Confidence-aware Self-Semantic Distillation on Knowledge Graph Embedding
2206.02963
0
0
👁️
Abstract
Knowledge Graph Embedding (KGE), which projects entities and relations into continuous vector spaces, have garnered significant attention. Although high-dimensional KGE methods offer better performance, they come at the expense of significant computation and memory overheads. Decreasing embedding dimensions significantly deteriorates model performance. While several recent efforts utilize knowledge distillation or non-Euclidean representation learning to augment the effectiveness of low-dimensional KGE, they either necessitate a pre-trained high-dimensional teacher model or involve complex non-Euclidean operations, thereby incurring considerable additional computational costs. To address this, this work proposes Confidence-aware Self-Knowledge Distillation (CSD) that learns from model itself to enhance KGE in a low-dimensional space. Specifically, CSD extracts knowledge from embeddings in previous iterations, which would be utilized to supervise the learning of the model in the next iterations. Moreover, a specific semantic module is developed to filter reliable knowledge by estimating the confidence of previously learned embeddings. This straightforward strategy bypasses the need for time-consuming pre-training of teacher models and can be integrated into various KGE methods to improve their performance. Our comprehensive experiments on six KGE backbones and four datasets underscore the effectiveness of the proposed CSD.
Create account to get full access
Overview
- This paper proposes a new method called Confidence-aware Self-Knowledge Distillation (CSD) to improve the performance of low-dimensional Knowledge Graph Embedding (KGE) models.
- KGE is a technique that represents entities and relations in a knowledge graph as continuous vector embeddings, which are useful for various applications.
- High-dimensional KGE methods generally perform better, but they require significant computational resources, while low-dimensional models suffer from reduced performance.
- CSD aims to enhance the effectiveness of low-dimensional KGE models by learning from the model's own embeddings in previous iterations, without the need for a pre-trained high-dimensional teacher model.
Plain English Explanation
Knowledge graphs are structured representations of information, where entities (things) and the relationships between them are stored. Knowledge Graph Embedding (KGE) is a technique that converts these entities and relationships into numerical vectors, or embeddings, that a computer can understand and work with.
High-dimensional KGE models, which use a large number of values to represent each entity and relationship, tend to perform better than low-dimensional models. However, the high-dimensional models require a lot of computational power and memory, which can be a problem, especially on devices with limited resources.
To address this, the researchers developed a method called Confidence-aware Self-Knowledge Distillation (CSD). CSD allows low-dimensional KGE models to learn from their own previous embeddings, without needing a complex, pre-trained high-dimensional "teacher" model. This is done by extracting reliable knowledge from the model's past embeddings and using that to guide the model's learning in the current iteration.
The key innovation is a "semantic module" that estimates the confidence, or reliability, of the previously learned embeddings. This allows the model to focus on the most trustworthy knowledge when updating its embeddings, rather than blindly using all of its past outputs.
By leveraging the model's own knowledge in this way, CSD can improve the performance of low-dimensional KGE models without the additional computational overhead required by other approaches, such as CLIP-Embed-KD or KG-FiT.
Technical Explanation
The proposed Confidence-aware Self-Knowledge Distillation (CSD) method aims to enhance the performance of low-dimensional Knowledge Graph Embedding (KGE) models by leveraging the model's own previously learned embeddings.
CSD works as follows:
- The model learns low-dimensional embeddings for entities and relations in the knowledge graph.
- A "semantic module" is used to estimate the confidence, or reliability, of the previously learned embeddings.
- This confidence information is then used to selectively distill knowledge from the previous embeddings, guiding the model's learning in the current iteration.
This self-supervised approach allows CSD to improve low-dimensional KGE models without requiring a pre-trained high-dimensional "teacher" model, as is the case with cross-domain knowledge distillation methods.
The researchers evaluate CSD on six different KGE backbones and four datasets, demonstrating its effectiveness in boosting the performance of low-dimensional KGE models. CSD is shown to outperform other approaches that aim to enhance low-dimensional KGE, such as CLIP-Embed-KD and KG-FiT.
