Language-Guided Instance-Aware Domain-Adaptive Panoptic Segmentation
2404.03799
0
0

Abstract
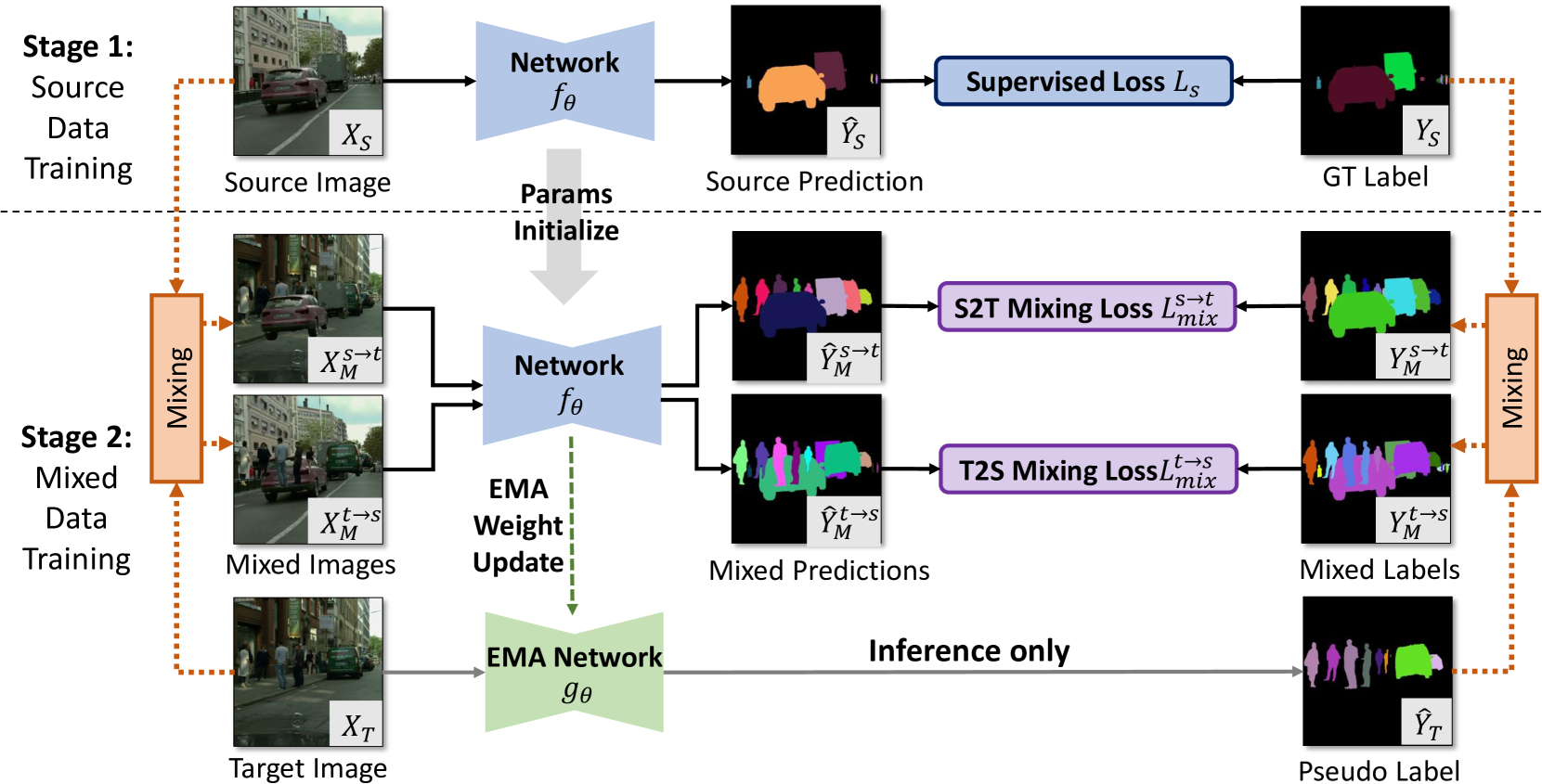
The increasing relevance of panoptic segmentation is tied to the advancements in autonomous driving and AR/VR applications. However, the deployment of such models has been limited due to the expensive nature of dense data annotation, giving rise to unsupervised domain adaptation (UDA). A key challenge in panoptic UDA is reducing the domain gap between a labeled source and an unlabeled target domain while harmonizing the subtasks of semantic and instance segmentation to limit catastrophic interference. While considerable progress has been achieved, existing approaches mainly focus on the adaptation of semantic segmentation. In this work, we focus on incorporating instance-level adaptation via a novel instance-aware cross-domain mixing strategy IMix. IMix significantly enhances the panoptic quality by improving instance segmentation performance. Specifically, we propose inserting high-confidence predicted instances from the target domain onto source images, retaining the exhaustiveness of the resulting pseudo-labels while reducing the injected confirmation bias. Nevertheless, such an enhancement comes at the cost of degraded semantic performance, attributed to catastrophic forgetting. To mitigate this issue, we regularize our semantic branch by employing CLIP-based domain alignment (CDA), exploiting the domain-robustness of natural language prompts. Finally, we present an end-to-end model incorporating these two mechanisms called LIDAPS, achieving state-of-the-art results on all popular panoptic UDA benchmarks.
