Constructing and Exploring Intermediate Domains in Mixed Domain Semi-supervised Medical Image Segmentation
2404.08951
0
0

Abstract
Both limited annotation and domain shift are prevalent challenges in medical image segmentation. Traditional semi-supervised segmentation and unsupervised domain adaptation methods address one of these issues separately. However, the coexistence of limited annotation and domain shift is quite common, which motivates us to introduce a novel and challenging scenario: Mixed Domain Semi-supervised medical image Segmentation (MiDSS). In this scenario, we handle data from multiple medical centers, with limited annotations available for a single domain and a large amount of unlabeled data from multiple domains. We found that the key to solving the problem lies in how to generate reliable pseudo labels for the unlabeled data in the presence of domain shift with labeled data. To tackle this issue, we employ Unified Copy-Paste (UCP) between images to construct intermediate domains, facilitating the knowledge transfer from the domain of labeled data to the domains of unlabeled data. To fully utilize the information within the intermediate domain, we propose a symmetric Guidance training strategy (SymGD), which additionally offers direct guidance to unlabeled data by merging pseudo labels from intermediate samples. Subsequently, we introduce a Training Process aware Random Amplitude MixUp (TP-RAM) to progressively incorporate style-transition components into intermediate samples. Compared with existing state-of-the-art approaches, our method achieves a notable 13.57% improvement in Dice score on Prostate dataset, as demonstrated on three public datasets. Our code is available at https://github.com/MQinghe/MiDSS .
Create account to get full access
Overview
- The paper explores a semi-supervised medical image segmentation approach that leverages intermediate domains to improve performance in a mixed-domain setting.
- It introduces a method for constructing and exploring these intermediate domains, which can help bridge the gap between source and target domains.
- The proposed approach is evaluated on several medical imaging datasets, demonstrating improved segmentation accuracy compared to other state-of-the-art methods.
Plain English Explanation
The paper focuses on a challenge in medical image segmentation, which is the task of automatically identifying and outlining different anatomical structures within medical images like X-rays or MRIs. One of the key challenges is that the appearance of these structures can vary a lot depending on the type of medical imaging technology used, the patient's condition, and other factors.
To address this, the researchers developed a new semi-supervised learning approach that can work effectively even when only a small amount of labeled training data is available. The key insight is to create "intermediate" domains that sit between the source and target domains. By learning to segment images in these intermediate domains, the model can better generalize to the target domain, even if the source and target domains are quite different.
The researchers demonstrate that this approach leads to significant improvements in segmentation accuracy compared to other state-of-the-art methods, across a range of medical imaging datasets. This suggests the technique could be very helpful for practical medical image analysis tasks, where labeled data is often scarce.
Technical Explanation
The paper proposes a mixed-domain semi-supervised medical image segmentation framework that constructs and explores intermediate domains to bridge the gap between source and target domains. The core idea is to generate these intermediate domains during training, which can help the model learn more robust and generalizable representations.
Specifically, the method involves three main steps:
- Intermediate Domain Construction: The researchers develop a domain interpolation technique to generate intermediate domains between the source and target domains. This is done by interpolating image features and corresponding segmentation labels.
- Intermediate Domain Exploration: The model is trained to perform segmentation on the intermediate domains, in addition to the source and target domains. This encourages the model to learn more generalizable features.
- Mixed-Domain Semi-Supervised Learning: The model is trained in a semi-supervised fashion, using both labeled data from the source and intermediate domains, as well as unlabeled data from the target domain.
The paper evaluates this approach on several medical imaging datasets, including MRI scans of the brain and chest X-rays. The results demonstrate that the proposed method outperforms other state-of-the-art semi-supervised and domain adaptation techniques, such as [[https://aimodels.fyi/papers/arxiv/iidm-inter-intra-domain-mixing-semi-supervised|IIDM]], [[https://aimodels.fyi/papers/arxiv/fpl-filtered-pseudo-label-based-unsupervised-cross|FPL]], and [[https://aimodels.fyi/papers/arxiv/language-guided-instance-aware-domain-adaptive-panoptic|Language-Guided Instance-Aware Domain Adaptive Panoptic Segmentation]].
