Connecting Concept Convexity and Human-Machine Alignment in Deep Neural Networks

0

Sign in to get full access
Overview
- The paper explores the connection between concept convexity and human-machine alignment in deep neural networks.
- It investigates how the alignment between machine and human conceptual representations can be improved.
- The research aims to provide insights into making machine learning systems more aligned with human values and understanding.
Plain English Explanation
The paper examines the relationship between how deep neural networks understand and represent concepts and how well they align with human conceptual understanding.
The key idea is concept convexity - the notion that concepts in the human mind are often "convex", meaning they have clear boundaries and a distinct central tendency. The researchers explore whether encouraging neural networks to develop more "convex" internal representations of concepts can improve the alignment between the machine's and human's conceptual understanding.
By aligning the network's internal representations with how humans naturally think about concepts, the researchers aim to create machine learning systems that are better aligned with human values and perspectives. This could lead to AI assistants and decision-making systems that are more intuitive and trustworthy for people to interact with.
Technical Explanation
The paper first provides background on the concept convexity hypothesis - the idea that human conceptual representations tend to be convex, with clear prototypes and boundaries. The authors then discuss how this relates to the alignment between machine and human conceptual representations.
The core of the work involves training deep neural networks on various datasets and tasks, and then analyzing the resulting internal representations. The researchers investigate whether networks that develop more "convex" representations of concepts are also more aligned with human conceptual understanding.
Experiments are conducted across different network architectures, datasets, and training techniques to explore the generality of the findings. The authors analyze factors like the network's loss landscape, activation patterns, and generalization behavior to gain insights into the relationship between concept convexity and human-machine alignment.
Critical Analysis
The paper presents an intriguing hypothesis and provides initial empirical evidence to support the connection between concept convexity and human-machine alignment. However, the authors acknowledge that more research is needed to fully understand the mechanisms at play and the broader implications.
One limitation is that the experiments are primarily conducted on image classification tasks, so the findings may not generalize as readily to other domains like natural language processing or reinforcement learning. Additionally, the paper does not delve deeply into the potential downsides or unintended consequences of pursuing increased human-machine alignment.
Further research could explore how concept convexity relates to other desirable properties of machine learning systems, such as robustness, interpretability, and value alignment. It would also be valuable to investigate whether the insights from this work extend to more complex, open-ended tasks that require deeper reasoning and understanding.
