A Concept-Based Explainability Framework for Large Multimodal Models
2406.08074
0
0

Abstract
Large multimodal models (LMMs) combine unimodal encoders and large language models (LLMs) to perform multimodal tasks. Despite recent advancements towards the interpretability of these models, understanding internal representations of LMMs remains largely a mystery. In this paper, we present a novel framework for the interpretation of LMMs. We propose a dictionary learning based approach, applied to the representation of tokens. The elements of the learned dictionary correspond to our proposed concepts. We show that these concepts are well semantically grounded in both vision and text. Thus we refer to these as multi-modal concepts. We qualitatively and quantitatively evaluate the results of the learnt concepts. We show that the extracted multimodal concepts are useful to interpret representations of test samples. Finally, we evaluate the disentanglement between different concepts and the quality of grounding concepts visually and textually. We will publicly release our code.
Create account to get full access
Overview
- This paper presents a concept-based explainability framework for large multimodal models, which aims to improve the interpretability of these complex AI systems.
- The framework leverages the idea of "concepts" to provide explanations for the model's predictions, allowing users to understand the reasoning behind the outputs.
- The authors demonstrate the effectiveness of their approach on various tasks, including image classification, visual question answering, and text generation.
Plain English Explanation
Large multimodal models, which can process and combine different types of data like images and text, have become increasingly powerful in recent years. However, these complex AI systems can be difficult to understand, as it's not always clear how they arrive at their predictions or outputs.
This paper introduces a new framework that uses the idea of "concepts" to help explain how these multimodal models work. The key insight is that rather than just looking at the final output, the framework can identify the specific concepts (e.g., "dog," "house," "person") that the model is basing its decisions on. By surfacing these intermediate concepts, the framework can provide users with a more transparent and interpretable explanation of the model's reasoning.
The authors demonstrate the effectiveness of their concept-based approach on a variety of tasks, such as link to "explaining-latent-representations-generative-models-large-multimodal" image classification, link to "explaining-multi-modal-large-language-models-by" visual question answering, and link to "notellm-2-multimodal-large-representation-models-recommendation" text generation. By making these complex models more interpretable, the framework can help users better understand and trust the decisions made by large multimodal AI systems.
Technical Explanation
The key idea behind the concept-based explainability framework is to identify the specific "concepts" that a large multimodal model relies on when making a prediction or generating an output. The authors define a concept as a high-level, semantic representation of an object, attribute, or relationship that can be recognized by the model.
To implement this concept-based approach, the framework first trains a concept recognition model that can identify the relevant concepts present in the input data (e.g., images, text). This concept model is then used to analyze the internal representations of the larger multimodal model, allowing the framework to determine which concepts are most influential in the model's decision-making process.
The authors evaluate their framework on a range of tasks, including link to "revolution-multimodal-large-language-models-survey" image classification, visual question answering, and text generation. The results show that the concept-based explanations provide valuable insights into the models' reasoning, outperforming traditional post-hoc explainability approaches in terms of both interpretability and predictive performance.
Critical Analysis
The concept-based explainability framework presented in this paper is a promising approach for improving the interpretability of large multimodal models. By focusing on the underlying concepts that drive the models' decisions, the framework offers a more transparent and intuitive way of understanding these complex AI systems.
That said, the authors acknowledge several limitations and areas for further research. For example, the concept recognition model used in the framework may not always capture the full semantic nuance of the input data, and the authors note the challenge of scaling the approach to handle the growing complexity of modern multimodal models.
Additionally, while the concept-based explanations can provide valuable insights, it's important to recognize that they may not fully capture the nuanced reasoning of these large AI systems. There may be subtle interactions or patterns in the data that are not easily reducible to high-level concepts, and the framework may struggle to account for these more complex relationships.
link to "review-multi-modal-large-language-vision-models" Further research is needed to explore the boundaries of the concept-based approach and to develop complementary techniques for explaining the inner workings of large multimodal models.
Conclusion
The concept-based explainability framework presented in this paper represents an important step towards making large multimodal AI systems more interpretable and transparent. By surfacing the key concepts underlying the models' decision-making, the framework can help users better understand and trust the outputs of these powerful AI systems.
