ConGraT: Self-Supervised Contrastive Pretraining for Joint Graph and Text Embeddings

0
🏷️
Sign in to get full access
Overview
- The paper proposes a new self-supervised approach called Contrastive Graph-Text pretraining (ConGraT) for jointly learning representations of text and graph data.
- Most previous methods make strong assumptions about the downstream task or rely on hand-labeled data, and fail to balance the importance of text and graph representations.
- ConGraT trains a language model (LM) and a graph neural network (GNN) to align their representations in a common latent space using a contrastive learning objective inspired by CLIP.
- The method also leverages graph structure to incorporate information about inter-node similarity into the contrastive objective.
Plain English Explanation
Graphs are mathematical structures used to model real-world relationships, like social networks or citation networks. In text-attributed graphs (TAGs), each node in the graph is associated with one or more text documents. Learning effective representations of both the graph structure and the text content is important for downstream tasks like node classification or link prediction.
However, most existing approaches make strong assumptions about the specific task at hand, or rely on having a lot of labeled data, which can be expensive to obtain. They also struggle to balance the relative importance of the text and graph information.
The ConGraT method proposed in this paper aims to address these challenges. It learns the representations of the text and graph data in a more general, self-supervised way, without assuming a specific task. The key idea is to train a language model (like UniGLM) and a graph neural network (like TAGA or PURE-Transformer) to produce representations that are aligned in a shared latent space. This allows the model to learn useful features from both the text and the graph structure.
The authors show that this approach outperforms previous methods on a variety of downstream tasks, like classifying node or text categories, predicting links between nodes, and language modeling. They also demonstrate an interesting application to community detection in social graphs, where the learned representations help find communities that are more textually coherent than those found using just the graph structure.
Technical Explanation
The key components of the ConGraT approach are:
-
Language Model (LM): A standard transformer-based language model is trained to encode the text associated with each node in the graph.
-
Graph Neural Network (GNN): A graph neural network is used to learn representations of the graph structure, capturing relationships between nodes.
-
Contrastive Alignment: The LM and GNN are trained jointly using a contrastive loss function inspired by CLIP. This encourages the model to learn representations where textually and graphically similar nodes are close together in the shared latent space.
-
Graph Structure Embedding: An additional term is added to the contrastive loss that leverages the graph structure to further improve the alignment between text and graph representations. This helps the model capture both semantic and structural relationships.
The authors evaluate ConGraT on a range of downstream tasks, including node classification, text classification, link prediction, and language modeling. They show that ConGraT outperforms previous state-of-the-art methods that either focus only on text or only on graph structure.
The authors also present an interesting application of ConGraT to community detection in social graphs. By utilizing the learned text-graph representations, their method is able to identify communities that are more textually coherent compared to those found using only the graph structure.
Critical Analysis
The authors acknowledge several limitations of their work:
- The approach assumes that the text associated with each node is relevant to the task at hand, which may not always be the case.
- The method relies on the availability of text-attributed graph data, which may not be readily available for all domains.
- The computational cost of training the LM and GNN jointly could be prohibitive for very large graphs.
Additional potential issues that were not addressed in the paper:
- The performance of ConGraT may be sensitive to the choice of hyperparameters, such as the relative weighting of the text and graph components in the contrastive loss.
- The method may struggle to capture higher-order structural patterns in the graph that are not well-reflected in the text content.
- Evaluating the interpretability and explainability of the learned representations could provide additional insights into the model's behavior.
Overall, the ConGraT approach represents an interesting and promising direction for jointly learning representations of text and graph data. However, further research may be needed to address some of the potential limitations and expand the applicability of the method to a wider range of real-world scenarios.
Conclusion
The ConGraT paper presents a novel self-supervised approach for learning representations of text-attributed graphs (TAGs), where each node is associated with one or more text documents. By jointly training a language model and a graph neural network using a contrastive alignment objective, ConGraT is able to effectively capture both the textual and structural information in the data.
The authors demonstrate that ConGraT outperforms previous state-of-the-art methods on a variety of downstream tasks, including node and text classification, link prediction, and language modeling. They also showcase an interesting application to community detection in social graphs, where the learned representations help identify communities that are more textually coherent than those found using only the graph structure.
