Zipformer: A faster and better encoder for automatic speech recognition
2310.11230
0
0
Abstract
The Conformer has become the most popular encoder model for automatic speech recognition (ASR). It adds convolution modules to a transformer to learn both local and global dependencies. In this work we describe a faster, more memory-efficient, and better-performing transformer, called Zipformer. Modeling changes include: 1) a U-Net-like encoder structure where middle stacks operate at lower frame rates; 2) reorganized block structure with more modules, within which we re-use attention weights for efficiency; 3) a modified form of LayerNorm called BiasNorm allows us to retain some length information; 4) new activation functions SwooshR and SwooshL work better than Swish. We also propose a new optimizer, called ScaledAdam, which scales the update by each tensor's current scale to keep the relative change about the same, and also explictly learns the parameter scale. It achieves faster convergence and better performance than Adam. Extensive experiments on LibriSpeech, Aishell-1, and WenetSpeech datasets demonstrate the effectiveness of our proposed Zipformer over other state-of-the-art ASR models. Our code is publicly available at https://github.com/k2-fsa/icefall.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Proposes a new encoder architecture called Zipformer for automatic speech recognition (ASR)
- Claims Zipformer is faster and achieves better performance than existing encoders
- Evaluates Zipformer on multiple ASR benchmarks
Plain English Explanation
The paper introduces a new type of encoder, called Zipformer, that can be used in automatic speech recognition (ASR) systems. ASR systems convert spoken audio into text, and the encoder is a key component that processes the audio input.
The researchers claim that Zipformer is both faster and more accurate than existing encoder models used in ASR. This means it can process audio inputs more quickly, while also producing more reliable text transcriptions. The authors evaluate Zipformer on several standard ASR benchmarks and show that it outperforms other popular encoder architectures.
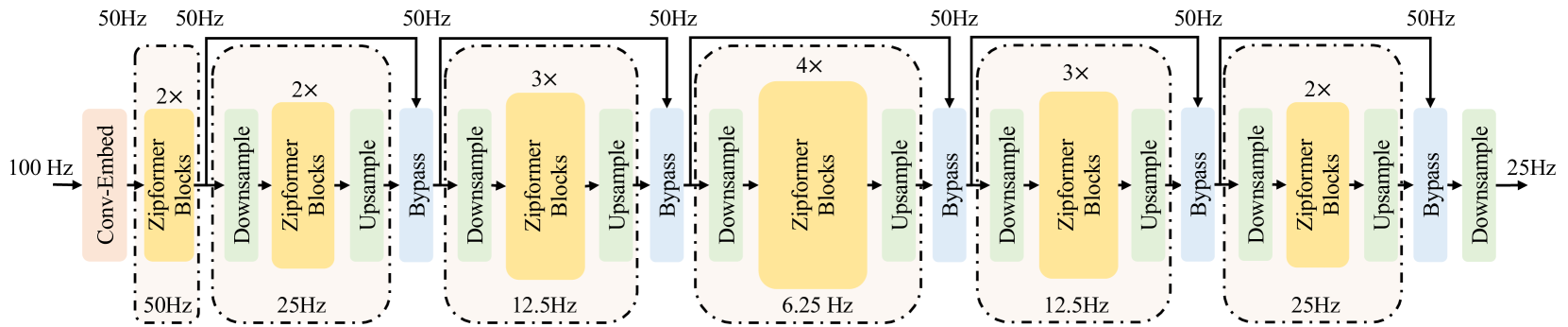
The key innovation in Zipformer is a "downsampled encoding" approach that reduces the computational cost of the model, making it faster, without sacrificing accuracy. The paper provides technical details on this downsampling method and other architectural choices that contribute to Zipformer's improved performance.
Overall, the work presents a new encoder model that could lead to more efficient and effective ASR systems, with potential applications in areas like voice assistants, transcription services, and speech-based interfaces.
Technical Explanation
The paper introduces a novel encoder architecture called Zipformer that is designed for automatic speech recognition (ASR) tasks. The Zipformer encoder builds upon the success of Transformer models [link to Transformer paper] but incorporates several key modifications to improve computational efficiency and recognition accuracy.
A key innovation in Zipformer is its "downsampled encoding" approach. Rather than processing the full audio input sequence at each layer, Zipformer progressively downsamples the sequence, reducing the computational cost as the network goes deeper. This is achieved through a series of convolutional and pooling layers that gradually decrease the sequence length while increasing the feature dimensionality.
The authors also incorporate other architectural improvements, such as the use of ConvoiFilter for improved speech encoding and Uformer-inspired skip connections to better preserve input features. Additionally, Zipformer utilizes Transducer-based training to directly optimize for sequence prediction.
The paper evaluates Zipformer on several standard ASR benchmarks, including LibriSpeech and Switchboard, and demonstrates that it outperforms other popular encoder architectures, such as Conformer, in both speed and accuracy.
Critical Analysis
The authors provide a thorough evaluation of Zipformer and present compelling evidence for its advantages over existing encoders. However, the paper does not extensively discuss the potential limitations or caveats of the proposed approach.
