A Probabilistic Model behind Self-Supervised Learning
2402.01399
0
0

Abstract
In self-supervised learning (SSL), representations are learned via an auxiliary task without annotated labels. A common task is to classify augmentations or different modalities of the data, which share semantic content (e.g. an object in an image) but differ in style (e.g. the object's location). Many approaches to self-supervised learning have been proposed, e.g. SimCLR, CLIP, and VicREG, which have recently gained much attention for their representations achieving downstream performance comparable to supervised learning. However, a theoretical understanding of self-supervised methods eludes. Addressing this, we present a generative latent variable model for self-supervised learning and show that several families of discriminative SSL, including contrastive methods, induce a comparable distribution over representations, providing a unifying theoretical framework for these methods. The proposed model also justifies connections drawn to mutual information and the use of a projection head. Learning representations by fitting the model generatively (termed SimVAE) improves performance over discriminative and other VAE-based methods on simple image benchmarks and significantly narrows the gap between generative and discriminative representation learning in more complex settings. Importantly, as our analysis predicts, SimVAE outperforms self-supervised learning where style information is required, taking an important step toward understanding self-supervised methods and achieving task-agnostic representations.
Create account to get full access
Self-Supervised Representation Learning
Overview
- This paper presents a probabilistic model to explain the success of self-supervised representation learning techniques.
- Self-supervised learning aims to learn useful features from data without the need for labeled examples, which can be costly to obtain.
- The authors propose a generative model that can capture the underlying structure of the data and guide the learning of representations.
Plain English Explanation
Self-supervised learning is a powerful approach in machine learning that allows models to learn useful representations of data without the need for labeled examples. This is important because obtaining labeled data can be expensive and time-consuming. Instead, self-supervised models learn by discovering patterns and structure within the data itself.
The authors of this paper have developed a probabilistic model that can help explain how self-supervised learning works. Their model tries to capture the underlying structure of the data, and then uses this information to guide the learning of representations that are useful for downstream tasks, such as classification or prediction.
The key idea is that by modeling the data-generating process, the model can learn representations that are well-suited for the task at hand, without relying on labeled examples. This is similar to how humans learn - we draw upon our understanding of the world to make sense of new information, rather than needing to be explicitly taught everything.
The authors show that their probabilistic model can provide insights into the success of self-supervised learning techniques, and they demonstrate its effectiveness on several real-world datasets. This work helps to advance our understanding of how self-supervised learning works, and it could lead to the development of even more powerful and efficient machine learning models in the future.
Technical Explanation
The authors propose a probabilistic model to explain self-supervised representation learning. Their model is based on the idea that the data-generating process can be captured by a generative model, and that this information can be used to guide the learning of useful representations.
Specifically, the authors develop a variational autoencoder (VAE) that learns a latent representation of the data, along with a generative model that can reconstruct the original data from the latent representation. By optimizing the model to both learn a useful latent representation and accurately reconstruct the data, the authors show that the learned representations can be effectively used for downstream tasks, such as classification or prediction.
The authors also explore ways to refine the latent representations learned by the VAE, and they demonstrate the effectiveness of their approach on several real-world datasets in the context of self-supervised learning.
Critical Analysis
The authors provide a novel and insightful perspective on the success of self-supervised representation learning. By modeling the data-generating process, their approach offers a principled way to learn useful representations without the need for labeled data.
One potential limitation of the proposed model is that it may not be able to capture the full complexity of real-world data, particularly for high-dimensional or highly structured datasets. The authors acknowledge this challenge and suggest that further research is needed to address it.
Additionally, the authors do not extensively explore the limitations of their approach or compare it to other state-of-the-art self-supervised learning methods. It would be valuable to see a more comprehensive analysis of the strengths and weaknesses of the proposed model relative to other techniques.
Despite these minor concerns, the authors have made an important contribution to our understanding of self-supervised learning. Their work provides a solid theoretical foundation and practical insights that could inspire future advancements in this field.
Conclusion
This paper presents a probabilistic model that can help explain the success of self-supervised representation learning techniques. By capturing the underlying structure of the data and using this information to guide the learning of useful representations, the authors demonstrate an effective approach for learning powerful features without the need for labeled examples.