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed mixed-domain semi-supervised learning approach. The authors acknowledge several limitations and avenues for future work, such as the need to further explore the optimal way to construct and leverage the intermediate domains.
One potential concern is the computational complexity of the approach, as generating and training on the intermediate domains adds additional overhead. The authors do not provide detailed runtime comparisons, so it's unclear how this approach scales compared to simpler semi-supervised or domain adaptation techniques.
Additionally, the paper focuses on relatively narrow medical imaging tasks, so further research would be needed to understand how well the approach generalizes to other computer vision problems with significant domain shifts. Exploring the use of [[https://aimodels.fyi/papers/arxiv/dg-tta-out-domain-medical-image-segmentation|out-of-domain data augmentation]] and [[https://aimodels.fyi/papers/arxiv/unimix-towards-domain-adaptive-generalizable-lidar-semantic|domain-adaptive techniques]] could also be valuable avenues for extending this work.
Overall, the paper presents an interesting and promising approach for addressing the challenges of mixed-domain, semi-supervised medical image segmentation. The key insights around intermediate domain construction and exploration are likely to be valuable for researchers working on similar problems.
Conclusion
This paper introduces a novel mixed-domain semi-supervised learning framework for medical image segmentation that constructs and explores intermediate domains to bridge the gap between source and target domains. The proposed approach demonstrates state-of-the-art performance on several medical imaging datasets, suggesting it could be a valuable tool for practical applications where labeled data is scarce.
While the method requires further exploration of its computational efficiency and generalization to other domains, the core ideas around leveraging intermediate representations are a significant contribution to the field of semi-supervised and domain-adaptive computer vision.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
IIDM: Inter and Intra-domain Mixing for Semi-supervised Domain Adaptation in Semantic Segmentation
Weifu Fu, Qiang Nie, Jialin Li, Yuhuan Lin, Kai Wu, Jian Li, Yabiao Wang, Yong Liu, Chengjie Wang
0
0
Despite recent advances in semantic segmentation, an inevitable challenge is the performance degradation caused by the domain shift in real applications. Current dominant approach to solve this problem is unsupervised domain adaptation (UDA). However, the absence of labeled target data in UDA is overly restrictive and limits performance. To overcome this limitation, a more practical scenario called semi-supervised domain adaptation (SSDA) has been proposed. Existing SSDA methods are derived from the UDA paradigm and primarily focus on leveraging the unlabeled target data and source data. In this paper, we highlight the significance of exploiting the intra-domain information between the labeled target data and unlabeled target data. Instead of solely using the scarce labeled target data for supervision, we propose a novel SSDA framework that incorporates both Inter and Intra Domain Mixing (IIDM), where inter-domain mixing mitigates the source-target domain gap and intra-domain mixing enriches the available target domain information, and the network can capture more domain-invariant features. We also explore different domain mixing strategies to better exploit the target domain information. Comprehensive experiments conducted on the GTA5 to Cityscapes and SYNTHIA to Cityscapes benchmarks demonstrate the effectiveness of IIDM, surpassing previous methods by a large margin.