Conclusion
This paper provides an intriguing perspective on the connection between the internal representations developed by deep neural networks and their alignment with human conceptual understanding. By exploring the notion of "concept convexity," the researchers offer a promising avenue for creating machine learning systems that are more intuitive and trustworthy for people to interact with.
While more research is needed to fully understand the implications, this work represents an important step towards bridging the gap between machine and human cognition. Ultimately, this could lead to the development of AI assistants and decision-making tools that are better aligned with human values and perspectives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Connecting Concept Convexity and Human-Machine Alignment in Deep Neural Networks
Teresa Dorszewski, Lenka Tv{e}tkov'a, Lorenz Linhardt, Lars Kai Hansen
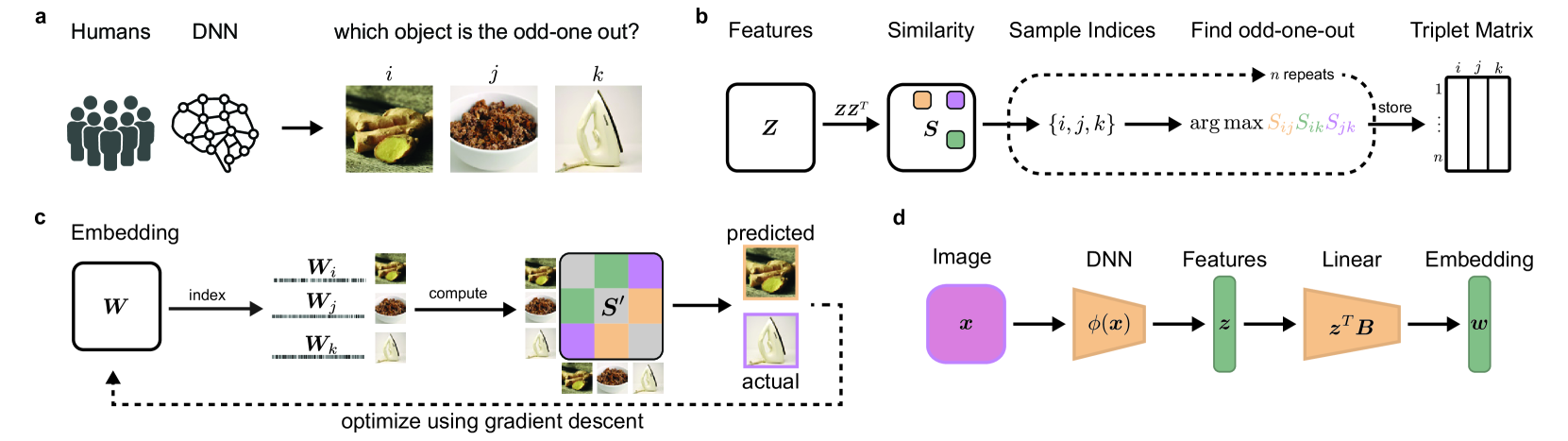
Understanding how neural networks align with human cognitive processes is a crucial step toward developing more interpretable and reliable AI systems. Motivated by theories of human cognition, this study examines the relationship between emph{convexity} in neural network representations and emph{human-machine alignment} based on behavioral data. We identify a correlation between these two dimensions in pretrained and fine-tuned vision transformer models. Our findings suggest that the convex regions formed in latent spaces of neural networks to some extent align with human-defined categories and reflect the similarity relations humans use in cognitive tasks. While optimizing for alignment generally enhances convexity, increasing convexity through fine-tuning yields inconsistent effects on alignment, which suggests a complex relationship between the two. This study presents a first step toward understanding the relationship between the convexity of latent representations and human-machine alignment.
Read more9/11/2024
0
Aligning Machine and Human Visual Representations across Abstraction Levels
Lukas Muttenthaler, Klaus Greff, Frieda Born, Bernhard Spitzer, Simon Kornblith, Michael C. Mozer, Klaus-Robert Muller, Thomas Unterthiner, Andrew K. Lampinen
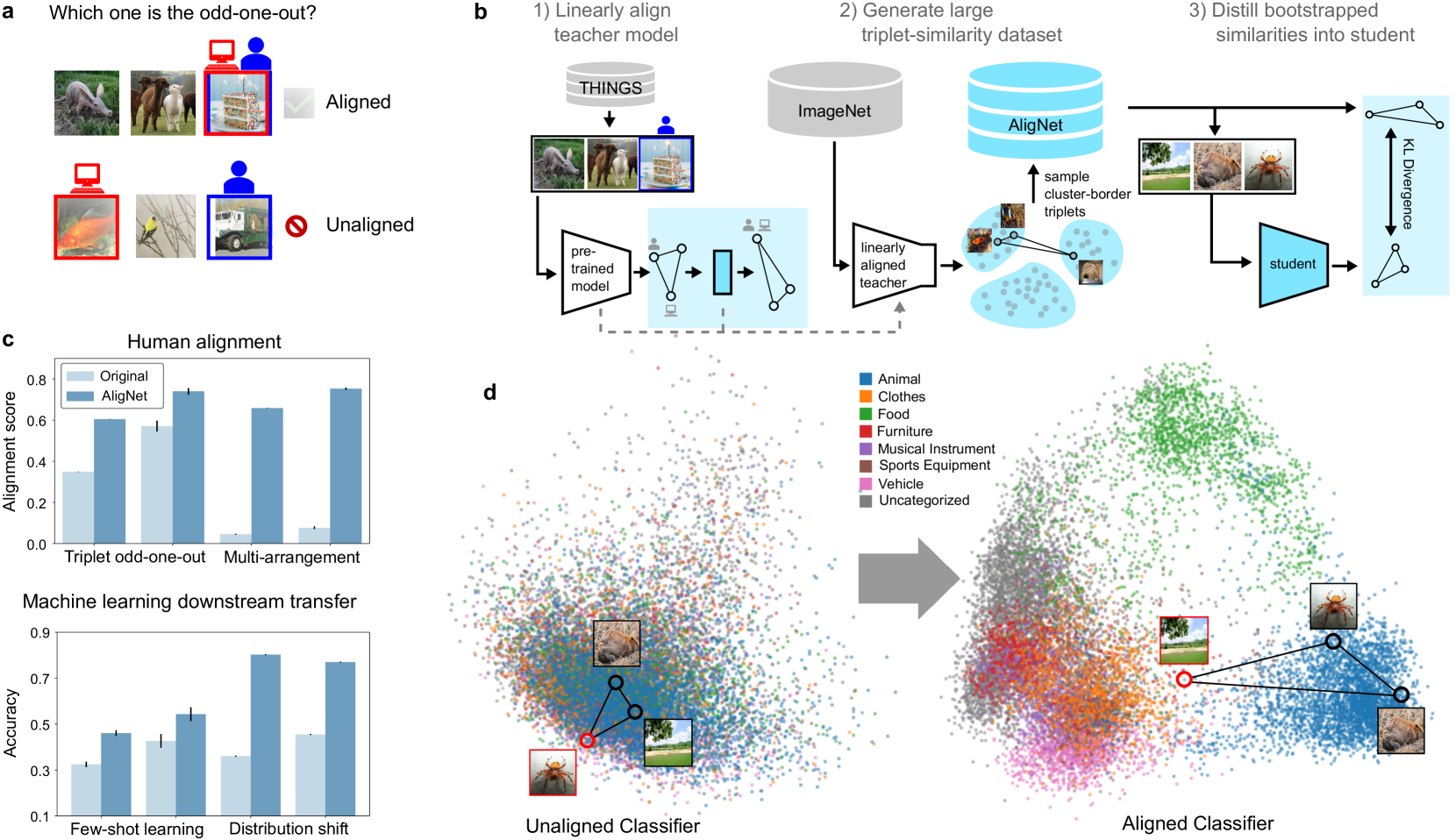
Deep neural networks have achieved success across a wide range of applications, including as models of human behavior in vision tasks. However, neural network training and human learning differ in fundamental ways, and neural networks often fail to generalize as robustly as humans do, raising questions regarding the similarity of their underlying representations. What is missing for modern learning systems to exhibit more human-like behavior? We highlight a key misalignment between vision models and humans: whereas human conceptual knowledge is hierarchically organized from fine- to coarse-scale distinctions, model representations do not accurately capture all these levels of abstraction. To address this misalignment, we first train a teacher model to imitate human