Unifying Demonstration Selection and Compression for In-Context Learning
2405.17062
0
0
Abstract
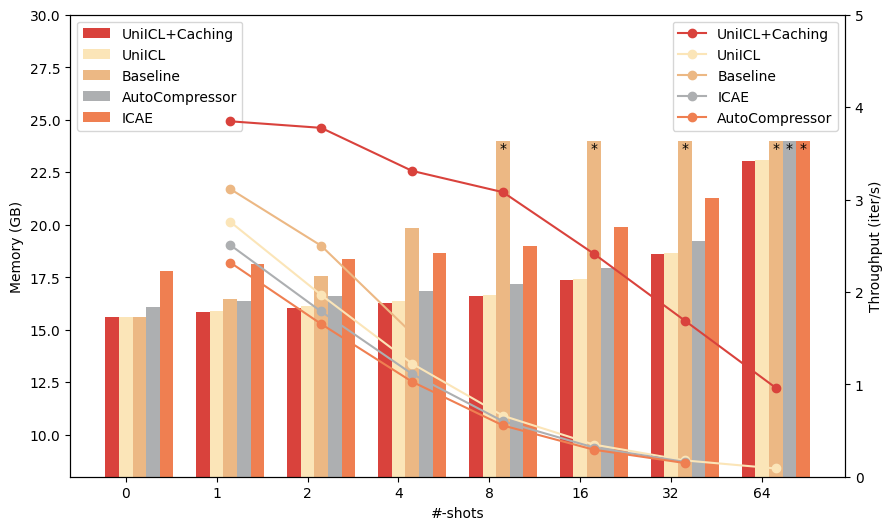
In-context learning (ICL) facilitates large language models (LLMs) exhibiting spectacular emergent capabilities in various scenarios. Unfortunately, introducing demonstrations easily makes the prompt length explode, bringing a significant burden to hardware. In addition, random demonstrations usually achieve limited improvements in ICL, necessitating demonstration selection among accessible candidates. Previous studies introduce extra modules to perform demonstration compression or selection independently. In this paper, we propose an ICL framework UniICL, which Unifies demonstration selection and compression, and final response generation via a single frozen LLM. Specifically, UniICL first projects actual demonstrations and inference text inputs into short virtual tokens, respectively. Then, virtual tokens are applied to select suitable demonstrations by measuring semantic similarity within latent space among candidate demonstrations and inference input. Finally, inference text inputs together with selected virtual demonstrations are fed into the same frozen LLM for response generation. Notably, UniICL is a parameter-efficient framework that only contains 17M trainable parameters originating from the projection layer. We conduct experiments and analysis over in- and out-domain datasets of both generative and understanding tasks, encompassing ICL scenarios with plentiful and limited demonstration candidates. Results show that UniICL effectively unifies $12 times$ compression, demonstration selection, and response generation, efficiently scaling up the baseline from 4-shot to 64-shot ICL in IMDb with 24 GB CUDA allocation
Create account to get full access
Overview
- This paper presents a novel approach to unify demonstration selection and compression for in-context learning, a technique where language models leverage relevant examples to improve their performance on a given task.
- The proposed method aims to efficiently identify and condense the most informative demonstrations, leading to improved model performance while reducing the required training data.
- The authors demonstrate the effectiveness of their approach through experiments on various language tasks, showcasing its advantages over existing techniques.
Plain English Explanation
In-context learning is a powerful technique used by language models, where the model can leverage relevant examples or "demonstrations" to improve its performance on a specific task. However, selecting and compressing these demonstrations effectively is a challenging problem.
This paper introduces a new approach that addresses both the selection and compression of demonstrations in a unified manner. The key idea is to identify the most informative demonstrations and then condense them into a more compact format, without sacrificing their usefulness for the model.
By doing so, the model can achieve better performance while requiring less training data, which is particularly important when working with large language models that can be computationally expensive to train. The authors validate their approach through experiments on various language tasks, demonstrating its advantages over existing techniques.