As the field of multimodal AI continues to advance, the need for such interpretable and explainable approaches will only grow. The insights from this research can inform the development of future explainability techniques, ultimately helping to build more accountable and trustworthy AI systems that can be responsibly deployed in a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Explaining latent representations of generative models with large multimodal models
Mengdan Zhu, Zhenke Liu, Bo Pan, Abhinav Angirekula, Liang Zhao
0
0
Learning interpretable representations of data generative latent factors is an important topic for the development of artificial intelligence. With the rise of the large multimodal model, it can align images with text to generate answers. In this work, we propose a framework to comprehensively explain each latent variable in the generative models using a large multimodal model. We further measure the uncertainty of our generated explanations, quantitatively evaluate the performance of explanation generation among multiple large multimodal models, and qualitatively visualize the variations of each latent variable to learn the disentanglement effects of different generative models on explanations. Finally, we discuss the explanatory capabilities and limitations of state-of-the-art large multimodal models.
4/19/2024
💬
Explaining Multi-modal Large Language Models by Analyzing their Vision Perception
Loris Giulivi, Giacomo Boracchi
0
0
Multi-modal Large Language Models (MLLMs) have demonstrated remarkable capabilities in understanding and generating content across various modalities, such as images and text. However, their interpretability remains a challenge, hindering their adoption in critical applications. This research proposes a novel approach to enhance the interpretability of MLLMs by focusing on the image embedding component. We combine an open-world localization model with a MLLM, thus creating a new architecture able to simultaneously produce text and object localization outputs from the same vision embedding. The proposed architecture greatly promotes interpretability, enabling us to design a novel saliency map to explain any output token, to identify model hallucinations, and to assess model biases through semantic adversarial perturbations.
5/29/2024
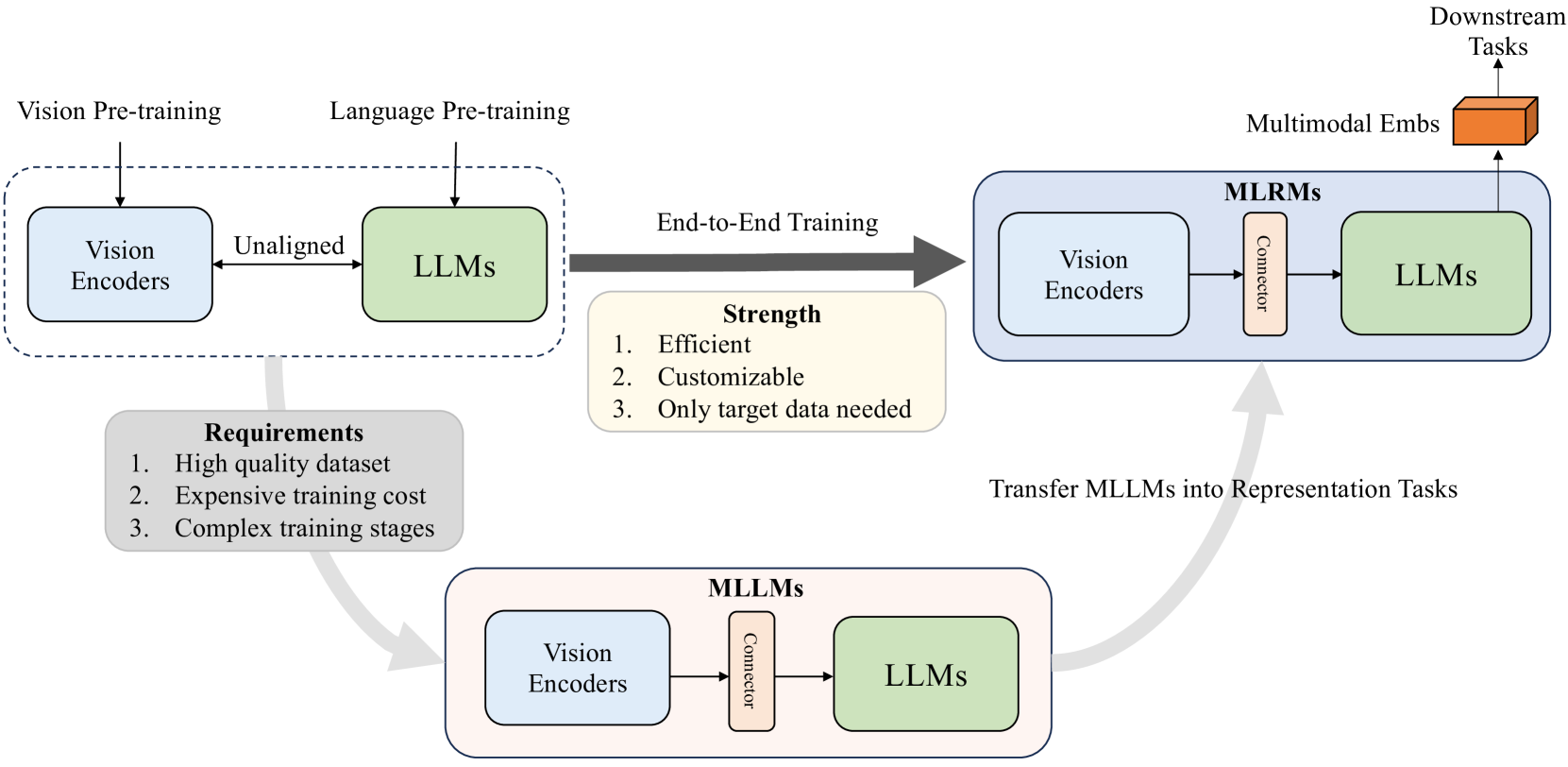
NoteLLM-2: Multimodal Large Representation Models for Recommendation
Chao Zhang, Haoxin Zhang, Shiwei Wu, Di Wu, Tong Xu, Yan Gao, Yao Hu, Enhong Chen
0
0
