Conformer-Based Speech Recognition On Extreme Edge-Computing Devices
2312.10359
2
0
🗣️
Abstract
With increasingly more powerful compute capabilities and resources in today's devices, traditionally compute-intensive automatic speech recognition (ASR) has been moving from the cloud to devices to better protect user privacy. However, it is still challenging to implement on-device ASR on resource-constrained devices, such as smartphones, smart wearables, and other smart home automation devices. In this paper, we propose a series of model architecture adaptions, neural network graph transformations, and numerical optimizations to fit an advanced Conformer based end-to-end streaming ASR system on resource-constrained devices without accuracy degradation. We achieve over 5.26 times faster than realtime (0.19 RTF) speech recognition on smart wearables while minimizing energy consumption and achieving state-of-the-art accuracy. The proposed methods are widely applicable to other transformer-based server-free AI applications. In addition, we provide a complete theory on optimal pre-normalizers that numerically stabilize layer normalization in any Lp-norm using any floating point precision.
Get summaries of the top AI research delivered straight to your inbox:
Introduction
The paper discusses optimizations to enable end-to-end (E2E) fully neural network-based automatic speech recognition (ASR) systems on resource-constrained devices like smartphones, wearables, and home automation devices. E2E ASR systems have several advantages over conventional hybrid hidden Markov model-based ASR, including a simplified training procedure, better word error rate performance, and the ability to better utilize hardware accelerators like GPUs, TPUs, and Apple's Neural Engine for high throughput and energy efficiency.
Unlike conventional ASR systems that require computationally expensive decoders, E2E ASR systems can operate fully offline, saving cloud computing resources and providing stronger user privacy. However, deploying these systems on resource-constrained devices presents challenges due to hardware limitations.
The paper explores multidisciplinary solutions, such as memory-aware network transformation, model structural adjustment, and numerical optimizations to address inference stability. It specifically focuses on leveraging the inference efficiency of specialty hardware accelerators.
The authors derive a theory to numerically stabilize the computation of layer normalization on hardware accelerators. This stabilization technique does not require model retraining and is applicable to the computation of any Lp-norm.
Prior Work
The provided text discusses various approaches to improve the computational efficiency of the Transformer architecture, which has garnered significant interest. It highlights several notable works that focus on optimizing the model architecture itself.
Linear Transformer (Katharopoulos et al. 2020) is a key technique that addresses the computationally expensive softmax function within the attention mechanism, which is also susceptible to numerical overflow issues. Alternative normalization methods, such as those discussed in Hoffer et al. (2018) and Zhang and Sennrich (2019), are explored to enhance computational efficiency and numerical stability in low-precision environments.
The text mentions principles for optimizing Transformers on Apple hardware, as outlined in Apple (2022), which are generally applicable to similar devices.
In the domain of speech recognition, Squeezeformer (Kim et al. 2022) is a seminal work that focuses on efficiency optimization, particularly for the Conformer architecture. It employs depthwise separable convolution subsampling, inspired by MobileNet (Howard et al. 2017), to substantially reduce computation.
The majority of prior work concentrates on improving training efficiency by modifying the existing model architecture, requiring model retraining to achieve efficiency gains. In contrast, the research discussed in the text primarily focuses on post-training, inference-only processes while avoiding model retraining whenever possible.
Model Architecture
The paper describes the foundational architecture of their model, which is built on the Conformer connectionist temporal classification (CTC) automatic speech recognition (ASR) system. The key components are:
Acoustic Encoder:
- Stacks transformer and convolution layers alternatively to capture long-term dependencies and local patterns in speech frames.
- Uses relative sinusoidal positional encoding in the transformer layers.
- Adopts a chunk-based attention strategy to balance accuracy and dependency on future audio frames for streaming on edge devices.
Objective Functions:
- Trains the model using a multitask objective combining Connectionist Temporal Classification (CTC) and Attention-based Encoder Decoder (AED).
- Uses only CTC for decoding.
