Consistent3D: Towards Consistent High-Fidelity Text-to-3D Generation with Deterministic Sampling Prior

0

Sign in to get full access
Overview
- This research paper presents a new approach called "Consistent3D" for generating high-fidelity 3D models from text descriptions.
- The key innovation is the use of a deterministic sampling prior, which helps ensure consistency across multiple 3D outputs for the same text input.
- The authors conduct experiments to evaluate the performance of Consistent3D and compare it to other state-of-the-art text-to-3D generation methods.
Plain English Explanation
The Consistent3D paper addresses an important challenge in the field of text-to-3D generation: ensuring that the 3D models produced are consistent with the text description, even when generating multiple outputs for the same input.
Typically, text-to-3D models use a sampling-based approach, which can lead to inconsistent 3D outputs for the same text input. The researchers behind Consistent3D have developed a novel technique that uses a "deterministic sampling prior" to help maintain consistency across multiple 3D generations.
The key idea is that by incorporating this deterministic prior, the model can produce 3D outputs that are more closely aligned with the text description, even when generating multiple versions. This helps ensure that the 3D models faithfully represent the intended concept and can be useful in applications like 3D content creation, virtual prototyping, and interactive experiences.
Technical Explanation
The Consistent3D model builds upon previous text-to-3D generation approaches, but with a focus on improving the consistency of the generated 3D outputs. The core innovation is the introduction of a deterministic sampling prior, which helps to constrain the generation process and ensure that multiple 3D models produced for the same text input are more closely aligned.
Traditionally, text-to-3D models have relied on stochastic sampling methods, which can lead to inconsistencies in the generated 3D outputs. To address this, the Consistent3D approach incorporates a deterministic sampling prior that is learned during the training process. This prior acts as a guiding force, helping to steer the generation towards more consistent 3D representations that better match the input text description.
The authors evaluate the performance of Consistent3D on several benchmarks, comparing it to other state-of-the-art text-to-3D generation methods. The results demonstrate that Consistent3D is able to achieve high-fidelity 3D outputs while maintaining a high degree of consistency, even when generating multiple versions for the same text input.
Critical Analysis
The Consistent3D paper presents a promising approach for addressing the consistency challenge in text-to-3D generation, but it is important to consider some potential limitations and areas for further research.
One potential concern is the reliance on the deterministic sampling prior, which may limit the overall diversity of the generated 3D models. While the prior helps to ensure consistency, it could also result in a narrower range of 3D outputs, potentially limiting the model's ability to capture the full breadth of possible interpretations of the text input.
Additionally, the authors acknowledge that the Consistent3D model is trained on a relatively limited dataset of 3D shapes and text descriptions. Expanding the training data to cover a more diverse range of 3D objects and text inputs could help to further improve the model's generalization capabilities and the quality of the generated 3D outputs.
It would also be valuable to explore the integration of Consistent3D with other text-to-3D generation techniques, such as those that incorporate additional information like image references or 3D shape priors. Combining complementary approaches could lead to even more advanced and versatile text-to-3D generation systems.
Conclusion
The Consistent3D paper presents an important advancement in the field of text-to-3D generation by addressing the challenge of ensuring consistency across multiple 3D outputs for the same text input. The introduction of a deterministic sampling prior is a key innovation that helps to improve the alignment between the generated 3D models and the text descriptions.
