On Computationally Efficient Multi-Class Calibration
2402.07821
0
0
🛸
Abstract
Consider a multi-class labelling problem, where the labels can take values in $[k]$, and a predictor predicts a distribution over the labels. In this work, we study the following foundational question: Are there notions of multi-class calibration that give strong guarantees of meaningful predictions and can be achieved in time and sample complexities polynomial in $k$? Prior notions of calibration exhibit a tradeoff between computational efficiency and expressivity: they either suffer from having sample complexity exponential in $k$, or needing to solve computationally intractable problems, or give rather weak guarantees. Our main contribution is a notion of calibration that achieves all these desiderata: we formulate a robust notion of projected smooth calibration for multi-class predictions, and give new recalibration algorithms for efficiently calibrating predictors under this definition with complexity polynomial in $k$. Projected smooth calibration gives strong guarantees for all downstream decision makers who want to use the predictor for binary classification problems of the form: does the label belong to a subset $T subseteq [k]$: e.g. is this an image of an animal? It ensures that the probabilities predicted by summing the probabilities assigned to labels in $T$ are close to some perfectly calibrated binary predictor for that task. We also show that natural strengthenings of our definition are computationally hard to achieve: they run into information theoretic barriers or computational intractability. Underlying both our upper and lower bounds is a tight connection that we prove between multi-class calibration and the well-studied problem of agnostic learning in the (standard) binary prediction setting.
Create account to get full access
Overview
- Explores the problem of multi-class calibration, which aims to ensure that the predicted probabilities for a multi-class model are meaningful and can be effectively used for downstream binary classification tasks.
- Prior approaches suffer from either exponential sample complexity in the number of classes, or computationally intractable solutions, or weak guarantees.
- Main contribution is a notion of "projected smooth calibration" that achieves strong guarantees while being computationally efficient.
- Also shows that strengthening this definition further leads to inherent information-theoretic barriers or computational intractability.
Plain English Explanation
In many real-world machine learning problems, we need to classify data into multiple categories or classes. For example, an image classification model might need to predict whether an image depicts a dog, cat, or something else.
The paper focuses on the idea of calibration for these multi-class prediction problems. Calibration means that the model's predicted probabilities for each class actually reflect the true likelihood of that class being the correct label.
Achieving good calibration is important because it allows downstream users of the model to trust the probability estimates and use them effectively. For example, if the model says there's a 70% chance an image is a dog, that should mean the dog class is the true label 70% of the time.
The authors explain that prior approaches to multi-class calibration either require an impractically large amount of training data, solve computationally difficult problems, or provide relatively weak guarantees. In contrast, the main contribution of this work is a new notion of projected smooth calibration that achieves strong calibration properties while remaining computationally efficient.
The key insight is that this calibration definition focuses on ensuring the model's probabilities are well-calibrated for any subset of the classes, rather than trying to get perfect calibration across all classes simultaneously. This allows for more effective recalibration algorithms that scale polynomially with the number of classes.
Technical Explanation
The paper studies the problem of multi-class calibration, where a predictor outputs a probability distribution over a set of k possible class labels. The authors aim to develop notions of calibration that provide strong guarantees for downstream binary classification tasks, while being computationally efficient.
Prior approaches to multi-class calibration often exhibit trade-offs: either they require exponential sample complexity in k, or they need to solve computationally intractable problems, or they provide relatively weak guarantees. To address this, the authors introduce a new concept called projected smooth calibration.
Projected smooth calibration ensures that for any subset T of the k classes, the probabilities predicted by summing the probabilities assigned to labels in T are close to those of a perfectly calibrated binary predictor for the task "does the label belong to T?". This provides strong guarantees for downstream binary classification tasks.
Importantly, the authors show that their definition of projected smooth calibration can be efficiently achieved using new recalibration algorithms with complexity polynomial in k. In contrast, they prove that natural strengthenings of their definition lead to inherent information-theoretic barriers or computational intractability.
Underlying both the upper and lower bounds in this work is a tight connection between multi-class calibration and the well-studied problem of agnostic learning in the standard binary prediction setting. This connection allows the authors to leverage insights from binary calibration to address the multi-class case.
Critical Analysis
The work presented in this paper addresses an important problem in machine learning and provides a compelling solution. The authors' notion of projected smooth calibration is a promising approach that balances strong theoretical guarantees with computational efficiency.