To reduce computational requirements for resource-constrained devices, the paper substitutes vanilla 2D convolution with depthwise separable convolution in the subsampling module. This change reduces the computational bottleneck from 32.8% to 4.0% while maintaining word error rate (WER) performance.
The paper notes that while depthwise separable convolution is known for its computational efficiency and small memory footprint, its effect on reducing the dynamic range of outputs needs further study. Reducing dynamic range is important for low-precision hardware accelerators in edge devices to avoid overflow issues.
Performance Optimizations
The section describes specific optimizations implemented to achieve high performance execution of a modified Conformer model on smartphones and wearable devices. It follows four principles for optimizing transformers on the Apple Neural Engine (ANE):
-
Picking the right data format: Using the (B, C, 1, S) {Batch, Channel, 1, Sequence} tensor shape to align with ANE's architecture.
-
Chunking large intermediate tensors: Using split and concatenation operations to divide tensors into smaller chunks for better cache utilization.
-
Minimizing memory copies: Minimizing reshape and transpose operations, and representing batch matrix multiplications using Einstein summation layers.
-
Handling bandwidth-boundness: Carefully benchmarking performance with different batch sizes and sequence lengths to account for memory fetch costs.
The authors adhered to these principles, including transposing inputs, using split/concat, and replacing batch matrix multiplications with Einstein summations.
It then describes an optimal low-precision pre-normalizer technique to combat numerical instabilities in layer normalization on low-precision hardware. Theoretical analysis shows this pre-normalizer maps any input distribution to the precise maximum value supported by the hardware's low-precision format.
Finally, it introduces conditional re-scaling for softmax layers when hardware lacks native exponential operation support. This re-scales inputs into a range where lookup tables can provide accurate approximations.
The techniques aim to maximize performance on mobile hardware accelerators like ANE while ensuring numerical accuracy despite low-precision constraints.
Experiments and Results
The provided text describes the experimental setup and results for evaluating different convolutional neural network architectures for speech recognition on mobile devices. Here are the key points:
Setup:
- The training data contains 17,000 hours of audio-transcript pairs from virtual assistant queries.
- Two model architectures (conv2d6 and dws2d6) were trained with different subsampling strategies.
- Two additional models (conv2d6x22 and dws2d6x22) used a scaling factor from the transformer work.
- Experiments were conducted on iPhone XR and Apple Watch Series 7 devices.
Performance:
- Models running on CPUs did not meet the real-time factor (RTF) target of 0.5.
- Using hardware accelerators brought the RTF down by an order of magnitude, achieving the 0.5 target.
- On the Apple Watch, the accelerated models were 5.26 times faster.
Energy:
- Hardware accelerators also reduced energy consumption by an order of magnitude compared to running on CPUs.
Numeric Stability:
- Depthwise separable convolutions (DWS) had a smaller dynamic range than vanilla 2D convolutions.
- Removing the scaling factor further improved numeric stability.
- Overflow statistics showed the need for techniques to prevent overflows.
Quality:
- There was negligible difference in word error rate (WER) between FP16 and FP32 precision.
- DWS and vanilla convolutions yielded similar WER.
- The scaling factor did not improve WER and caused overflow issues.