The experimental results demonstrate the effectiveness of the Consistent3D approach, and the potential benefits it could bring to applications like 3D content creation, virtual prototyping, and interactive experiences. While the model has some limitations, this research represents a significant step forward in the quest for high-fidelity and consistent text-to-3D generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Consistent3D: Towards Consistent High-Fidelity Text-to-3D Generation with Deterministic Sampling Prior
Zike Wu, Pan Zhou, Xuanyu Yi, Xiaoding Yuan, Hanwang Zhang
Score distillation sampling (SDS) and its variants have greatly boosted the development of text-to-3D generation, but are vulnerable to geometry collapse and poor textures yet. To solve this issue, we first deeply analyze the SDS and find that its distillation sampling process indeed corresponds to the trajectory sampling of a stochastic differential equation (SDE): SDS samples along an SDE trajectory to yield a less noisy sample which then serves as a guidance to optimize a 3D model. However, the randomness in SDE sampling often leads to a diverse and unpredictable sample which is not always less noisy, and thus is not a consistently correct guidance, explaining the vulnerability of SDS. Since for any SDE, there always exists an ordinary differential equation (ODE) whose trajectory sampling can deterministically and consistently converge to the desired target point as the SDE, we propose a novel and effective Consistent3D method that explores the ODE deterministic sampling prior for text-to-3D generation. Specifically, at each training iteration, given a rendered image by a 3D model, we first estimate its desired 3D score function by a pre-trained 2D diffusion model, and build an ODE for trajectory sampling. Next, we design a consistency distillation sampling loss which samples along the ODE trajectory to generate two adjacent samples and uses the less noisy sample to guide another more noisy one for distilling the deterministic prior into the 3D model. Experimental results show the efficacy of our Consistent3D in generating high-fidelity and diverse 3D objects and large-scale scenes, as shown in Fig. 1. The codes are available at https://github.com/sail-sg/Consistent3D.
Read more6/14/2024

0
VividDreamer: Towards High-Fidelity and Efficient Text-to-3D Generation
Zixuan Chen, Ruijie Su, Jiahao Zhu, Lingxiao Yang, Jian-Huang Lai, Xiaohua Xie
Text-to-3D generation aims to create 3D assets from text-to-image diffusion models. However, existing methods face an inherent bottleneck in generation quality because the widely-used objectives such as Score Distillation Sampling (SDS) inappropriately omit U-Net jacobians for swift generation, leading to significant bias compared to the true gradient obtained by full denoising sampling. This bias brings inconsistent updating direction, resulting in implausible 3D generation e.g., color deviation, Janus problem, and semantically inconsistent details). In this work, we propose Pose-dependent Consistency Distillation Sampling (PCDS), a novel yet efficient objective for diffusion-based 3D generation tasks. Specifically, PCDS builds the pose-dependent consistency function within diffusion trajectories, allowing to approximate true gradients through minimal sampling steps (1-3). Compared to SDS, PCDS can acquire a more accurate updating direction with the same sampling time (1 sampling step), while enabling few-step (2-3) sampling to trade compute for higher