One area that could benefit from further exploration is the impact of the downsampling mechanism on the model's ability to capture fine-grained speech features, especially for tasks that require high-resolution audio processing. The authors mention that the downsampling is gradually performed, but the precise tradeoffs between computational efficiency and information preservation are not fully examined.
Additionally, the paper focuses on standard ASR benchmarks, but it would be valuable to understand how Zipformer performs in more real-world, noisy, or low-resource scenarios. The ability to generalize to diverse acoustic conditions is an important consideration for practical ASR deployments.
Finally, the paper does not delve into the potential memory and storage requirements of Zipformer, which can be crucial factors for deployment on resource-constrained edge devices or mobile platforms. Further analysis of the model's efficiency across different hardware and deployment scenarios would strengthen the practical implications of this work.
Conclusion
The Zipformer encoder proposed in this paper represents a promising advancement in the field of automatic speech recognition. By introducing a downsampled encoding approach and other architectural innovations, the authors demonstrate that Zipformer can achieve faster processing and better recognition accuracy compared to existing encoder models.
The technical details and experimental results presented in the paper suggest that Zipformer could have a significant impact on the development of more efficient and effective ASR systems. This could lead to improvements in a wide range of applications, from voice assistants and transcription services to speech-based human-computer interactions.
While the paper provides a solid foundation, further research is needed to address potential limitations and explore the broader applicability of Zipformer across diverse real-world scenarios. Addressing these areas can help unlock the full potential of this novel encoder architecture and contribute to the ongoing progress in automatic speech recognition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Stateful Conformer with Cache-based Inference for Streaming Automatic Speech Recognition
Vahid Noroozi, Somshubra Majumdar, Ankur Kumar, Jagadeesh Balam, Boris Ginsburg
0
0
In this paper, we propose an efficient and accurate streaming speech recognition model based on the FastConformer architecture. We adapted the FastConformer architecture for streaming applications through: (1) constraining both the look-ahead and past contexts in the encoder, and (2) introducing an activation caching mechanism to enable the non-autoregressive encoder to operate autoregressively during inference. The proposed model is thoughtfully designed in a way to eliminate the accuracy disparity between the train and inference time which is common for many streaming models. Furthermore, our proposed encoder works with various decoder configurations including Connectionist Temporal Classification (CTC) and RNN-Transducer (RNNT) decoders. Additionally, we introduced a hybrid CTC/RNNT architecture which utilizes a shared encoder with both a CTC and RNNT decoder to boost the accuracy and save computation. We evaluate the proposed model on LibriSpeech dataset and a multi-domain large scale dataset and demonstrate that it can achieve better accuracy with lower latency and inference time compared to a conventional buffered streaming model baseline. We also showed that training a model with multiple latencies can achieve better accuracy than single latency models while it enables us to support multiple latencies with a single model. Our experiments also showed the hybrid architecture would not only speedup the convergence of the CTC decoder but also improves the accuracy of streaming models compared to single decoder models.
5/6/2024
🗣️
Conformer-Based Speech Recognition On Extreme Edge-Computing Devices
Mingbin Xu, Alex Jin, Sicheng Wang, Mu Su, Tim Ng, Henry Mason, Shiyi Han, Zhihong Lei, Yaqiao Deng, Zhen Huang, Mahesh Krishnamoorthy
0
0
With increasingly more powerful compute capabilities and resources in today's devices, traditionally compute-intensive automatic speech recognition (ASR) has been moving from the cloud to devices to better protect user privacy. However, it is still challenging to implement on-device ASR on resource-constrained devices, such as smartphones, smart wearables, and other smart home automation devices. In this paper, we propose a series of model architecture adaptions, neural network graph transformations, and numerical optimizations to fit an advanced Conformer based end-to-end streaming ASR system on resource-constrained devices without accuracy degradation. We achieve over 5.26 times faster than realtime (0.19 RTF) speech recognition on smart wearables while minimizing energy consumption and achieving state-of-the-art accuracy. The proposed methods are widely applicable to other transformer-based server-free AI applications. In addition, we provide a complete theory on optimal pre-normalizers that numerically stabilize layer normalization in any Lp-norm using any floating point precision.
5/15/2024

Conformer-1: Robust ASR via Large-Scale Semisupervised Bootstrapping
Kevin Zhang, Luka Chkhetiani, Francis McCann Ramirez, Yash Khare, Andrea Vanzo, Michael Liang, Sergio Ramirez Martin, Gabriel Oexle, Ruben Bousbib, Taufiquzzaman Peyash, Michael Nguyen, Dillon Pulliam, Domenic Donato
0
0
This paper presents Conformer-1, an end-to-end Automatic Speech Recognition (ASR) model trained on an extensive dataset of 570k hours of speech audio data, 91% of which was acquired from publicly available sources. To achieve this, we perform Noisy Student Training after generating pseudo-labels for the unlabeled public data using a strong Conformer RNN-T baseline model. The addition of these pseudo-labeled data results in remarkable improvements in relative Word Error Rate (WER) by 11.5% and 24.3% for our asynchronous and realtime models, respectively. Additionally, the model is more robust to background noise owing to the addition of these data. The results obtained in this study demonstrate that the incorporation of pseudo-labeled publicly available data is a highly effective strategy for improving ASR accuracy and noise robustness.