judgments, then transfer human-like structure from its representations into pretrained state-of-the-art vision foundation models. These human-aligned models more accurately approximate human behavior and uncertainty across a wide range of similarity tasks, including a new dataset of human judgments spanning multiple levels of semantic abstractions. They also perform better on a diverse set of machine learning tasks, increasing generalization and out-of-distribution robustness. Thus, infusing neural networks with additional human knowledge yields a best-of-both-worlds representation that is both more consistent with human cognition and more practically useful, thus paving the way toward more robust, interpretable, and human-like artificial intelligence systems.
Read more9/17/2024
0
Dimensions underlying the representational alignment of deep neural networks with humans
Florian P. Mahner, Lukas Muttenthaler, Umut Guc{c}lu, Martin N. Hebart
Determining the similarities and differences between humans and artificial intelligence is an important goal both in machine learning and cognitive neuroscience. However, similarities in representations only inform us about the degree of alignment, not the factors that determine it. Drawing upon recent developments in cognitive science, we propose a generic framework for yielding comparable representations in humans and deep neural networks (DNN). Applying this framework to humans and a DNN model of natural images revealed a low-dimensional DNN embedding of both visual and semantic dimensions. In contrast to humans, DNNs exhibited a clear dominance of visual over semantic features, indicating divergent strategies for representing images. While in-silico experiments showed seemingly-consistent interpretability of DNN dimensions, a direct comparison between human and DNN representations revealed substantial differences in how they process images. By making representations directly comparable, our results reveal important challenges for representational alignment, offering a means for improving their comparability.
Read more6/28/2024

0
Understanding the Learning Dynamics of Alignment with Human Feedback
Shawn Im, Yixuan Li
Aligning large language models (LLMs) with human intentions has become a critical task for safely deploying models in real-world systems. While existing alignment approaches have seen empirical success, theoretically understanding how these methods affect model behavior remains an open question. Our work provides an initial attempt to theoretically analyze the learning dynamics of human preference alignment. We formally show how the distribution of preference datasets influences the rate of model updates and provide rigorous guarantees on the training accuracy. Our theory also reveals an intricate phenomenon where the optimization is prone to prioritizing certain behaviors with higher preference distinguishability. We empirically validate our findings on contemporary LLMs and alignment tasks, reinforcing our theoretical insights and shedding light on considerations for future alignment approaches. Disclaimer: This paper contains potentially offensive text; reader discretion is advised.
Read more8/9/2024