Conclusions
Here is a summary of the provided text:
The paper discusses optimizations made to Conformer CTC (Connectionist Temporal Classification) automatic speech recognition models to enable their deployment on resource-constrained devices like mobile phones and wearables. Through architectural, model-level, and numerical adjustments, the authors demonstrate that these models can achieve real-time or faster performance while consuming less energy, all without sacrificing recognition accuracy. The paper's findings on numerical stabilization techniques have broader applicability beyond just speech models, extending to various deep learning architectures and computing tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
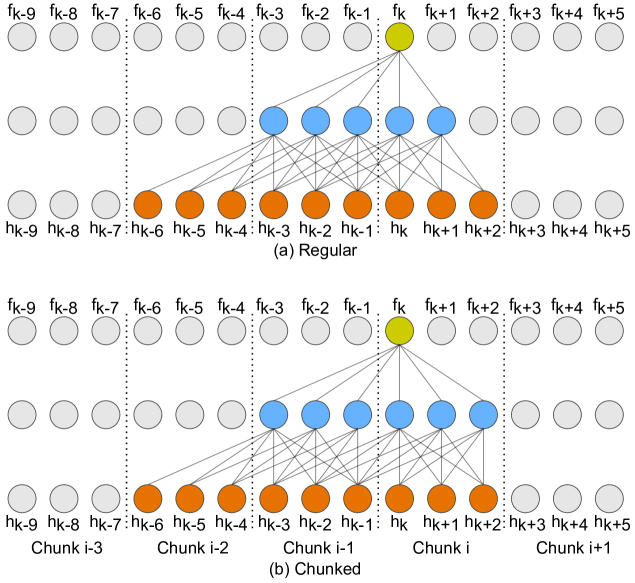
Stateful Conformer with Cache-based Inference for Streaming Automatic Speech Recognition
Vahid Noroozi, Somshubra Majumdar, Ankur Kumar, Jagadeesh Balam, Boris Ginsburg
0
0
In this paper, we propose an efficient and accurate streaming speech recognition model based on the FastConformer architecture. We adapted the FastConformer architecture for streaming applications through: (1) constraining both the look-ahead and past contexts in the encoder, and (2) introducing an activation caching mechanism to enable the non-autoregressive encoder to operate autoregressively during inference. The proposed model is thoughtfully designed in a way to eliminate the accuracy disparity between the train and inference time which is common for many streaming models. Furthermore, our proposed encoder works with various decoder configurations including Connectionist Temporal Classification (CTC) and RNN-Transducer (RNNT) decoders. Additionally, we introduced a hybrid CTC/RNNT architecture which utilizes a shared encoder with both a CTC and RNNT decoder to boost the accuracy and save computation. We evaluate the proposed model on LibriSpeech dataset and a multi-domain large scale dataset and demonstrate that it can achieve better accuracy with lower latency and inference time compared to a conventional buffered streaming model baseline. We also showed that training a model with multiple latencies can achieve better accuracy than single latency models while it enables us to support multiple latencies with a single model. Our experiments also showed the hybrid architecture would not only speedup the convergence of the CTC decoder but also improves the accuracy of streaming models compared to single decoder models.
5/6/2024

Conformer-1: Robust ASR via Large-Scale Semisupervised Bootstrapping
Kevin Zhang, Luka Chkhetiani, Francis McCann Ramirez, Yash Khare, Andrea Vanzo, Michael Liang, Sergio Ramirez Martin, Gabriel Oexle, Ruben Bousbib, Taufiquzzaman Peyash, Michael Nguyen, Dillon Pulliam, Domenic Donato
0
0
This paper presents Conformer-1, an end-to-end Automatic Speech Recognition (ASR) model trained on an extensive dataset of 570k hours of speech audio data, 91% of which was acquired from publicly available sources. To achieve this, we perform Noisy Student Training after generating pseudo-labels for the unlabeled public data using a strong Conformer RNN-T baseline model. The addition of these pseudo-labeled data results in remarkable improvements in relative Word Error Rate (WER) by 11.5% and 24.3% for our asynchronous and realtime models, respectively. Additionally, the model is more robust to background noise owing to the addition of these data. The results obtained in this study demonstrate that the incorporation of pseudo-labeled publicly available data is a highly effective strategy for improving ASR accuracy and noise robustness.
