approaches have adopted self-supervised learning techniques in recommender systems. However, there are still two critical challenges that remain unsolved. Firstly, existing sequential models primarily focus on long-term modeling of individual interaction sequences, overlooking the valuable short-term collaborative relationships among the behaviors of different users. Secondly, real-world data often contain noise, particularly in users' short-term behaviors, which can arise from temporary intents or misclicks. Such noise negatively impacts the accuracy of both graph and sequence models, further complicating the modeling process. To address these challenges, we propose a novel framework called Self-Supervised Graph Neural Network (SelfGNN) for sequential recommendation. The SelfGNN framework encodes short-term graphs based on time intervals and utilizes Graph Neural Networks (GNNs) to learn short-term collaborative relationships. It captures long-term user and item representations at multiple granularity levels through interval fusion and dynamic behavior modeling. Importantly, our personalized self-augmented learning structure enhances model robustness by mitigating noise in short-term graphs based on long-term user interests and personal stability. Extensive experiments conducted on four real-world datasets demonstrate that SelfGNN outperforms various state-of-the-art baselines. Our model implementation codes are available at https://github.com/HKUDS/SelfGNN.
6/3/2024

A Probabilistic Model behind Self-Supervised Learning
Alice Bizeul, Bernhard Scholkopf, Carl Allen
0
0
In self-supervised learning (SSL), representations are learned via an auxiliary task without annotated labels. A common task is to classify augmentations or different modalities of the data, which share semantic content (e.g. an object in an image) but differ in style (e.g. the object's location). Many approaches to self-supervised learning have been proposed, e.g. SimCLR, CLIP, and VicREG, which have recently gained much attention for their representations achieving downstream performance comparable to supervised learning. However, a theoretical understanding of self-supervised methods eludes. Addressing this, we present a generative latent variable model for self-supervised learning and show that several families of discriminative SSL, including contrastive methods, induce a comparable distribution over representations, providing a unifying theoretical framework for these methods. The proposed model also justifies connections drawn to mutual information and the use of a projection head. Learning representations by fitting the model generatively (termed SimVAE) improves performance over discriminative and other VAE-based methods on simple image benchmarks and significantly narrows the gap between generative and discriminative representation learning in more complex settings. Importantly, as our analysis predicts, SimVAE outperforms self-supervised learning where style information is required, taking an important step toward understanding self-supervised methods and achieving task-agnostic representations.
6/5/2024
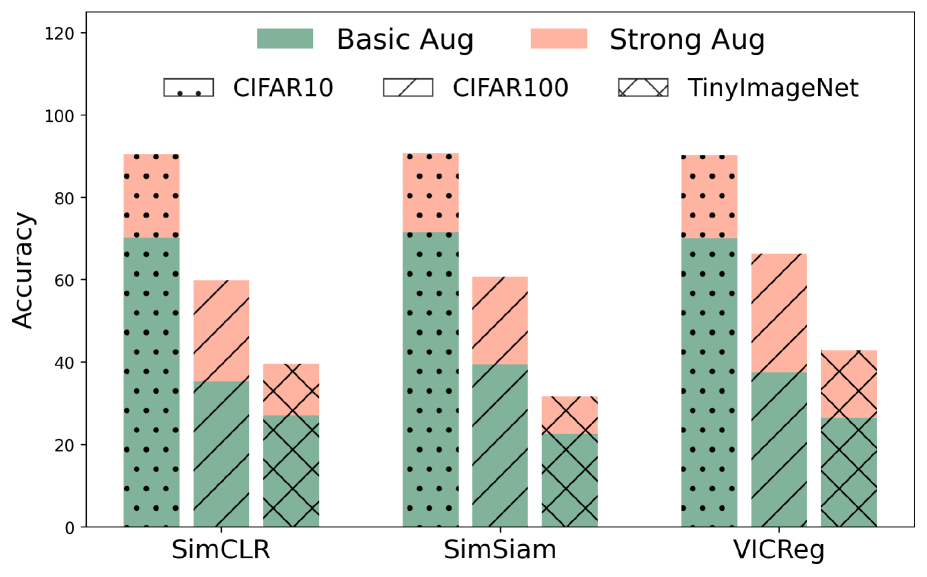
Can We Break Free from Strong Data Augmentations in Self-Supervised Learning?
Shruthi Gowda, Elahe Arani, Bahram Zonooz
0
0
Self-supervised learning (SSL) has emerged as a promising solution for addressing the challenge of limited labeled data in deep neural networks (DNNs), offering scalability potential. However, the impact of design dependencies within the SSL framework remains insufficiently investigated. In this study, we comprehensively explore SSL behavior across a spectrum of augmentations, revealing their crucial role in shaping SSL model performance and learning mechanisms. Leveraging these insights, we propose a novel learning approach that integrates prior knowledge, with the aim of curtailing the need for extensive data augmentations and thereby amplifying the efficacy of learned representations. Notably, our findings underscore that SSL models imbued with prior knowledge exhibit reduced texture bias, diminished reliance on shortcuts and augmentations, and improved robustness against both natural and adversarial corruptions. These findings not only illuminate a new direction in SSL research, but also pave the way for enhancing DNN performance while concurrently alleviating the imperative for intensive data augmentation, thereby enhancing scalability and real-world problem-solving capabilities.
4/16/2024