The proposed model offers a principled framework for understanding self-supervised learning, and the authors' results suggest that this approach could lead to significant improvements in a wide range of machine learning applications. As the field of self-supervised learning continues to evolve, this work provides a valuable theoretical and practical contribution that may inspire further innovations and advancements.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Can Generative Models Improve Self-Supervised Representation Learning?
Sana Ayromlou, Arash Afkanpour, Vahid Reza Khazaie, Fereshteh Forghani
0
0
The rapid advancement in self-supervised learning (SSL) has highlighted its potential to leverage unlabeled data for learning rich visual representations. However, the existing SSL techniques, particularly those employing different augmentations of the same image, often rely on a limited set of simple transformations that are not representative of real-world data variations. This constrains the diversity and quality of samples, which leads to sub-optimal representations. In this paper, we introduce a novel framework that enriches the SSL paradigm by utilizing generative models to produce semantically consistent image augmentations. By directly conditioning generative models on a source image representation, our method enables the generation of diverse augmentations while maintaining the semantics of the source image, thus offering a richer set of data for self-supervised learning. Our extensive experimental results on various SSL methods demonstrate that our framework significantly enhances the quality of learned visual representations by up to 10% Top-1 accuracy in downstream tasks. This research demonstrates that incorporating generative models into the SSL workflow opens new avenues for exploring the potential of synthetic data. This development paves the way for more robust and versatile representation learning techniques.
5/28/2024
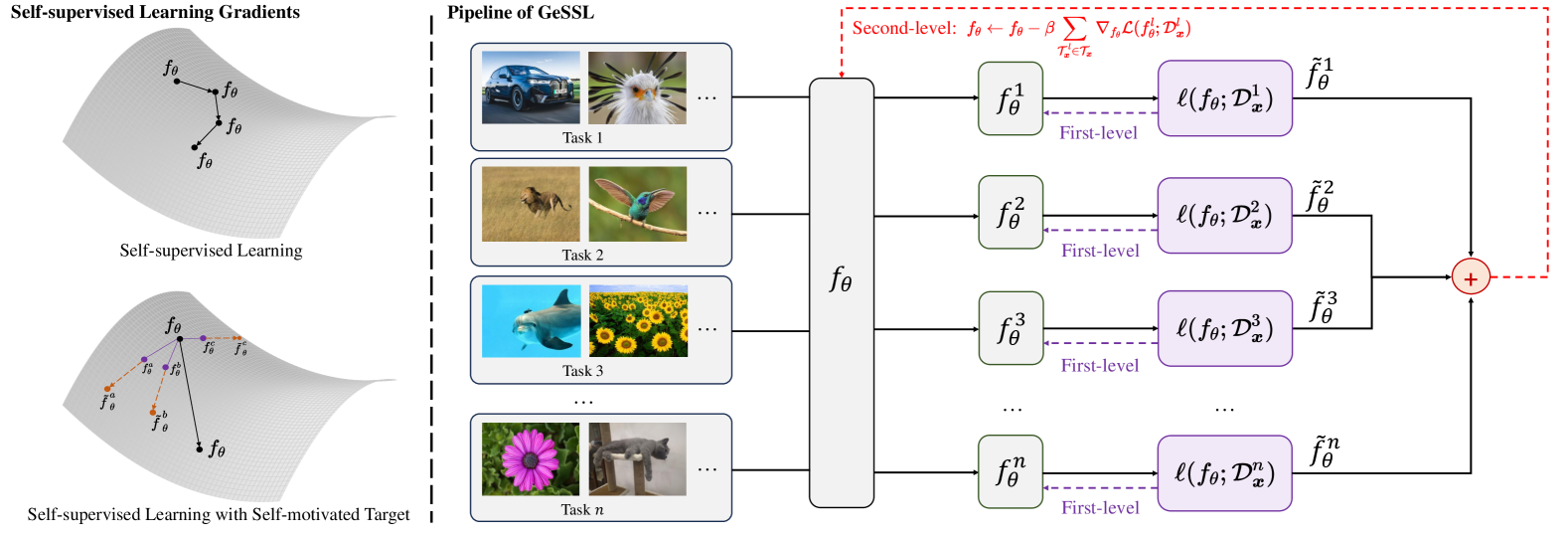
Explicitly Modeling Generality into Self-Supervised Learning
Jingyao Wang, Wenwen Qiang, Zeen Song, Lingyu Si, Jiangmeng Li, Changwen Zheng, Bing Su
0
0
The goal of universality in self-supervised learning (SSL) is to learn universal representations from unlabeled data and achieve excellent performance on all samples and tasks. However, these methods lack explicit modeling of the universality in the learning objective, and the related theoretical understanding remains limited. This may cause models to overfit in data-scarce situations and generalize poorly in real life. To address these issues, we provide a theoretical definition of universality in SSL, which constrains both the learning and evaluation universality of the SSL models from the perspective of discriminability, transferability, and generalization. Then, we propose a $sigma$-measurement to help quantify the score of one SSL model's universality. Based on the definition and measurement, we propose a general SSL framework, called GeSSL, to explicitly model universality into SSL. It introduces a self-motivated target based on $sigma$-measurement, which enables the model to find the optimal update direction towards universality. Extensive theoretical and empirical evaluations demonstrate the superior performance of GeSSL.