generation quality. For efficient generation, we propose a coarse-to-fine optimization strategy, which first utilizes 1-step PCDS to create the basic structure of 3D objects, and then gradually increases PCDS steps to generate fine-grained details. Extensive experiments demonstrate that our approach outperforms the state-of-the-art in generation quality and training efficiency, conspicuously alleviating the implausible 3D generation issues caused by the deviated updating direction. Moreover, it can be simply applied to many 3D generative applications to yield impressive 3D assets, please see our project page: https://narcissusex.github.io/VividDreamer.
Read more6/24/2024
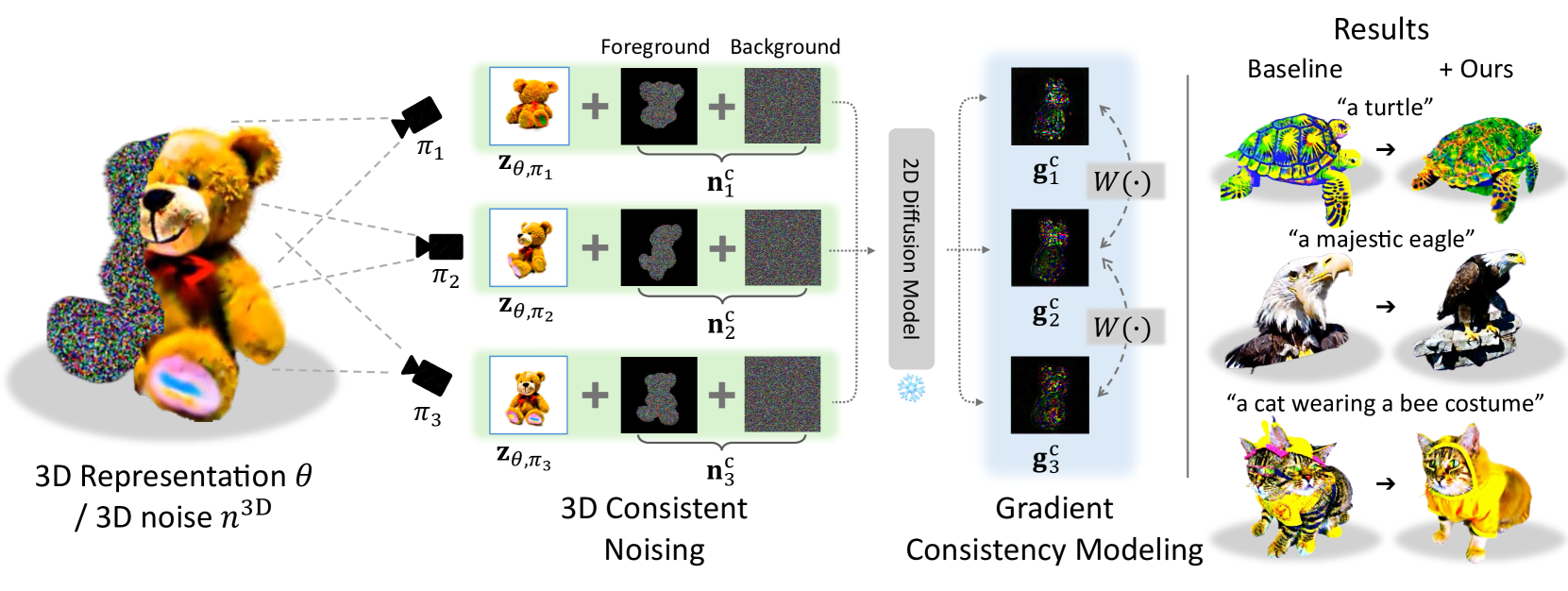
0
Geometry-Aware Score Distillation via 3D Consistent Noising and Gradient Consistency Modeling
Min-Seop Kwak, Donghoon Ahn, Ines Hyeonsu Kim, Jin-Hwa Kim, Seungryong Kim
Score distillation sampling (SDS), the methodology in which the score from pretrained 2D diffusion models is distilled into 3D representation, has recently brought significant advancements in text-to-3D generation task. However, this approach is still confronted with critical geometric inconsistency problems such as the Janus problem. Starting from a hypothesis that such inconsistency problems may be induced by multiview inconsistencies between 2D scores predicted from various viewpoints, we introduce GSD, a simple and general plug-and-play framework for incorporating 3D consistency and therefore geometry awareness into the SDS process. Our methodology is composed of three components: 3D consistent noising, designed to produce 3D consistent noise maps that perfectly follow the standard Gaussian distribution, geometry-based gradient warping for identifying correspondences between predicted gradients of different viewpoints, and novel gradient consistency loss to optimize the scene geometry toward producing more consistent gradients. We demonstrate that our method significantly improves performance, successfully addressing the geometric inconsistency problems in text-to-3D generation task with minimal computation cost and being compatible with existing score distillation-based models. Our project page is available at https://ku-cvlab.github.io/GSD/.
Read more7/2/2024

0
Connecting Consistency Distillation to Score Distillation for Text-to-3D Generation
Zongrui Li, Minghui Hu, Qian Zheng, Xudong Jiang
Although recent advancements in text-to-3D generation have significantly improved generation quality, issues like limited level of detail and low fidelity still persist, which requires further improvement. To understand the essence of those issues, we thoroughly analyze current score distillation methods by connecting theories of consistency distillation to score distillation. Based on the insights acquired through analysis, we propose an optimization framework, Guided Consistency Sampling (GCS), integrated with 3D Gaussian Splatting (3DGS) to alleviate those issues. Additionally, we have observed the persistent oversaturation in the rendered views of generated 3D assets. From experiments, we find that it is caused by unwanted accumulated brightness in 3DGS during optimization. To mitigate this issue, we introduce a Brightness-Equalized Generation (BEG) scheme in 3DGS rendering. Experimental results demonstrate that our approach generates 3D assets with more details and higher fidelity than state-of-the-art methods. The codes are released at https://github.com/LMozart/ECCV2024-GCS-BEG.
Read more7/23/2024