Create account to get full access
Overview
- This paper proposes a novel approach for language-guided instance-aware domain-adaptive panoptic segmentation.
- The method aims to enable panoptic segmentation, which combines instance and semantic segmentation, across different domains without supervised data.
- It leverages natural language descriptions to guide the adaptation process and improve performance on instances.
Plain English Explanation
The paper introduces a system that can analyze images and identify the different objects and regions within them, even when the images come from different sources or domains. This is a challenging task because the appearance and characteristics of objects can vary a lot across different environments or datasets.
To address this, the researchers developed a language-guided approach that uses natural language descriptions to help the model adapt to new domains. The model can learn about the different objects and how to segment them, just by reading short text descriptions. This helps it perform well even when applied to images it hasn't seen before.
The key innovation is that the model not only segments the overall scene, but also identifies individual object instances within it. This "instance-aware" capability is important for many real-world applications, like autonomous driving or robotics, where you need to track and interact with specific objects.
Overall, this work advances the state-of-the-art in unsupervised domain adaptation for complex computer vision tasks like panoptic segmentation. By incorporating language guidance, the model can generalize better to new environments without needing lots of labeled training data.
Technical Explanation
The paper introduces a language-guided instance-aware domain-adaptive panoptic segmentation framework. It builds on recent progress in unsupervised domain adaptation for visual tasks, but adds novel components to address the challenges of panoptic segmentation.
The core architecture consists of a shared encoder module that processes both the input image and the associated language description. This allows the model to learn features that are aligned between the visual and textual domains. Separate decoders then produce the instance segmentation and semantic segmentation outputs.
To enable effective domain adaptation, the authors propose several novel techniques. This includes discriminative sample guidance to selectively adapt parameters based on informative instances, and language-conditioned instance embeddings to better capture the semantic and geometric properties of objects.
Extensive experiments on benchmark datasets demonstrate the effectiveness of this approach. The language guidance boosts performance compared to prior unsupervised domain adaptation methods, particularly for accurately segmenting individual object instances.
Critical Analysis
The paper makes a strong contribution to the field of unsupervised domain adaptation for complex computer vision tasks. Incorporating language descriptions is a clever way to leverage additional supervision signals and improve cross-domain generalization.
However, the authors acknowledge some limitations. The language model used is relatively simple, and more advanced techniques for grounding language in visual features could potentially yield further gains. Additionally, the experiments are conducted on relatively constrained datasets, and evaluating on more diverse, real-world scenarios would be valuable.
More broadly, the reliance on language descriptions raises questions about the scalability and accessibility of the approach. Obtaining high-quality text annotations may be challenging in many practical settings. Exploring ways to learn from weaker or automatically generated language signals could help address this.
Overall, this paper presents an innovative and promising direction for language-guided domain-adaptive computer vision. By combining powerful learning-based techniques with language-based priors, it demonstrates the potential to tackle challenging visual understanding tasks in a more flexible and generalizable way.
Conclusion
This paper introduces a novel language-guided instance-aware domain-adaptive panoptic segmentation framework. It leverages natural language descriptions to guide the adaptation process and improve performance on individual object instances, addressing a key limitation of prior unsupervised domain adaptation methods.
The technical contributions, including discriminative sample guidance and language-conditioned instance embeddings, demonstrate the value of incorporating language-based supervision for complex computer vision tasks. While there are some limitations to address, this work represents an important step towards building more robust and generalizable visual understanding systems.
