CLIP-Embed-KD: Computationally Efficient Knowledge Distillation Using Embeddings as Teachers
2404.06170
0
0
Abstract
Contrastive Language-Image Pre-training (CLIP) has been shown to improve zero-shot generalization capabilities of language and vision models. In this paper, we extend CLIP for efficient knowledge distillation, by utilizing embeddings as teachers. Typical knowledge distillation frameworks require running forward passes through a teacher model, which is often prohibitive in the case of billion or trillion parameter teachers. In these cases, using only the embeddings of the teacher models to guide the distillation can yield significant computational savings. Our preliminary findings show that CLIP-based knowledge distillation with embeddings can outperform full scale knowledge distillation using $9times$ less memory and $8times$ less training time. Code available at: https://github.com/lnairGT/CLIP-Distillation/
Create account to get full access
Overview
- The paper introduces a computationally efficient knowledge distillation technique called CLIP-Embed-KD that uses CLIP embeddings as teachers to train smaller student models.
- CLIP-Embed-KD aims to distill the knowledge from large, complex models like CLIP into more efficient student models without sacrificing performance.
- The proposed method leverages the rich semantic information captured by CLIP's text and image embeddings to guide the training of the student model.
Plain English Explanation
CLIP-Embed-KD is a way to teach smaller, more efficient machine learning models to perform well on tasks, even if they don't have the same level of complexity as the larger, more powerful models. The key idea is to use the embeddings, or the way that the larger models represent and understand information, as a guide for training the smaller models.
Embeddings are mathematical representations of things like words, images, or other data that capture their meaning and relationships. CLIP is a model that can create these kinds of rich, semantic embeddings for both text and images.
The researchers behind CLIP-Embed-KD realized that they could use these CLIP embeddings as "teachers" to train smaller, more efficient student models. The student models don't have to learn everything from scratch - they can focus on mimicking the valuable information captured in the CLIP embeddings, which leads to better performance without the computational overhead of the larger model.
This approach is known as "knowledge distillation," where the knowledge of a larger, more complex model is distilled down and transferred to a smaller, more practical model. Other research has explored different ways to do knowledge distillation, but CLIP-Embed-KD offers a computationally efficient solution that leverages the unique capabilities of CLIP.
Technical Explanation
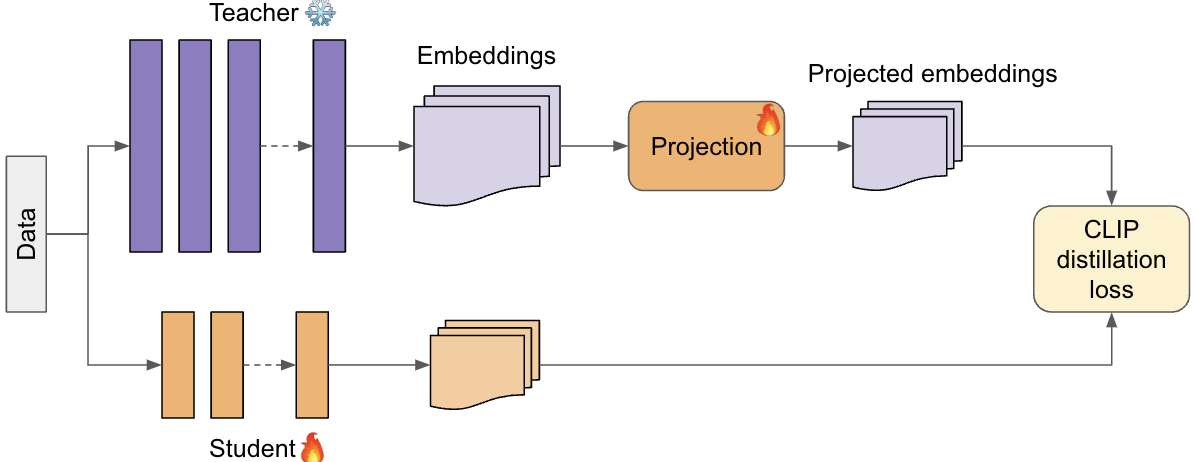
The core idea behind CLIP-Embed-KD is to use the text and image embeddings from a pre-trained CLIP model as "teachers" to guide the training of a smaller student model.