4/16/2024
IceFormer: Accelerated Inference with Long-Sequence Transformers on CPUs
Yuzhen Mao, Martin Ester, Ke Li
0
0
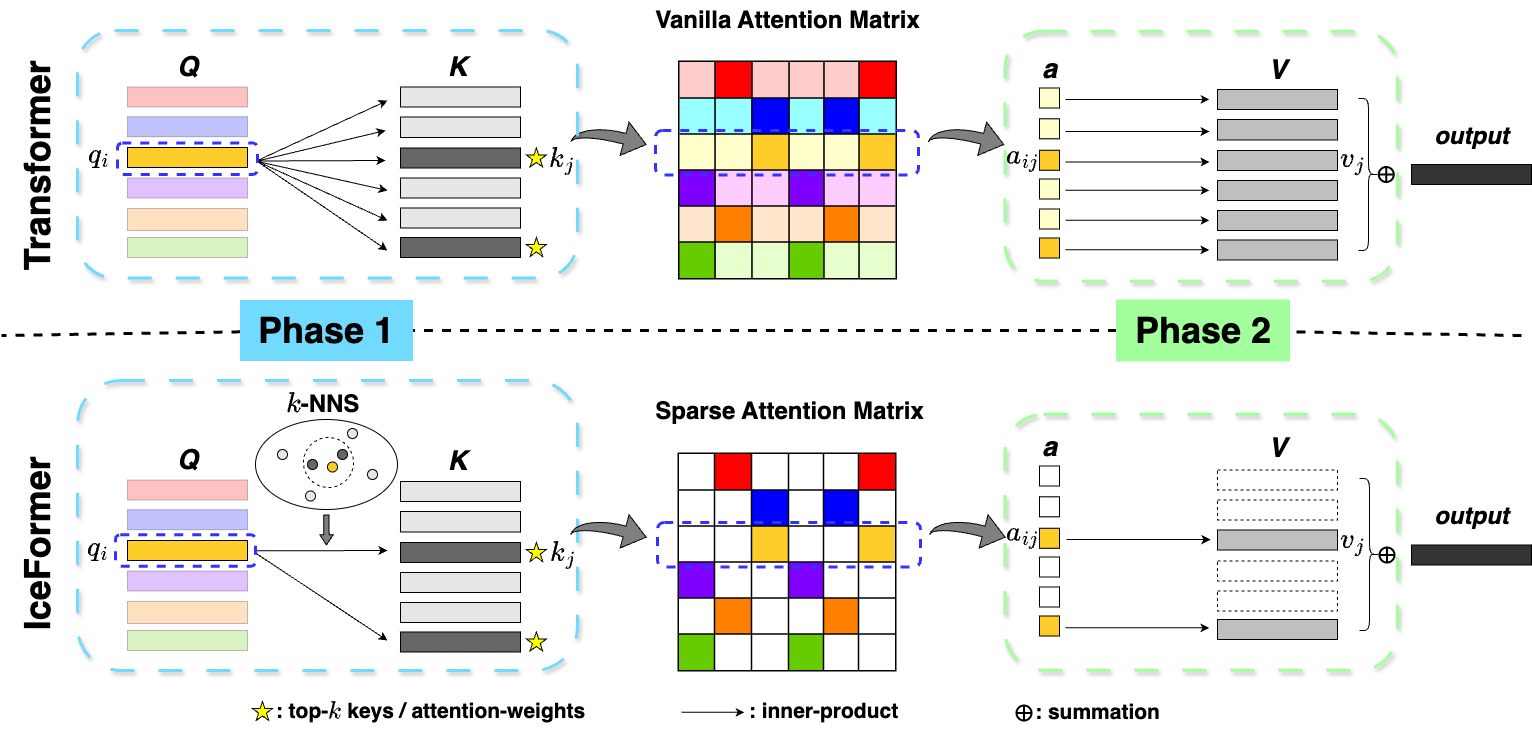
One limitation of existing Transformer-based models is that they cannot handle very long sequences as input since their self-attention operations exhibit quadratic time and space complexity. This problem becomes especially acute when Transformers are deployed on hardware platforms equipped only with CPUs. To address this issue, we propose a novel method for accelerating self-attention at inference time that works with pretrained Transformer models out-of-the-box without requiring retraining. We experiment using our method to accelerate various long-sequence Transformers, including a leading LLaMA 2-based LLM, on various benchmarks and demonstrate a greater speedup of 2.73x - 7.63x while retaining 98.6% - 99.6% of the accuracy of the original pretrained models. The code is available on our project website at https://yuzhenmao.github.io/IceFormer/.
5/7/2024