Configuring Data Augmentations to Reduce Variance Shift in Positional Embedding of Vision Transformers

0
📊
Sign in to get full access
Overview
- Vision transformers (ViTs) have shown impressive results in various visual tasks, but require large and diverse datasets for effective training.
- Researchers have found that using advanced data augmentation techniques like Mixup, Cutmix, and random erasing is crucial for training successful ViTs.
- However, the paper reports a vulnerability with certain data augmentations causing a "variance shift" in the positional embeddings of ViTs, which can degrade their performance during testing.
Plain English Explanation
Vision transformers (ViTs) are a type of machine learning model that have shown impressive results in various visual tasks, like image classification and object detection. However, training these models requires a large and diverse dataset, which can be challenging to obtain.
To overcome this challenge, researchers have found that using advanced data augmentation techniques, like Mixup, Cutmix, and random erasing, is essential for training successful ViTs. These techniques artificially expand the training dataset by applying various transformations to the images, such as blending them together or randomly removing parts of the image.
However, the paper reports a surprising finding: certain data augmentations can cause a "variance shift" in the positional embeddings of ViTs. Positional embeddings are a way for the model to understand the spatial relationships between different parts of the image. When this variance shift occurs, it can actually degrade the model's performance during testing.
The researchers provide a detailed analysis of this problem and suggest the correct configuration for these data augmentations to remove the side effects of the variance shift. By following their guidelines, the researchers were able to improve the performance of ViTs compared to using the current standard data augmentation methods.
Technical Explanation
The paper investigates the use of rich data augmentations, such as Mixup, Cutmix, and random erasing, which have become a standard practice for training successful Vision Transformers (ViTs).
The researchers found that certain data augmentations can cause a variance shift in the positional embedding of ViTs, which has a negative impact on their performance during the test phase. Positional embeddings are a crucial component of ViTs, as they encode the spatial relationships between different parts of the input image.
The paper provides a detailed analysis of this problem, explaining that achieving a stable effect from positional embedding requires a specific condition on the image, which is often violated by current data augmentation methods. The researchers then propose the correct configuration for these data augmentations to remove the side effects of the variance shift.
Experimental results show that adopting the researchers' guidelines for data augmentation can improve the performance of ViTs compared to the current standard configuration. This suggests that the variance shift in positional embeddings caused by certain data augmentations is a significant, yet previously overlooked, factor that can degrade the performance of ViTs.
Critical Analysis
The paper presents a valuable insight into a potential vulnerability in the use of data augmentation techniques for training Vision Transformers. By identifying the issue of variance shift in positional embeddings, the researchers highlight an important consideration that has been overlooked in the current state of the art.
However, the paper does not provide a comprehensive analysis of the generalizability of this problem. It would be helpful to understand if the variance shift issue is specific to certain ViT architectures or if it is a more widespread phenomenon. Additionally, the paper could have explored the potential impact of this issue on other types of vision models, not just ViTs.
Furthermore, the paper does not delve into the underlying reasons for the variance shift caused by specific data augmentation techniques. A deeper exploration of the mathematical or theoretical foundations of this problem could provide more insights and potentially lead to more robust solutions.
Despite these limitations, the paper is a valuable contribution to the field of computer vision, as it raises an important issue that should be addressed by the research community. The researchers' guidelines for configuring data augmentations to mitigate the variance shift problem are a practical step towards improving the performance of ViTs and potentially other vision models as well.
Conclusion
This paper uncovers a significant vulnerability in the use of rich data augmentations, such as Mixup, Cutmix, and random erasing, for training Vision Transformers (ViTs). The researchers demonstrate that certain data augmentations can cause a variance shift in the positional embeddings of ViTs, which can degrade their performance during the test phase.
By providing a detailed analysis of this problem and guidelines for the correct configuration of these data augmentations, the paper offers a practical solution to improve the performance of ViTs. This work highlights the importance of understanding the underlying factors that can impact the effectiveness of deep learning models, especially in the context of advanced techniques like ViTs.
The findings of this paper have the potential to shape the future development of data augmentation strategies for ViTs and other vision models, as researchers and practitioners seek to leverage the power of these transformers while addressing their vulnerabilities. Ultimately, this research contributes to the ongoing effort to create more robust and reliable computer vision systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Configuring Data Augmentations to Reduce Variance Shift in Positional Embedding of Vision Transformers
Bum Jun Kim, Sang Woo Kim
Vision transformers (ViTs) have demonstrated remarkable performance in a variety of vision tasks. Despite their promising capabilities, training a ViT requires a large amount of diverse data. Several studies empirically found that using rich data augmentations, such as Mixup, Cutmix, and random erasing, is critical to the successful training of ViTs. Now, the use of rich data augmentations has become a standard practice in the current state. However, we report a vulnerability to this practice: Certain data augmentations such as Mixup cause a variance shift in the positional embedding of ViT, which has been a hidden factor that degrades the performance of ViT during the test phase. We claim that achieving a stable effect from positional embedding requires a specific condition on the image, which is often broken for the current data augmentation methods. We provide a detailed analysis of this problem as well as the correct configuration for these data augmentations to remove the side effects of variance shift. Experiments showed that adopting our guidelines improves the performance of ViTs compared with the current configuration of data augmentations.
Read more5/24/2024