4/12/2024

Rethinking Barely-Supervised Segmentation from an Unsupervised Domain Adaptation Perspective
Zhiqiang Shen, Peng Cao, Junming Su, Jinzhu Yang, Osmar R. Zaiane
0
0
This paper investigates an extremely challenging problem, barely-supervised medical image segmentation (BSS), where the training dataset comprises limited labeled data with only single-slice annotations and numerous unlabeled images. Currently, state-of-the-art (SOTA) BSS methods utilize a registration-based paradigm, depending on image registration to propagate single-slice annotations into volumetric pseudo labels for constructing a complete labeled set. However, this paradigm has a critical limitation: the pseudo labels generated by image registration are unreliable and noisy. Motivated by this, we propose a new perspective: training a model using only single-annotated slices as the labeled set without relying on image registration. To this end, we formulate BSS as an unsupervised domain adaptation (UDA) problem. Specifically, we first design a novel noise-free labeled data construction algorithm (NFC) for slice-to-volume labeled data synthesis, which may result in a side effect: domain shifts between the synthesized images and the original images. Then, a frequency and spatial mix-up strategy (FSX) is further introduced to mitigate the domain shifts for UDA. Extensive experiments demonstrate that our method provides a promising alternative for BSS. Remarkably, the proposed method with only one labeled slice achieves an 80.77% dice score on left atrial segmentation, outperforming the SOTA by 61.28%. The code will be released upon the publication of this paper.
5/17/2024
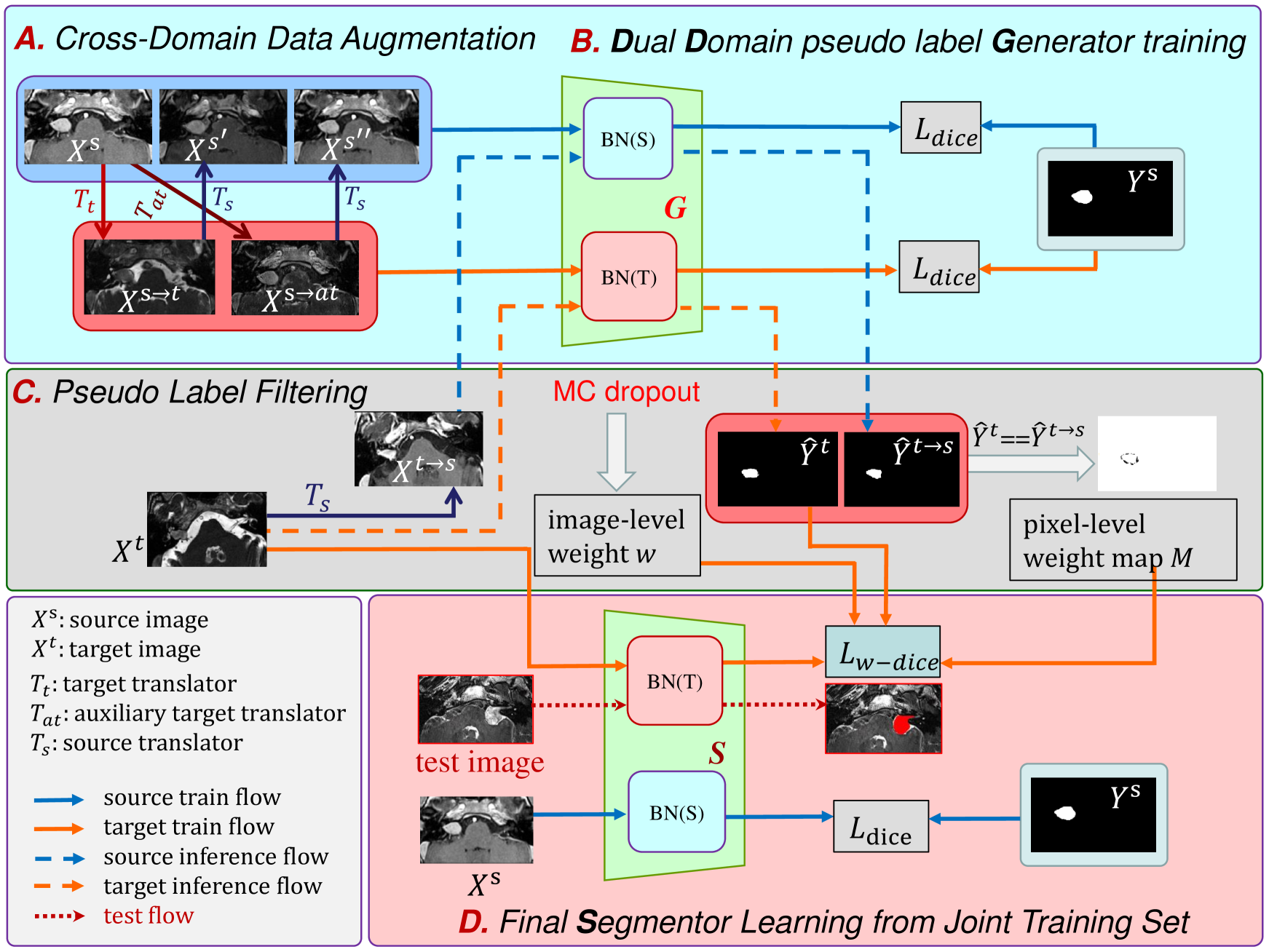
FPL+: Filtered Pseudo Label-based Unsupervised Cross-Modality Adaptation for 3D Medical Image Segmentation
Jianghao Wu, Dong Guo, Guotai Wang, Qiang Yue, Huijun Yu, Kang Li, Shaoting Zhang
0
0
Adapting a medical image segmentation model to a new domain is important for improving its cross-domain transferability, and due to the expensive annotation process, Unsupervised Domain Adaptation (UDA) is appealing where only unlabeled images are needed for the adaptation. Existing UDA methods are mainly based on image or feature alignment with adversarial training for regularization, and they are limited by insufficient supervision in the target domain. In this paper, we propose an enhanced Filtered Pseudo Label (FPL+)-based UDA method for 3D medical image segmentation. It first uses cross-domain data augmentation to translate labeled images in the source domain to a dual-domain training set consisting of a