Critical Analysis
The paper provides a novel and promising approach to improving the performance of low-dimensional KGE models without the need for a pre-trained high-dimensional teacher model or complex non-Euclidean operations.
One potential limitation is that the effectiveness of the semantic module in estimating the confidence of previously learned embeddings may vary depending on the specific knowledge graph and task at hand. The paper does not provide a detailed analysis of the robustness of this confidence estimation mechanism across diverse datasets and scenarios.
Additionally, while the paper demonstrates the effectiveness of CSD on various KGE backbones, it would be valuable to see how CSD compares to other knowledge distillation or representation learning techniques that do not rely on a teacher model, such as distributed representations for entities in open-world knowledge graphs.
Further research could also explore the scalability and computational efficiency of CSD, especially when dealing with large-scale knowledge graphs, to ensure its practical applicability in real-world scenarios.
Conclusion
The Confidence-aware Self-Knowledge Distillation (CSD) method proposed in this paper offers a promising approach to enhancing the performance of low-dimensional Knowledge Graph Embedding (KGE) models. By leveraging the model's own previously learned embeddings, CSD can improve low-dimensional KGE without the need for a pre-trained high-dimensional teacher model or complex non-Euclidean operations.
The effectiveness of CSD, as demonstrated across multiple KGE backbones and datasets, underscores its potential to address the computational and memory challenges associated with high-dimensional KGE models. This work represents a valuable contribution to the ongoing efforts in the field of knowledge graph representation learning, paving the way for more efficient and effective applications of KGE in various domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Towards Continual Knowledge Graph Embedding via Incremental Distillation
Jiajun Liu, Wenjun Ke, Peng Wang, Ziyu Shang, Jinhua Gao, Guozheng Li, Ke Ji, Yanhe Liu
0
0
Traditional knowledge graph embedding (KGE) methods typically require preserving the entire knowledge graph (KG) with significant training costs when new knowledge emerges. To address this issue, the continual knowledge graph embedding (CKGE) task has been proposed to train the KGE model by learning emerging knowledge efficiently while simultaneously preserving decent old knowledge. However, the explicit graph structure in KGs, which is critical for the above goal, has been heavily ignored by existing CKGE methods. On the one hand, existing methods usually learn new triples in a random order, destroying the inner structure of new KGs. On the other hand, old triples are preserved with equal priority, failing to alleviate catastrophic forgetting effectively. In this paper, we propose a competitive method for CKGE based on incremental distillation (IncDE), which considers the full use of the explicit graph structure in KGs. First, to optimize the learning order, we introduce a hierarchical strategy, ranking new triples for layer-by-layer learning. By employing the inter- and intra-hierarchical orders together, new triples are grouped into layers based on the graph structure features. Secondly, to preserve the old knowledge effectively, we devise a novel incremental distillation mechanism, which facilitates the seamless transfer of entity representations from the previous layer to the next one, promoting old knowledge preservation. Finally, we adopt a two-stage training paradigm to avoid the over-corruption of old knowledge influenced by under-trained new knowledge. Experimental results demonstrate the superiority of IncDE over state-of-the-art baselines. Notably, the incremental distillation mechanism contributes to improvements of 0.2%-6.5% in the mean reciprocal rank (MRR) score.
5/8/2024

Guiding Frame-Level CTC Alignments Using Self-knowledge Distillation
Eungbeom Kim, Hantae Kim, Kyogu Lee
0
0
Transformer encoder with connectionist temporal classification (CTC) framework is widely used for automatic speech recognition (ASR). However, knowledge distillation (KD) for ASR displays a problem of disagreement between teacher-student models in frame-level alignment which ultimately hinders it from improving the student model's performance. In order to resolve this problem, this paper introduces a self-knowledge distillation (SKD) method that guides the frame-level alignment during the training time. In contrast to the conventional method using separate teacher and student models, this study introduces a simple and effective method sharing encoder layers and applying the sub-model as the student model. Overall, our approach is effective in improving both the resource efficiency as well as performance. We also conducted an experimental analysis of the spike timings to illustrate that the proposed method improves performance by reducing the alignment disagreement.