The approach works as follows:
- A pre-trained CLIP model is used to generate embeddings for the input data (e.g., images).
- The student model is trained to not only predict the correct labels for the input data, but also to match the CLIP embeddings as closely as possible.
- This process of "knowledge distillation" allows the student model to learn the rich semantic information captured by the CLIP embeddings, without having to match the full complexity of the CLIP model.
The authors demonstrate the effectiveness of CLIP-Embed-KD through experiments on various image classification tasks. They show that the student models trained with CLIP-Embed-KD can achieve competitive performance compared to larger, more complex models, while being much more computationally efficient.
The key insights from the technical explanation are:
- Leveraging pre-trained CLIP embeddings as "teachers" to guide student model training
- Using a knowledge distillation approach to transfer the CLIP model's semantic understanding to the student
- Achieving strong performance with more efficient student models compared to larger, more complex models
Critical Analysis
The CLIP-Embed-KD approach presents a compelling solution for efficient knowledge distillation, but there are a few potential limitations and areas for further research:
-
Dependence on CLIP: The effectiveness of CLIP-Embed-KD is heavily dependent on the quality and capabilities of the pre-trained CLIP model. If CLIP has limitations or biases, these could potentially be inherited by the student models.
-
Generalization to other domains: The paper focuses on image classification tasks, but it's unclear how well the CLIP-Embed-KD approach would generalize to other domains, such as natural language processing or video analysis.
-
Potential for further optimization: While CLIP-Embed-KD is computationally efficient compared to training the full CLIP model, there may be opportunities for further optimization, such as selective distillation or label-aware distillation.
Overall, CLIP-Embed-KD represents a promising approach for efficient knowledge distillation, but additional research and experimentation may be needed to fully understand its capabilities and limitations.
Conclusion
The CLIP-Embed-KD technique introduced in this paper offers a computationally efficient way to distill the knowledge from large, complex models like CLIP into more streamlined student models. By leveraging the rich semantic information captured in CLIP's text and image embeddings, the student models can achieve strong performance without the full overhead of the larger model.
This approach has the potential to enable the deployment of powerful AI capabilities on a wide range of resource-constrained devices and platforms, making advanced machine learning more accessible and practical. As the field of AI continues to advance, techniques like CLIP-Embed-KD will play an important role in bridging the gap between research and real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
CLIP-KD: An Empirical Study of CLIP Model Distillation
Chuanguang Yang, Zhulin An, Libo Huang, Junyu Bi, Xinqiang Yu, Han Yang, Boyu Diao, Yongjun Xu
0
0
Contrastive Language-Image Pre-training (CLIP) has become a promising language-supervised visual pre-training framework. This paper aims to distill small CLIP models supervised by a large teacher CLIP model. We propose several distillation strategies, including relation, feature, gradient and contrastive paradigms, to examine the effectiveness of CLIP-Knowledge Distillation (KD). We show that a simple feature mimicry with Mean Squared Error loss works surprisingly well. Moreover, interactive contrastive learning across teacher and student encoders is also effective in performance improvement. We explain that the success of CLIP-KD can be attributed to maximizing the feature similarity between teacher and student. The unified method is applied to distill several student models trained on CC3M+12M. CLIP-KD improves student CLIP models consistently over zero-shot ImageNet classification and cross-modal retrieval benchmarks. When using ViT-L/14 pretrained on Laion-400M as the teacher, CLIP-KD achieves 57.5% and 55.4% zero-shot top-1 ImageNet accuracy over ViT-B/16 and ResNet-50, surpassing the original CLIP without KD by 20.5% and 20.1% margins, respectively. Our code is released on https://github.com/winycg/CLIP-KD.