5/24/2024
⛏️
Refining Latent Representations: A Generative SSL Approach for Heterogeneous Graph Learning
Yulan Hu, Zhirui Yang, Sheng Ouyang, Yong Liu
0
0
Self-Supervised Learning (SSL) has shown significant potential and has garnered increasing interest in graph learning. However, particularly for generative SSL methods, its potential in Heterogeneous Graph Learning (HGL) remains relatively underexplored. Generative SSL utilizes an encoder to map the input graph into a latent representation and a decoder to recover the input graph from the latent representation. Previous HGL SSL methods generally design complex strategies to capture graph heterogeneity, which heavily rely on contrastive view construction strategies that are often non-trivial. Yet, refining the latent representation in generative SSL can effectively improve graph learning results. In this study, we propose HGVAE, a generative SSL method specially designed for HGL. Instead of focusing on designing complex strategies to capture heterogeneity, HGVAE centers on refining the latent representation. Specifically, HGVAE innovatively develops a contrastive task based on the latent representation. To ensure the hardness of negative samples, we develop a progressive negative sample generation (PNSG) mechanism that leverages the ability of Variational Inference (VI) to generate high-quality negative samples. As a pioneer in applying generative SSL for HGL, HGVAE refines the latent representation, thereby compelling the model to learn high-quality representations. Compared with various state-of-the-art (SOTA) baselines, HGVAE achieves impressive results, thus validating its superiority.
4/23/2024

Self-supervised visual learning in the low-data regime: a comparative evaluation
Sotirios Konstantakos, Despina Ioanna Chalkiadaki, Ioannis Mademlis, Yuki M. Asano, Efstratios Gavves, Georgios Th. Papadopoulos
0
0
Self-Supervised Learning (SSL) is a valuable and robust training methodology for contemporary Deep Neural Networks (DNNs), enabling unsupervised pretraining on a `pretext task' that does not require ground-truth labels/annotation. This allows efficient representation learning from massive amounts of unlabeled training data, which in turn leads to increased accuracy in a `downstream task' by exploiting supervised transfer learning. Despite the relatively straightforward conceptualization and applicability of SSL, it is not always feasible to collect and/or to utilize very large pretraining datasets, especially when it comes to real-world application settings. In particular, in cases of specialized and domain-specific application scenarios, it may not be achievable or practical to assemble a relevant image pretraining dataset in the order of millions of instances or it could be computationally infeasible to pretrain at this scale. This motivates an investigation on the effectiveness of common SSL pretext tasks, when the pretraining dataset is of relatively limited/constrained size. In this context, this work introduces a taxonomy of modern visual SSL methods, accompanied by detailed explanations and insights regarding the main categories of approaches, and, subsequently, conducts a thorough comparative experimental evaluation in the low-data regime, targeting to identify: a) what is learnt via low-data SSL pretraining, and b) how do different SSL categories behave in such training scenarios. Interestingly, for domain-specific downstream tasks, in-domain low-data SSL pretraining outperforms the common approach of large-scale pretraining on general datasets. Grounded on the obtained results, valuable insights are highlighted regarding the performance of each category of SSL methods, which in turn suggest straightforward future research directions in the field.
4/29/2024