As AI systems become more widely deployed in real-world applications, the ability to adapt to diverse environments and data sources will be increasingly crucial. This research points to the potential of using language as a powerful inductive bias to enable such cross-domain generalization, with broad implications for the future of computer vision and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Synth-to-Real Unsupervised Domain Adaptation for Instance Segmentation
Yachan Guo, Yi Xiao, Danna Xue, Jose Luis Gomez Zurita, Antonio M. L'opez
0
0
Unsupervised Domain Adaptation (UDA) aims to transfer knowledge learned from a labeled source domain to an unlabeled target domain. While UDA methods for synthetic to real-world domains (synth-to-real) show remarkable performance in tasks such as semantic segmentation and object detection, very few were proposed for the instance segmentation task. In this paper, we introduce UDA4Inst, a model of synth-to-real UDA for instance segmentation in autonomous driving. We propose a novel cross-domain bidirectional data mixing method at the instance level to fully leverage the data from both source and target domains. Rare-class balancing and category module training are also employed to further improve the performance. It is worth noting that we are the first to demonstrate results on two new synth-to-real instance segmentation benchmarks, with 39.0 mAP on UrbanSyn->Cityscapes and 35.7 mAP on Synscapes->Cityscapes. UDA4Inst also achieves the state-of-the-art result on SYNTHIA->Cityscapes with 31.3 mAP, +15.6 higher than the latest approach. Our code will be released.
5/24/2024
💬
IIDM: Inter and Intra-domain Mixing for Semi-supervised Domain Adaptation in Semantic Segmentation
Weifu Fu, Qiang Nie, Jialin Li, Yuhuan Lin, Kai Wu, Jian Li, Yabiao Wang, Yong Liu, Chengjie Wang
0
0
Despite recent advances in semantic segmentation, an inevitable challenge is the performance degradation caused by the domain shift in real applications. Current dominant approach to solve this problem is unsupervised domain adaptation (UDA). However, the absence of labeled target data in UDA is overly restrictive and limits performance. To overcome this limitation, a more practical scenario called semi-supervised domain adaptation (SSDA) has been proposed. Existing SSDA methods are derived from the UDA paradigm and primarily focus on leveraging the unlabeled target data and source data. In this paper, we highlight the significance of exploiting the intra-domain information between the labeled target data and unlabeled target data. Instead of solely using the scarce labeled target data for supervision, we propose a novel SSDA framework that incorporates both Inter and Intra Domain Mixing (IIDM), where inter-domain mixing mitigates the source-target domain gap and intra-domain mixing enriches the available target domain information, and the network can capture more domain-invariant features. We also explore different domain mixing strategies to better exploit the target domain information. Comprehensive experiments conducted on the GTA5 to Cityscapes and SYNTHIA to Cityscapes benchmarks demonstrate the effectiveness of IIDM, surpassing previous methods by a large margin.
4/12/2024
Style Adaptation for Domain-adaptive Semantic Segmentation
Ting Li, Jianshu Chao, Deyu An
0
0
Unsupervised Domain Adaptation (UDA) refers to the method that utilizes annotated source domain data and unlabeled target domain data to train a model capable of generalizing to the target domain data. Domain discrepancy leads to a significant decrease in the performance of general network models trained on the source domain data when applied to the target domain. We introduce a straightforward approach to mitigate the domain discrepancy, which necessitates no additional parameter calculations and seamlessly integrates with self-training-based UDA methods. Through the transfer of the target domain style to the source domain in the latent feature space, the model is trained to prioritize the target domain style during the decision-making process. We tackle the problem at both the image-level and shallow feature map level by transferring the style information from the target domain to the source domain data. As a result, we obtain a model that exhibits superior performance on the target domain. Our method yields remarkable enhancements in the state-of-the-art performance for synthetic-to-real UDA tasks. For example, our proposed method attains a noteworthy UDA performance of 76.93 mIoU on the GTA->Cityscapes dataset, representing a notable improvement of +1.03 percentage points over the previous state-of-the-art results.
4/26/2024
🤷
SALUDA: Surface-based Automotive Lidar Unsupervised Domain Adaptation
Bjorn Michele, Alexandre Boulch, Gilles Puy, Tuan-Hung Vu, Renaud Marlet, Nicolas Courty
0
0
Learning models on one labeled dataset that generalize well on another domain is a difficult task, as several shifts might happen between the data domains. This is notably the case for lidar data, for which models can exhibit large performance discrepancies due for instance to different lidar patterns or changes in acquisition conditions. This paper addresses the corresponding Unsupervised Domain Adaptation (UDA) task for semantic segmentation. To mitigate this problem, we introduce an unsupervised auxiliary task of learning an implicit underlying surface representation simultaneously on source and target data. As both domains share the same latent representation, the model is forced to accommodate discrepancies between the two sources of data. This novel strategy differs from classical minimization of statistical divergences or lidar-specific domain adaptation techniques. Our experiments demonstrate that our method achieves a better performance than the current state of the art, both in real-to-real and synthetic-to-real scenarios.
6/27/2024