5/8/2024
RWKV-CLIP: A Robust Vision-Language Representation Learner
Tiancheng Gu, Kaicheng Yang, Xiang An, Ziyong Feng, Dongnan Liu, Weidong Cai, Jiankang Deng
0
0
Contrastive Language-Image Pre-training (CLIP) has significantly improved performance in various vision-language tasks by expanding the dataset with image-text pairs obtained from websites. This paper further explores CLIP from the perspectives of data and model architecture. To address the prevalence of noisy data and enhance the quality of large-scale image-text data crawled from the internet, we introduce a diverse description generation framework that can leverage Large Language Models (LLMs) to synthesize and refine content from web-based texts, synthetic captions, and detection tags. Furthermore, we propose RWKV-CLIP, the first RWKV-driven vision-language representation learning model that combines the effective parallel training of transformers with the efficient inference of RNNs. Comprehensive experiments across various model scales and pre-training datasets demonstrate that RWKV-CLIP is a robust and efficient vision-language representation learner, it achieves state-of-the-art performance in several downstream tasks, including linear probe, zero-shot classification, and zero-shot image-text retrieval. To facilitate future research, the code and pre-trained models are released at https://github.com/deepglint/RWKV-CLIP
6/12/2024
👁️
Confidence-aware Self-Semantic Distillation on Knowledge Graph Embedding
Yichen Liu, Jiawei Chen, Defang Chen, Zhehui Zhou, Yan Feng, Can Wang
0
0
Knowledge Graph Embedding (KGE), which projects entities and relations into continuous vector spaces, have garnered significant attention. Although high-dimensional KGE methods offer better performance, they come at the expense of significant computation and memory overheads. Decreasing embedding dimensions significantly deteriorates model performance. While several recent efforts utilize knowledge distillation or non-Euclidean representation learning to augment the effectiveness of low-dimensional KGE, they either necessitate a pre-trained high-dimensional teacher model or involve complex non-Euclidean operations, thereby incurring considerable additional computational costs. To address this, this work proposes Confidence-aware Self-Knowledge Distillation (CSD) that learns from model itself to enhance KGE in a low-dimensional space. Specifically, CSD extracts knowledge from embeddings in previous iterations, which would be utilized to supervise the learning of the model in the next iterations. Moreover, a specific semantic module is developed to filter reliable knowledge by estimating the confidence of previously learned embeddings. This straightforward strategy bypasses the need for time-consuming pre-training of teacher models and can be integrated into various KGE methods to improve their performance. Our comprehensive experiments on six KGE backbones and four datasets underscore the effectiveness of the proposed CSD.
5/28/2024
✨
New!Distilling Knowledge from Text-to-Image Generative Models Improves Visio-Linguistic Reasoning in CLIP
Samyadeep Basu, Shell Xu Hu, Maziar Sanjabi, Daniela Massiceti, Soheil Feizi
0
0
Image-text contrastive models like CLIP have wide applications in zero-shot classification, image-text retrieval, and transfer learning. However, they often struggle on compositional visio-linguistic tasks (e.g., attribute-binding or object-relationships) where their performance is no better than random chance. To address this, we introduce SDS-CLIP, a lightweight and sample-efficient distillation method to enhance CLIP's compositional visio-linguistic reasoning. Our approach fine-tunes CLIP using a distillation objective borrowed from large text-to-image generative models like Stable-Diffusion, which are known for their strong visio-linguistic reasoning abilities. On the challenging Winoground benchmark, SDS-CLIP improves the visio-linguistic performance of various CLIP models by up to 7%, while on the ARO dataset, it boosts performance by up to 3%. This work underscores the potential of well-designed distillation objectives from generative models to enhance contrastive image-text models with improved visio-linguistic reasoning capabilities.
7/2/2024