One potential limitation is that the paper focuses on the multi-class setting, whereas many real-world applications may involve an even larger number of classes. It would be interesting to see how the proposed techniques scale to problems with a very large number of classes, and whether there are any fundamental barriers to achieving efficient multi-class calibration in those settings.
Additionally, the paper does not discuss the practical implementation of the recalibration algorithms or provide empirical results demonstrating their effectiveness on real-world datasets. While the theoretical analysis is robust, it would be valuable to see how the proposed methods perform in realistic scenarios.
Another area for further research could be the connection between multi-class calibration and out-of-distribution generalization. The authors briefly touch on this, but a deeper exploration of the relationship between calibration, robustness, and generalization could yield additional insights.
Overall, this paper makes a significant contribution to the understanding of multi-class calibration and offers a promising approach that could have important implications for the practical use of multi-class predictors. As with any research, there are opportunities for further exploration and refinement, but the authors have laid an excellent foundation for future work in this area.
Conclusion
This paper tackles the fundamental problem of achieving strong multi-class calibration guarantees in a computationally efficient manner. By introducing the concept of projected smooth calibration, the authors have proposed a robust calibration definition that provides strong assurances for downstream binary classification tasks, while being achievable using new recalibration algorithms that scale polynomially with the number of classes.
The tight connection the authors establish between multi-class calibration and agnostic learning in the binary setting is a key insight that underpins both their upper and lower bounds. This connection highlights the deep theoretical relationships between different calibration problems and suggests that further exploration of these connections could yield additional insights.
Overall, this work represents an important step forward in the understanding and implementation of reliable multi-class predictors, with potential applications in a wide range of fields that rely on accurate and trustworthy probabilistic predictions. As the authors note, there are still opportunities for further refinement and exploration, but this paper lays a strong foundation for future research in this direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Testing Calibration in Nearly-Linear Time
Lunjia Hu, Arun Jambulapati, Kevin Tian, Chutong Yang
0
0
In the recent literature on machine learning and decision making, calibration has emerged as a desirable and widely-studied statistical property of the outputs of binary prediction models. However, the algorithmic aspects of measuring model calibration have remained relatively less well-explored. Motivated by [BGHN23], which proposed a rigorous framework for measuring distances to calibration, we initiate the algorithmic study of calibration through the lens of property testing. We define the problem of calibration testing from samples where given $n$ draws from a distribution $mathcal{D}$ on $(predictions, binary outcomes)$, our goal is to distinguish between the case where $mathcal{D}$ is perfectly calibrated, and the case where $mathcal{D}$ is $varepsilon$-far from calibration. We make the simple observation that the empirical smooth calibration linear program can be reformulated as an instance of minimum-cost flow on a highly-structured graph, and design an exact dynamic programming-based solver for it which runs in time $O(nlog^2(n))$, and solves the calibration testing problem information-theoretically optimally in the same time. This improves upon state-of-the-art black-box linear program solvers requiring $Omega(n^omega)$ time, where $omega > 2$ is the exponent of matrix multiplication. We also develop algorithms for tolerant variants of our testing problem improving upon black-box linear program solvers, and give sample complexity lower bounds for alternative calibration measures to the one considered in this work. Finally, we present experiments showing the testing problem we define faithfully captures standard notions of calibration, and that our algorithms scale efficiently to accommodate large sample sizes.
6/24/2024
⛏️
Optimal Multiclass U-Calibration Error and Beyond
Haipeng Luo, Spandan Senapati, Vatsal Sharan
0
0
We consider the problem of online multiclass U-calibration, where a forecaster aims to make sequential distributional predictions over $K$ classes with low U-calibration error, that is, low regret with respect to all bounded proper losses simultaneously. Kleinberg et al. (2023) developed an algorithm with U-calibration error $O(Ksqrt{T})$ after $T$ rounds and raised the open question of what the optimal bound is. We resolve this question by showing that the optimal U-calibration error is $Theta(sqrt{KT})$ -- we start with a simple observation that the Follow-the-Perturbed-Leader algorithm of Daskalakis and Syrgkanis (2016) achieves this upper bound, followed by a matching lower bound constructed with a specific proper loss (which, as a side result, also proves the optimality of the algorithm of Daskalakis and Syrgkanis (2016) in the context of online learning against an adversary with finite choices). We also strengthen our results under natural assumptions on the loss functions, including $Theta(log T)$ U-calibration error for Lipschitz proper losses, $O(log T)$ U-calibration error for a certain class of decomposable proper losses, U-calibration error bounds for proper losses with a low covering number, and others.