4/16/2024
🤿
Deep Learning Models in Speech Recognition: Measuring GPU Energy Consumption, Impact of Noise and Model Quantization for Edge Deployment
Aditya Chakravarty
0
0
Recent transformer-based ASR models have achieved word-error rates (WER) below 4%, surpassing human annotator accuracy, yet they demand extensive server resources, contributing to significant carbon footprints. The traditional server-based architecture of ASR also presents privacy concerns, alongside reliability and latency issues due to network dependencies. In contrast, on-device (edge) ASR enhances privacy, boosts performance, and promotes sustainability by effectively balancing energy use and accuracy for specific applications. This study examines the effects of quantization, memory demands, and energy consumption on the performance of various ASR model inference on the NVIDIA Jetson Orin Nano. By analyzing WER and transcription speed across models using FP32, FP16, and INT8 quantization on clean and noisy datasets, we highlight the crucial trade-offs between accuracy, speeds, quantization, energy efficiency, and memory needs. We found that changing precision from fp32 to fp16 halves the energy consumption for audio transcription across different models, with minimal performance degradation. A larger model size and number of parameters neither guarantees better resilience to noise, nor predicts the energy consumption for a given transcription load. These, along with several other findings offer novel insights for optimizing ASR systems within energy- and memory-limited environments, crucial for the development of efficient on-device ASR solutions. The code and input data needed to reproduce the results in this article are open sourced are available on [https://github.com/zzadiues3338/ASR-energy-jetson].
5/3/2024
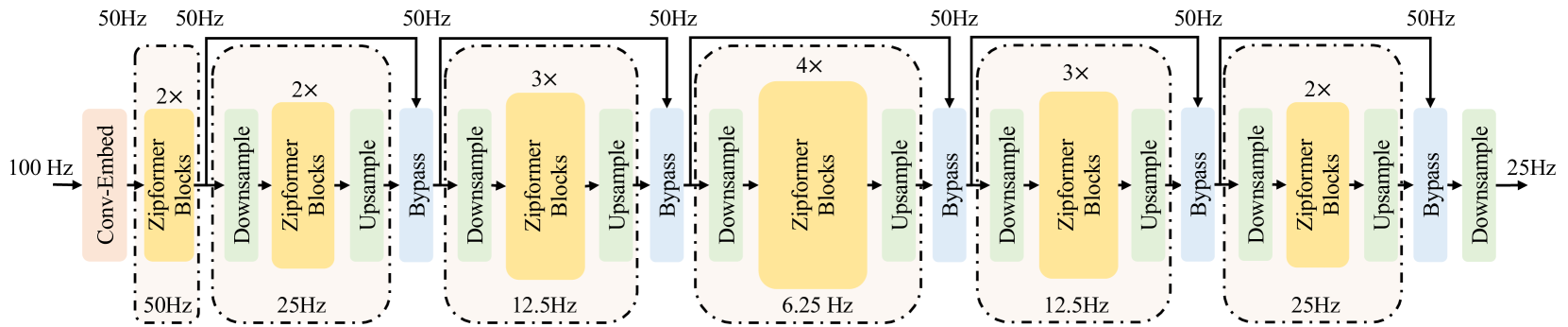
Zipformer: A faster and better encoder for automatic speech recognition
Zengwei Yao, Liyong Guo, Xiaoyu Yang, Wei Kang, Fangjun Kuang, Yifan Yang, Zengrui Jin, Long Lin, Daniel Povey
0
0
The Conformer has become the most popular encoder model for automatic speech recognition (ASR). It adds convolution modules to a transformer to learn both local and global dependencies. In this work we describe a faster, more memory-efficient, and better-performing transformer, called Zipformer. Modeling changes include: 1) a U-Net-like encoder structure where middle stacks operate at lower frame rates; 2) reorganized block structure with more modules, within which we re-use attention weights for efficiency; 3) a modified form of LayerNorm called BiasNorm allows us to retain some length information; 4) new activation functions SwooshR and SwooshL work better than Swish. We also propose a new optimizer, called ScaledAdam, which scales the update by each tensor's current scale to keep the relative change about the same, and also explictly learns the parameter scale. It achieves faster convergence and better performance than Adam. Extensive experiments on LibriSpeech, Aishell-1, and WenetSpeech datasets demonstrate the effectiveness of our proposed Zipformer over other state-of-the-art ASR models. Our code is publicly available at https://github.com/k2-fsa/icefall.
4/11/2024