Technical Explanation
The paper proposes a novel framework that jointly optimizes the selection and compression of demonstrations for in-context learning. The authors introduce a <a href="https://aimodels.fyi/papers/arxiv/implicit-context-learning">demonstration selection module</a> that learns to identify the most informative examples from a pool of available demonstrations. This is coupled with a <a href="https://aimodels.fyi/papers/arxiv/decomposing-label-space-format-discrimination-rethinking-how">demonstration compression module</a> that compresses the selected demonstrations into a more compact format, preserving their essential information.
The demonstration selection module is trained using a contrastive objective, where the model learns to distinguish between "positive" (informative) and "negative" (uninformative) demonstrations. The compressed demonstrations are then used as input to the language model, along with the target task input, to facilitate in-context learning.
The authors evaluate their approach on several language tasks, including text summarization, question answering, and natural language inference. Their results show that the unified framework consistently outperforms existing methods for demonstration selection and compression, leading to improved model performance while requiring fewer training examples.
Additionally, the authors analyze the behavior of their approach using <a href="https://aimodels.fyi/papers/arxiv/hint-enhanced-context-learning-wakes-large-language">saliency maps</a> and <a href="https://aimodels.fyi/papers/arxiv/take-one-step-at-time-to-know">probing experiments</a>, providing insights into how the model learns to identify and utilize the most relevant demonstrations.
Critical Analysis
The paper presents a well-designed and thorough approach to the challenge of demonstration selection and compression for in-context learning. The authors have thoughtfully addressed key aspects, such as the contrastive training of the demonstration selection module and the compression of the selected demonstrations.
One potential limitation is the reliance on a pre-defined pool of demonstrations, which may not always be available in real-world scenarios. The authors acknowledge this and suggest exploring <a href="https://aimodels.fyi/papers/arxiv/towards-understanding-context-learning-contrastive-demonstrations-saliency">techniques for generating demonstrations on-the-fly</a> as an area for future research.
Additionally, the authors focus on language tasks, and it would be interesting to see how their approach can be extended to other domains, such as vision or multi-modal tasks. Exploring the generalizability of the unified framework could further strengthen its impact.
Overall, this paper makes a valuable contribution to the field of in-context learning by presenting a novel and effective solution to the demonstration selection and compression problem. The technical insights and experimental results provide a strong foundation for further advancements in this area.
Conclusion
This paper introduces a unified framework for demonstration selection and compression in the context of in-context learning. By jointly optimizing these two crucial aspects, the proposed approach can significantly improve model performance while reducing the required training data.
The authors' innovative methods, combined with their thorough evaluation and analysis, demonstrate the practical benefits and insights of their work. As language models continue to play a pivotal role in various applications, this research represents an important step towards more efficient and effective in-context learning.
The findings presented in this paper have the potential to drive further advancements in the field, as researchers and practitioners explore ways to enhance the adaptive capabilities of language models and optimize the use of available training resources.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
In-Context Learning Demonstration Selection via Influence Analysis
Vinay M. S., Minh-Hao Van, Xintao Wu
0
0
Large Language Models (LLMs) have showcased their In-Context Learning (ICL) capabilities, enabling few-shot learning without the need for gradient updates. Despite its advantages, the effectiveness of ICL heavily depends on the choice of demonstrations. Selecting the most effective demonstrations for ICL remains a significant research challenge. To tackle this issue, we propose a demonstration selection method named InfICL, which utilizes influence functions to analyze impacts of training samples. By identifying the most influential training samples as demonstrations, InfICL aims to enhance the ICL generalization performance. To keep InfICL cost-effective, we only use the LLM to generate sample input embeddings, avoiding expensive fine-tuning. Through empirical studies on various real-world datasets, we demonstrate advantages of InfICL compared to state-of-the-art baselines.