5/31/2024
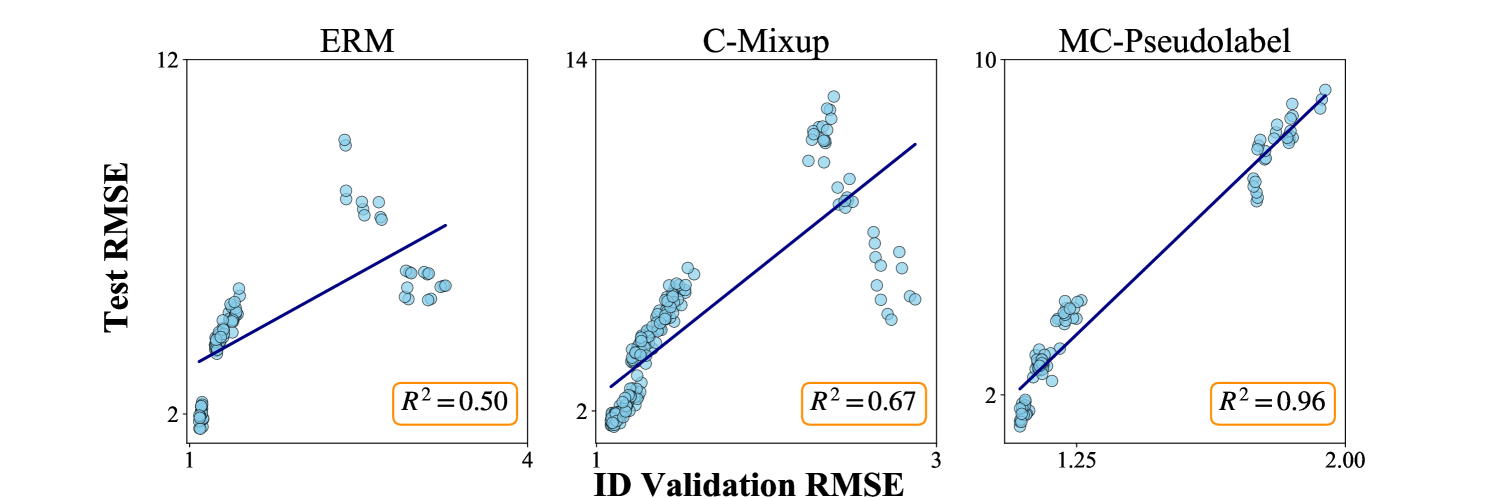
Bridging Multicalibration and Out-of-distribution Generalization Beyond Covariate Shift
Jiayun Wu, Jiashuo Liu, Peng Cui, Zhiwei Steven Wu
0
0
We establish a new model-agnostic optimization framework for out-of-distribution generalization via multicalibration, a criterion that ensures a predictor is calibrated across a family of overlapping groups. Multicalibration is shown to be associated with robustness of statistical inference under covariate shift. We further establish a link between multicalibration and robustness for prediction tasks both under and beyond covariate shift. We accomplish this by extending multicalibration to incorporate grouping functions that consider covariates and labels jointly. This leads to an equivalence of the extended multicalibration and invariance, an objective for robust learning in existence of concept shift. We show a linear structure of the grouping function class spanned by density ratios, resulting in a unifying framework for robust learning by designing specific grouping functions. We propose MC-Pseudolabel, a post-processing algorithm to achieve both extended multicalibration and out-of-distribution generalization. The algorithm, with lightweight hyperparameters and optimization through a series of supervised regression steps, achieves superior performance on real-world datasets with distribution shift.
