In-Context Learning Demonstration Selection via Influence Analysis
2402.11750
0
0
🌿
Abstract
Large Language Models (LLMs) have showcased their In-Context Learning (ICL) capabilities, enabling few-shot learning without the need for gradient updates. Despite its advantages, the effectiveness of ICL heavily depends on the choice of demonstrations. Selecting the most effective demonstrations for ICL remains a significant research challenge. To tackle this issue, we propose a demonstration selection method named InfICL, which utilizes influence functions to analyze impacts of training samples. By identifying the most influential training samples as demonstrations, InfICL aims to enhance the ICL generalization performance. To keep InfICL cost-effective, we only use the LLM to generate sample input embeddings, avoiding expensive fine-tuning. Through empirical studies on various real-world datasets, we demonstrate advantages of InfICL compared to state-of-the-art baselines.
Create account to get full access
Overview
- Large language models (LLMs) have demonstrated impressive in-context learning (ICL) capabilities, allowing them to learn new tasks with just a few examples.
- However, the effectiveness of ICL heavily depends on the choice of demonstration examples.
- Selecting the most effective demonstrations for ICL remains a significant research challenge.
Plain English Explanation
Large language models (LLMs) have shown that they can learn new tasks quickly by using just a few example inputs and outputs, a technique called in-context learning (ICL). This is a powerful capability, as it means LLMs can adapt to new situations without requiring extensive retraining.
However, the success of ICL depends a lot on which example inputs and outputs are provided to the model. Choosing the most effective demonstrations for ICL is an important challenge that researchers are still working to solve.
To address this, the researchers propose a new method called InfICL that uses influence functions to analyze which training samples have the biggest impact on the model's performance. By selecting the most influential training samples as the demonstration examples, InfICL aims to improve the generalization ability of the model's ICL.
Importantly, InfICL is designed to be cost-effective - it only uses the LLM to generate sample input embeddings, avoiding the need for expensive model fine-tuning. Through testing on real-world datasets, the researchers show that InfICL outperforms other state-of-the-art approaches for demonstration selection.
Technical Explanation
The paper introduces a novel demonstration selection method called InfICL that utilizes influence functions to analyze the impact of training samples and identify the most influential ones as demonstrations for in-context learning (ICL).
The key idea behind InfICL is to leverage influence functions to quantify how much each training sample contributes to the model's performance on a given task. By selecting the most influential training samples as demonstrations, InfICL aims to enhance the generalization capability of the model's ICL.
To keep InfICL cost-effective, the method only uses the LLM to generate sample input embeddings, avoiding the need for expensive fine-tuning. This makes InfICL practical to apply to large-scale LLMs.
Through extensive empirical studies on various real-world datasets, the researchers demonstrate that InfICL outperforms state-of-the-art baselines for demonstration selection in ICL tasks. The results highlight the advantages of their influence-based approach for identifying the most informative demonstration examples.
Critical Analysis
The paper presents a well-designed and thorough investigation of using influence functions to select demonstration examples for in-context learning. The authors acknowledge the limitations of their approach, noting that the computational cost of calculating influence functions may still be prohibitive for extremely large LLMs.
Additionally, the paper does not explore the potential biases or fairness implications of using influence functions to select demonstrations. There may be cases where the most "influential" examples reinforce existing societal biases present in the training data.
Further research could investigate ways to mitigate these concerns, such as incorporating fairness constraints or diversifying the selected demonstrations. The authors could also explore the generalization of InfICL to other context-aware learning paradigms beyond just ICL.
Overall, the paper makes a valuable contribution by introducing a novel, principled approach to the important problem of demonstration selection for in-context learning. The results demonstrate the promise of influence-based methods, while also highlighting areas for continued research and refinement.
Conclusion
The paper presents a new demonstration selection method called InfICL that leverages influence functions to identify the most impactful training samples for enhancing in-context learning (ICL) performance. By focusing on the most influential examples, InfICL aims to improve the generalization capability of LLMs when adapting to new tasks with just a few demonstrations.
The key innovation of InfICL is its cost-effective design, which avoids the need for expensive fine-tuning by only using the LLM to generate input embeddings. Empirical results on real-world datasets show that InfICL outperforms other state-of-the-art approaches for demonstration selection, highlighting the potential of influence-based methods for improving ICL.
This research represents an important step forward in addressing the critical challenge of selecting effective demonstrations for in-context learning, a capability that is crucial for making LLMs more adaptable and useful in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⛏️
In-Context Learning with Iterative Demonstration Selection
Chengwei Qin, Aston Zhang, Chen Chen, Anirudh Dagar, Wenming Ye
0
0
Spurred by advancements in scale, large language models (LLMs) have demonstrated strong few-shot learning ability via in-context learning (ICL). However, the performance of ICL has been shown to be highly sensitive to the selection of few-shot demonstrations. Selecting the most suitable examples as context remains an ongoing challenge and an open problem. Existing literature has highlighted the importance of selecting examples that are diverse or semantically similar to the test sample while ignoring the fact that the optimal selection dimension, i.e., diversity or similarity, is task-specific. Based on how the test sample is answered, we propose Iterative Demonstration Selection (IDS) to leverage the merits of both dimensions. Using zero-shot chain-of-thought reasoning (Zero-shot-CoT), IDS iteratively selects examples that are diverse but still strongly correlated with the test sample as ICL demonstrations. Specifically, IDS applies Zero-shot-CoT to the test sample before demonstration selection. The output reasoning path is then used to choose demonstrations that are prepended to the test sample for inference. The generated answer is followed by its corresponding reasoning path for extracting a new set of demonstrations in the next iteration. After several iterations, IDS adopts majority voting to obtain the final result. Through extensive experiments on tasks including reasoning, question answering, and topic classification, we demonstrate that IDS can consistently outperform existing ICL demonstration selection methods.