6/19/2024
⛏️
In-Context Learning with Iterative Demonstration Selection
Chengwei Qin, Aston Zhang, Chen Chen, Anirudh Dagar, Wenming Ye
0
0
Spurred by advancements in scale, large language models (LLMs) have demonstrated strong few-shot learning ability via in-context learning (ICL). However, the performance of ICL has been shown to be highly sensitive to the selection of few-shot demonstrations. Selecting the most suitable examples as context remains an ongoing challenge and an open problem. Existing literature has highlighted the importance of selecting examples that are diverse or semantically similar to the test sample while ignoring the fact that the optimal selection dimension, i.e., diversity or similarity, is task-specific. Based on how the test sample is answered, we propose Iterative Demonstration Selection (IDS) to leverage the merits of both dimensions. Using zero-shot chain-of-thought reasoning (Zero-shot-CoT), IDS iteratively selects examples that are diverse but still strongly correlated with the test sample as ICL demonstrations. Specifically, IDS applies Zero-shot-CoT to the test sample before demonstration selection. The output reasoning path is then used to choose demonstrations that are prepended to the test sample for inference. The generated answer is followed by its corresponding reasoning path for extracting a new set of demonstrations in the next iteration. After several iterations, IDS adopts majority voting to obtain the final result. Through extensive experiments on tasks including reasoning, question answering, and topic classification, we demonstrate that IDS can consistently outperform existing ICL demonstration selection methods.
6/26/2024
🚀
Revisiting Demonstration Selection Strategies in In-Context Learning
Keqin Peng, Liang Ding, Yancheng Yuan, Xuebo Liu, Min Zhang, Yuanxin Ouyang, Dacheng Tao
0
0
Large language models (LLMs) have shown an impressive ability to perform a wide range of tasks using in-context learning (ICL), where a few examples are used to describe a task to the model. However, the performance of ICL varies significantly with the choice of demonstrations, and it is still unclear why this happens or what factors will influence its choice. In this work, we first revisit the factors contributing to this variance from both data and model aspects, and find that the choice of demonstration is both data- and model-dependent. We further proposed a data- and model-dependent demonstration selection method, textbf{TopK + ConE}, based on the assumption that textit{the performance of a demonstration positively correlates with its contribution to the model's understanding of the test samples}, resulting in a simple and effective recipe for ICL. Empirically, our method yields consistent improvements in both language understanding and generation tasks with different model scales. Further analyses confirm that, besides the generality and stability under different circumstances, our method provides a unified explanation for the effectiveness of previous methods. Code will be released.
6/26/2024
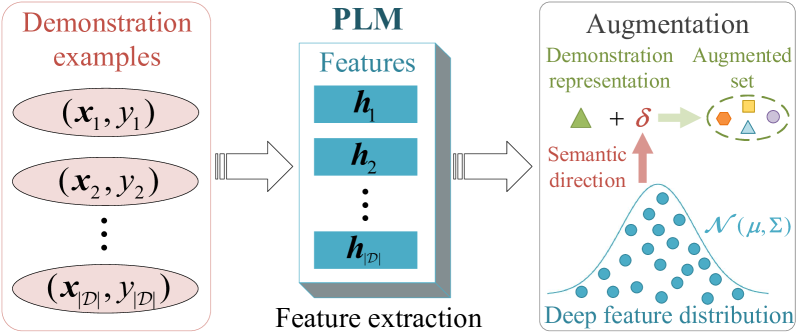
New!Enhancing In-Context Learning via Implicit Demonstration Augmentation
Xiaoling Zhou, Wei Ye, Yidong Wang, Chaoya Jiang, Zhemg Lee, Rui Xie, Shikun Zhang
0
0
The emergence of in-context learning (ICL) enables large pre-trained language models (PLMs) to make predictions for unseen inputs without updating parameters. Despite its potential, ICL's effectiveness heavily relies on the quality, quantity, and permutation of demonstrations, commonly leading to suboptimal and unstable performance. In this paper, we tackle this challenge for the first time from the perspective of demonstration augmentation. Specifically, we start with enriching representations of demonstrations by leveraging their deep feature distribution. We then theoretically reveal that when the number of augmented copies approaches infinity, the augmentation is approximately equal to a novel logit calibration mechanism integrated with specific statistical properties. This insight results in a simple yet highly efficient method that significantly improves the average and worst-case accuracy across diverse PLMs and tasks. Moreover, our method effectively reduces performance variance among varying demonstrations, permutations, and templates, and displays the capability to address imbalanced class distributions.
7/2/2024