6/4/2024
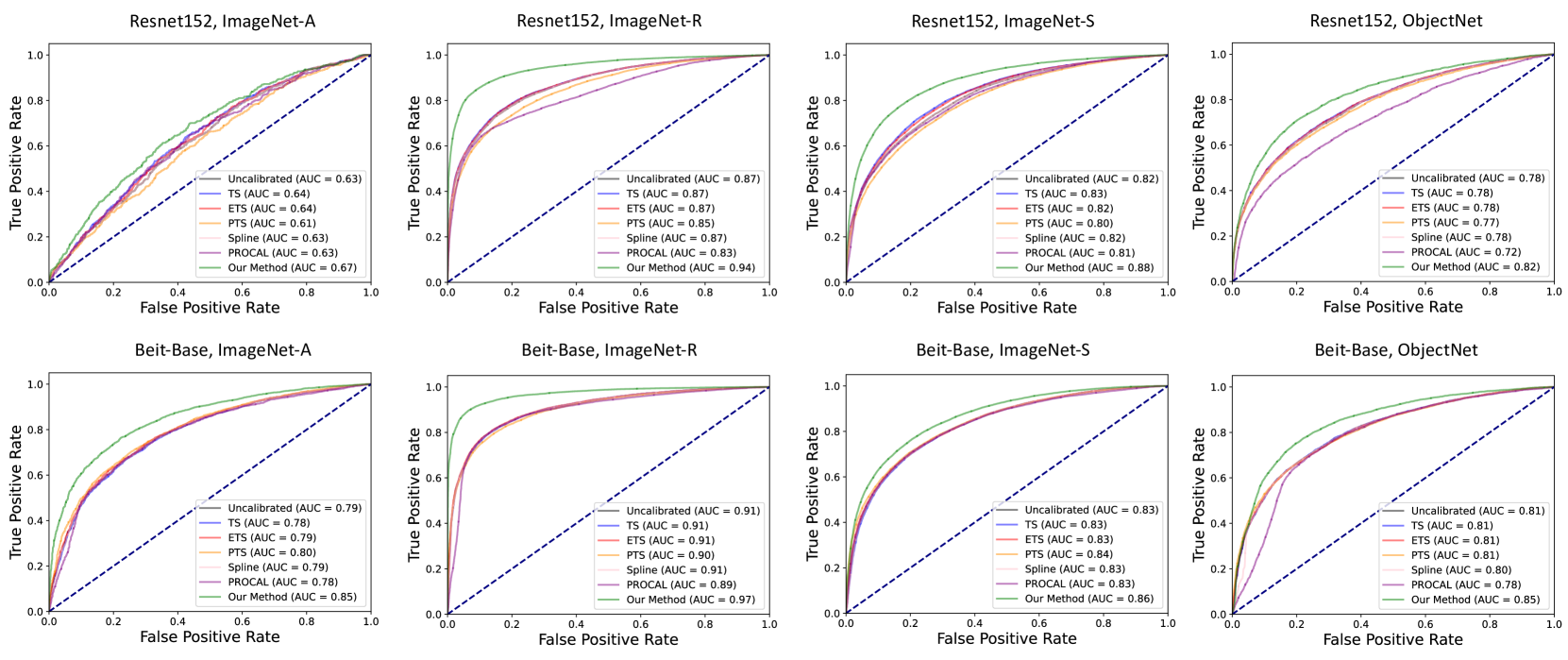
Optimizing Calibration by Gaining Aware of Prediction Correctness
Yuchi Liu, Lei Wang, Yuli Zou, James Zou, Liang Zheng
0
0
Model calibration aims to align confidence with prediction correctness. The Cross-Entropy (CE) loss is widely used for calibrator training, which enforces the model to increase confidence on the ground truth class. However, we find the CE loss has intrinsic limitations. For example, for a narrow misclassification, a calibrator trained by the CE loss often produces high confidence on the wrongly predicted class (e.g., a test sample is wrongly classified and its softmax score on the ground truth class is around 0.4), which is undesirable. In this paper, we propose a new post-hoc calibration objective derived from the aim of calibration. Intuitively, the proposed objective function asks that the calibrator decrease model confidence on wrongly predicted samples and increase confidence on correctly predicted samples. Because a sample itself has insufficient ability to indicate correctness, we use its transformed versions (e.g., rotated, greyscaled and color-jittered) during calibrator training. Trained on an in-distribution validation set and tested with isolated, individual test samples, our method achieves competitive calibration performance on both in-distribution and out-of-distribution test sets compared with the state of the art. Further, our analysis points out the difference between our method and commonly used objectives such as CE loss and mean square error loss, where the latters sometimes deviates from the calibration aim.
4/26/2024