While the proposed method has some limitations, the core idea of aligning text and graph representations in a shared latent space represents an important step forward in the field of representation learning for TAGs. As graph-based data becomes increasingly prevalent across various domains, techniques like ConGraT will play a crucial role in unlocking the full potential of these rich, multimodal datasets.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
0
ConGraT: Self-Supervised Contrastive Pretraining for Joint Graph and Text Embeddings
William Brannon, Wonjune Kang, Suyash Fulay, Hang Jiang, Brandon Roy, Deb Roy, Jad Kabbara
Learning on text-attributed graphs (TAGs), in which nodes are associated with one or more texts, has been the subject of much recent work. However, most approaches tend to make strong assumptions about the downstream task of interest, are reliant on hand-labeled data, or fail to equally balance the importance of both text and graph representations. In this work, we propose Contrastive Graph-Text pretraining (ConGraT), a general, self-supervised approach for jointly learning separate representations of texts and nodes in a TAG. Our method trains a language model (LM) and a graph neural network (GNN) to align their representations in a common latent space using a batch-wise contrastive learning objective inspired by CLIP. We further propose an extension to the CLIP objective that leverages graph structure to incorporate information about inter-node similarity. Extensive experiments demonstrate that ConGraT outperforms baselines on various downstream tasks, including node and text category classification, link prediction, and language modeling. Finally, we present an application of our method to community detection in social graphs, which enables finding more textually grounded communities, rather than purely graph-based ones. Code and certain datasets are available at https://github.com/wwbrannon/congrat.
Read more7/11/2024

0
GAugLLM: Improving Graph Contrastive Learning for Text-Attributed Graphs with Large Language Models
Yi Fang, Dongzhe Fan, Daochen Zha, Qiaoyu Tan
This work studies self-supervised graph learning for text-attributed graphs (TAGs) where nodes are represented by textual attributes. Unlike traditional graph contrastive methods that perturb the numerical feature space and alter the graph's topological structure, we aim to improve view generation through language supervision. This is driven by the prevalence of textual attributes in real applications, which complement graph structures with rich semantic information. However, this presents challenges because of two major reasons. First, text attributes often vary in length and quality, making it difficulty to perturb raw text descriptions without altering their original semantic meanings. Second, although text attributes complement graph structures, they are not inherently well-aligned. To bridge the gap, we introduce GAugLLM, a novel framework for augmenting TAGs. It leverages advanced large language models like Mistral to enhance self-supervised graph learning. Specifically, we introduce a mixture-of-prompt-expert technique to generate augmented node features. This approach adaptively maps multiple prompt experts, each of which modifies raw text attributes using prompt engineering, into numerical feature space. Additionally, we devise a collaborative edge modifier to leverage structural and textual commonalities, enhancing edge augmentation by examining or building connections between nodes. Empirical results across five benchmark datasets spanning various domains underscore our framework's ability to enhance the performance of leading contrastive methods as a plug-in tool. Notably, we observe that the augmented features and graph structure can also enhance the performance of standard generative methods, as well as popular graph neural networks. The open-sourced implementation of our GAugLLM is available at Github.