6/13/2024
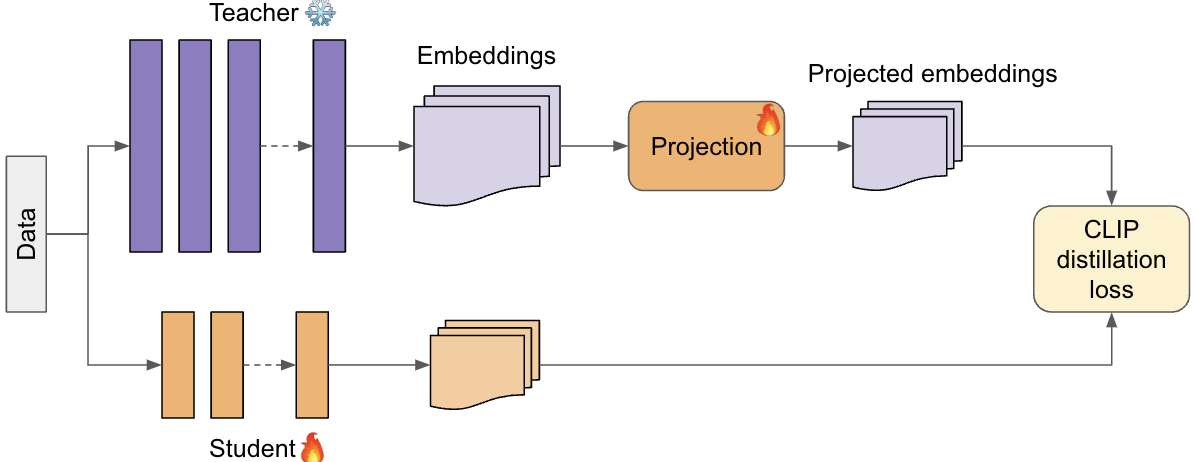
CLIP-Embed-KD: Computationally Efficient Knowledge Distillation Using Embeddings as Teachers
Lakshmi Nair
0
0
Contrastive Language-Image Pre-training (CLIP) has been shown to improve zero-shot generalization capabilities of language and vision models. In this paper, we extend CLIP for efficient knowledge distillation, by utilizing embeddings as teachers. Typical knowledge distillation frameworks require running forward passes through a teacher model, which is often prohibitive in the case of billion or trillion parameter teachers. In these cases, using only the embeddings of the teacher models to guide the distillation can yield significant computational savings. Our preliminary findings show that CLIP-based knowledge distillation with embeddings can outperform full scale knowledge distillation using $9times$ less memory and $8times$ less training time. Code available at: https://github.com/lnairGT/CLIP-Distillation/
4/10/2024

Lightweight Model Pre-training via Language Guided Knowledge Distillation
Mingsheng Li, Lin Zhang, Mingzhen Zhu, Zilong Huang, Gang Yu, Jiayuan Fan, Tao Chen
0
0
This paper studies the problem of pre-training for small models, which is essential for many mobile devices. Current state-of-the-art methods on this problem transfer the representational knowledge of a large network (as a Teacher) into a smaller model (as a Student) using self-supervised distillation, improving the performance of the small model on downstream tasks. However, existing approaches are insufficient in extracting the crucial knowledge that is useful for discerning categories in downstream tasks during the distillation process. In this paper, for the first time, we introduce language guidance to the distillation process and propose a new method named Language-Guided Distillation (LGD) system, which uses category names of the target downstream task to help refine the knowledge transferred between the teacher and student. To this end, we utilize a pre-trained text encoder to extract semantic embeddings from language and construct a textual semantic space called Textual Semantics Bank (TSB). Furthermore, we design a Language-Guided Knowledge Aggregation (LGKA) module to construct the visual semantic space, also named Visual Semantics Bank (VSB). The task-related knowledge is transferred by driving a student encoder to mimic the similarity score distribution inferred by a teacher over TSB and VSB. Compared with other small models obtained by either ImageNet pre-training or self-supervised distillation, experiment results show that the distilled lightweight model using the proposed LGD method presents state-of-the-art performance and is validated on various downstream tasks, including classification, detection, and segmentation. We have made the code available at https://github.com/mZhenz/LGD.
6/18/2024