0
A Survey on Mixup Augmentations and Beyond
Xin Jin, Hongyu Zhu, Siyuan Li, Zedong Wang, Zicheng Liu, Chang Yu, Huafeng Qin, Stan Z. Li
As Deep Neural Networks have achieved thrilling breakthroughs in the past decade, data augmentations have garnered increasing attention as regularization techniques when massive labeled data are unavailable. Among existing augmentations, Mixup and relevant data-mixing methods that convexly combine selected samples and the corresponding labels are widely adopted because they yield high performances by generating data-dependent virtual data while easily migrating to various domains. This survey presents a comprehensive review of foundational mixup methods and their applications. We first elaborate on the training pipeline with mixup augmentations as a unified framework containing modules. A reformulated framework could contain various mixup methods and give intuitive operational procedures. Then, we systematically investigate the applications of mixup augmentations on vision downstream tasks, various data modalities, and some analysis & theorems of mixup. Meanwhile, we conclude the current status and limitations of mixup research and point out further work for effective and efficient mixup augmentations. This survey can provide researchers with the current state of the art in mixup methods and provide some insights and guidance roles in the mixup arena. An online project with this survey is available at url{https://github.com/Westlake-AI/Awesome-Mixup}.
Read more9/10/2024
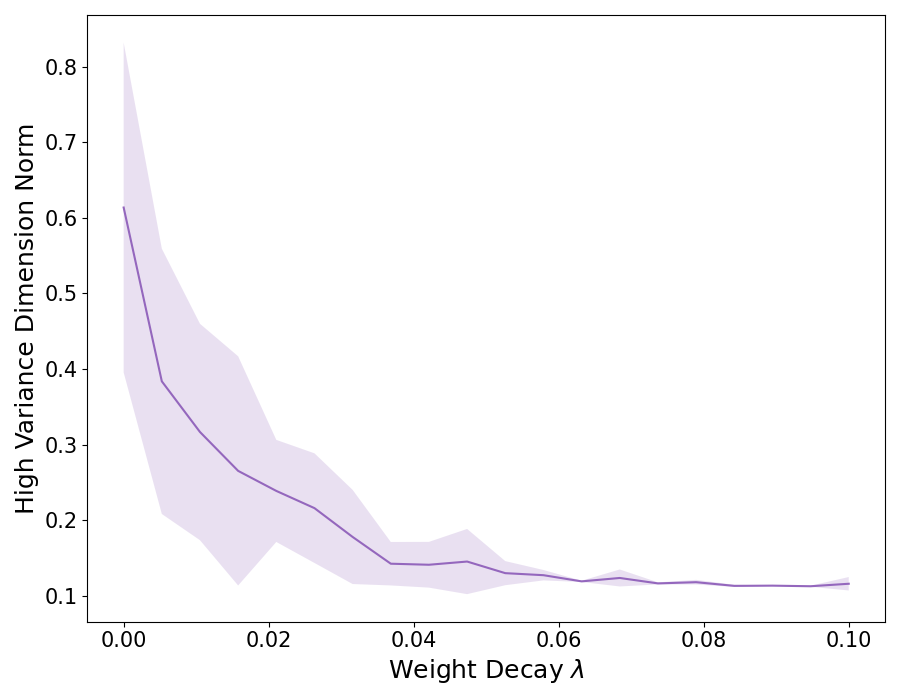
0
For Better or For Worse? Learning Minimum Variance Features With Label Augmentation
Muthu Chidambaram, Rong Ge
Data augmentation has been pivotal in successfully training deep learning models on classification tasks over the past decade. An important subclass of data augmentation techniques - which includes both label smoothing and Mixup - involves modifying not only the input data but also the input label during model training. In this work, we analyze the role played by the label augmentation aspect of such methods. We first prove that linear models on binary classification data trained with label augmentation learn only the minimum variance features in the data, while standard training (which includes weight decay) can learn higher variance features. We then use our techniques to show that even for nonlinear models and general data distributions, the label smoothing and Mixup losses are lower bounded by a function of the model output variance. An important consequence of our results is negative: label smoothing and Mixup can be less robust to spurious correlations in the data. We verify that our theory reflects practice via experiments on image classification benchmarks modified to have spurious correlations.
Read more5/28/2024

0
Region Mixup
Saptarshi Saha, Utpal Garain
This paper introduces a simple extension of mixup (Zhang et al., 2018) data augmentation to enhance generalization in visual recognition tasks. Unlike the vanilla mixup method, which blends entire images, our approach focuses on combining regions from multiple images.
Read more9/24/2024