Large Language Models (LLMs) have demonstrated exceptional text understanding. Existing works explore their application in text embedding tasks. However, there are few works utilizing LLMs to assist multimodal representation tasks. In this work, we investigate the potential of LLMs to enhance multimodal representation in multimodal item-to-item (I2I) recommendations. One feasible method is the transfer of Multimodal Large Language Models (MLLMs) for representation tasks. However, pre-training MLLMs usually requires collecting high-quality, web-scale multimodal data, resulting in complex training procedures and high costs. This leads the community to rely heavily on open-source MLLMs, hindering customized training for representation scenarios. Therefore, we aim to design an end-to-end training method that customizes the integration of any existing LLMs and vision encoders to construct efficient multimodal representation models. Preliminary experiments show that fine-tuned LLMs in this end-to-end method tend to overlook image content. To overcome this challenge, we propose a novel training framework, NoteLLM-2, specifically designed for multimodal representation. We propose two ways to enhance the focus on visual information. The first method is based on the prompt viewpoint, which separates multimodal content into visual content and textual content. NoteLLM-2 adopts the multimodal In-Content Learning method to teach LLMs to focus on both modalities and aggregate key information. The second method is from the model architecture, utilizing a late fusion mechanism to directly fuse visual information into textual information. Extensive experiments have been conducted to validate the effectiveness of our method.
5/28/2024

The Revolution of Multimodal Large Language Models: A Survey
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Lorenzo Baraldi, Marcella Cornia, Rita Cucchiara
0
0
Connecting text and visual modalities plays an essential role in generative intelligence. For this reason, inspired by the success of large language models, significant research efforts are being devoted to the development of Multimodal Large Language Models (MLLMs). These models can seamlessly integrate visual and textual modalities, while providing a dialogue-based interface and instruction-following capabilities. In this paper, we provide a comprehensive review of recent visual-based MLLMs, analyzing their architectural choices, multimodal alignment strategies, and training techniques. We also conduct a detailed analysis of these models across a wide range of tasks, including visual grounding, image generation and editing, visual understanding, and domain-specific applications. Additionally, we compile and describe training datasets and evaluation benchmarks, conducting comparisons among existing models in terms of performance and computational requirements. Overall, this survey offers a comprehensive overview of the current state of the art, laying the groundwork for future MLLMs.
6/7/2024