pseudo source-domain set and a pseudo target-domain set. To leverage the dual-domain augmented images to train a pseudo label generator, domain-specific batch normalization layers are used to deal with the domain shift while learning the domain-invariant structure features, generating high-quality pseudo labels for target-domain images. We then combine labeled source-domain images and target-domain images with pseudo labels to train a final segmentor, where image-level weighting based on uncertainty estimation and pixel-level weighting based on dual-domain consensus are proposed to mitigate the adverse effect of noisy pseudo labels. Experiments on three public multi-modal datasets for Vestibular Schwannoma, brain tumor and whole heart segmentation show that our method surpassed ten state-of-the-art UDA methods, and it even achieved better results than fully supervised learning in the target domain in some cases.
4/9/2024

Language-Guided Instance-Aware Domain-Adaptive Panoptic Segmentation
Elham Amin Mansour, Ozan Unal, Suman Saha, Benjamin Bejar, Luc Van Gool
0
0
The increasing relevance of panoptic segmentation is tied to the advancements in autonomous driving and AR/VR applications. However, the deployment of such models has been limited due to the expensive nature of dense data annotation, giving rise to unsupervised domain adaptation (UDA). A key challenge in panoptic UDA is reducing the domain gap between a labeled source and an unlabeled target domain while harmonizing the subtasks of semantic and instance segmentation to limit catastrophic interference. While considerable progress has been achieved, existing approaches mainly focus on the adaptation of semantic segmentation. In this work, we focus on incorporating instance-level adaptation via a novel instance-aware cross-domain mixing strategy IMix. IMix significantly enhances the panoptic quality by improving instance segmentation performance. Specifically, we propose inserting high-confidence predicted instances from the target domain onto source images, retaining the exhaustiveness of the resulting pseudo-labels while reducing the injected confirmation bias. Nevertheless, such an enhancement comes at the cost of degraded semantic performance, attributed to catastrophic forgetting. To mitigate this issue, we regularize our semantic branch by employing CLIP-based domain alignment (CDA), exploiting the domain-robustness of natural language prompts. Finally, we present an end-to-end model incorporating these two mechanisms called LIDAPS, achieving state-of-the-art results on all popular panoptic UDA benchmarks.
4/8/2024