Read more6/19/2024
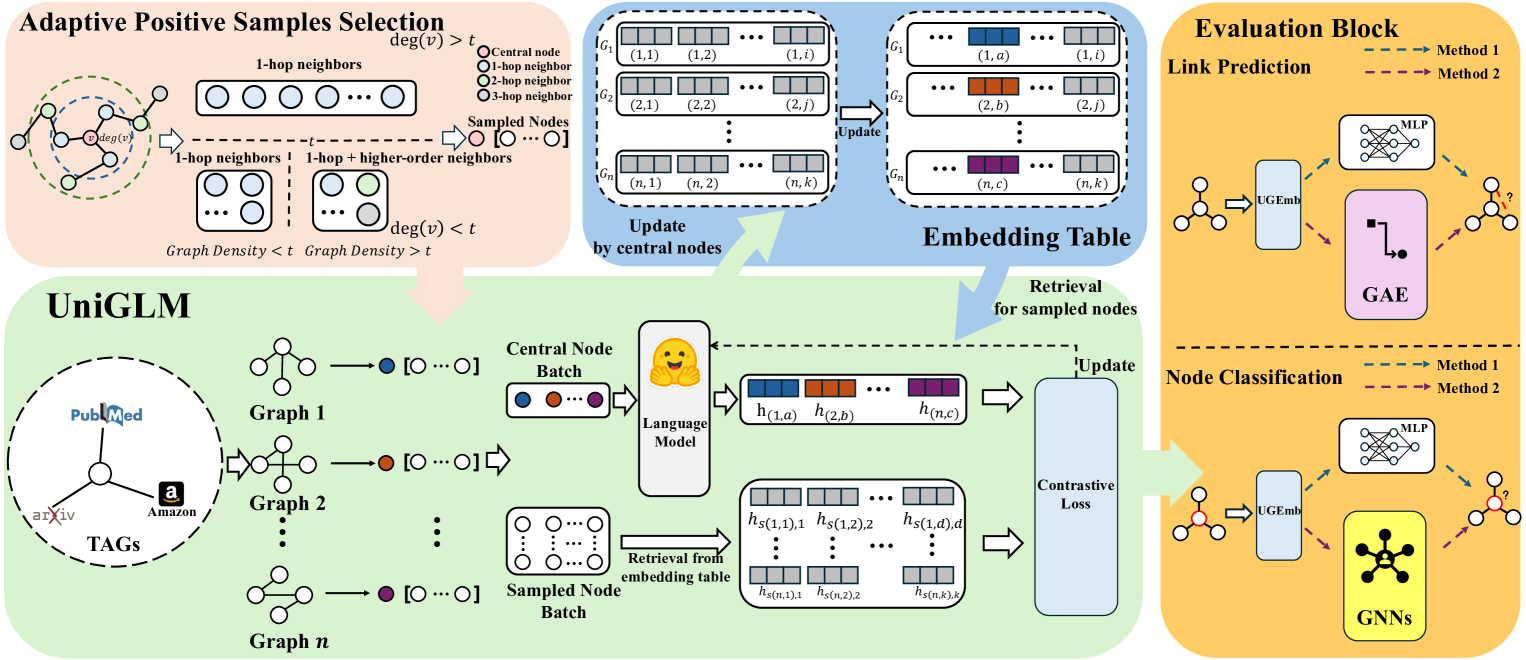
0
UniGLM: Training One Unified Language Model for Text-Attributed Graphs
Yi Fang, Dongzhe Fan, Sirui Ding, Ninghao Liu, Qiaoyu Tan
Representation learning on text-attributed graphs (TAGs), where nodes are represented by textual descriptions, is crucial for textual and relational knowledge systems and recommendation systems. Currently, state-of-the-art embedding methods for TAGs primarily focus on fine-tuning language models (e.g., BERT) using structure-aware training signals. While effective, these methods are tailored for individual TAG and cannot generalize across various graph scenarios. Given the shared textual space, leveraging multiple TAGs for joint fine-tuning, aligning text and graph structure from different aspects, would be more beneficial. Motivated by this, we introduce a novel Unified Graph Language Model (UniGLM) framework, the first graph embedding model that generalizes well to both in-domain and cross-domain TAGs. Specifically, UniGLM is trained over multiple TAGs with different domains and scales using self-supervised contrastive learning. UniGLM includes an adaptive positive sample selection technique for identifying structurally similar nodes and a lazy contrastive module that is devised to accelerate training by minimizing repetitive encoding calculations. Extensive empirical results across 9 benchmark TAGs demonstrate UniGLM's efficacy against leading embedding baselines in terms of generalization (various downstream tasks and backbones) and transfer learning (in and out of domain scenarios). The code is available at https://github.com/NYUSHCS/UniGLM.
Read more6/19/2024

0
TAGA: Text-Attributed Graph Self-Supervised Learning by Synergizing Graph and Text Mutual Transformations
Zheng Zhang, Yuntong Hu, Bo Pan, Chen Ling, Liang Zhao
Text-Attributed Graphs (TAGs) enhance graph structures with natural language descriptions, enabling detailed representation of data and their relationships across a broad spectrum of real-world scenarios. Despite the potential for deeper insights, existing TAG representation learning primarily relies on supervised methods, necessitating extensive labeled data and limiting applicability across diverse contexts. This paper introduces a new self-supervised learning framework, Text-And-Graph Multi-View Alignment (TAGA), which overcomes these constraints by integrating TAGs' structural and semantic dimensions. TAGA constructs two complementary views: Text-of-Graph view, which organizes node texts into structured documents based on graph topology, and the Graph-of-Text view, which converts textual nodes and connections into graph data. By aligning representations from both views, TAGA captures joint textual and structural information. In addition, a novel structure-preserving random walk algorithm is proposed for efficient training on large-sized TAGs. Our framework demonstrates strong performance in zero-shot and few-shot scenarios across eight real-world datasets.
Read more5/28/2024