6/26/2024
Unifying Demonstration Selection and Compression for In-Context Learning
Jun Gao, Ziqiang Cao, Wenjie Li
0
0
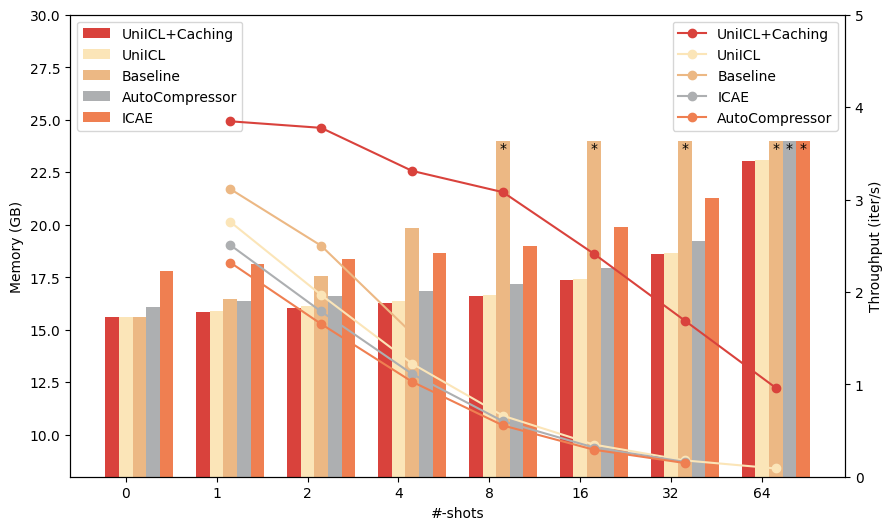
In-context learning (ICL) facilitates large language models (LLMs) exhibiting spectacular emergent capabilities in various scenarios. Unfortunately, introducing demonstrations easily makes the prompt length explode, bringing a significant burden to hardware. In addition, random demonstrations usually achieve limited improvements in ICL, necessitating demonstration selection among accessible candidates. Previous studies introduce extra modules to perform demonstration compression or selection independently. In this paper, we propose an ICL framework UniICL, which Unifies demonstration selection and compression, and final response generation via a single frozen LLM. Specifically, UniICL first projects actual demonstrations and inference text inputs into short virtual tokens, respectively. Then, virtual tokens are applied to select suitable demonstrations by measuring semantic similarity within latent space among candidate demonstrations and inference input. Finally, inference text inputs together with selected virtual demonstrations are fed into the same frozen LLM for response generation. Notably, UniICL is a parameter-efficient framework that only contains 17M trainable parameters originating from the projection layer. We conduct experiments and analysis over in- and out-domain datasets of both generative and understanding tasks, encompassing ICL scenarios with plentiful and limited demonstration candidates. Results show that UniICL effectively unifies $12 times$ compression, demonstration selection, and response generation, efficiently scaling up the baseline from 4-shot to 64-shot ICL in IMDb with 24 GB CUDA allocation
6/18/2024
✅
Unraveling the Mechanics of Learning-Based Demonstration Selection for In-Context Learning
Hui Liu, Wenya Wang, Hao Sun, Chris Xing Tian, Chenqi Kong, Xin Dong, Haoliang Li
0
0
Large Language Models (LLMs) have demonstrated impressive in-context learning (ICL) capabilities from few-shot demonstration exemplars. While recent learning-based demonstration selection methods have proven beneficial to ICL by choosing more useful exemplars, their underlying mechanisms are opaque, hindering efforts to address limitations such as high training costs and poor generalization across tasks. These methods generally assume the selection process captures similarities between the exemplar and the target instance, however, it remains unknown what kinds of similarities are captured and vital to performing ICL. To dive into this question, we analyze the working mechanisms of the learning-based demonstration selection methods and empirically identify two important factors related to similarity measurement: 1) The ability to integrate different levels of task-agnostic text similarities between the input of exemplars and test cases enhances generalization power across different tasks. 2) Incorporating task-specific labels when measuring the similarities significantly improves the performance on each specific task. We validate these two findings through extensive quantitative and qualitative analyses across ten datasets and various LLMs. Based on our findings, we introduce two effective yet simplified exemplar selection methods catering to task-agnostic and task-specific demands, eliminating the costly LLM inference overhead.
6/19/2024
🌿
Let's Learn Step by Step: Enhancing In-Context Learning Ability with Curriculum Learning
Yinpeng Liu, Jiawei Liu, Xiang Shi, Qikai Cheng, Yong Huang, Wei Lu
0
0
Demonstration ordering, which is an important strategy for in-context learning (ICL), can significantly affects the performance of large language models (LLMs). However, most of the current approaches of ordering require high computational costs to introduce the priori knowledge. In this paper, inspired by the human learning process, we propose a simple but effective demonstration ordering method for ICL, named the few-shot In-Context Curriculum Learning (ICCL). The ICCL implies gradually increasing the complexity of prompt demonstrations during the inference process. The difficulty can be assessed by human experts or LLMs-driven metrics, such as perplexity. Then we design extensive experiments to discuss the effectiveness of the ICCL at both corpus-level and instance-level. Moreover, we also investigate the formation mechanism of LLM's ICCL capability. Experimental results demonstrate that ICCL, developed during the instruction-tuning stage, is effective for representative open-source LLMs. To facilitate further research and applications by other scholars, we make the code publicly available.
6/18/2024