A Continual and Incremental Learning Approach for TinyML On-device Training Using Dataset Distillation and Model Size Adaption

0
Sign in to get full access
Overview
- Examines a continual and incremental learning approach for training tiny machine learning (TinyML) models on-device
- Leverages dataset distillation and model size adaptation to enable efficient training with limited device resources
- Focuses on enabling on-device training for edge AI applications with tight memory and computational constraints
Plain English Explanation
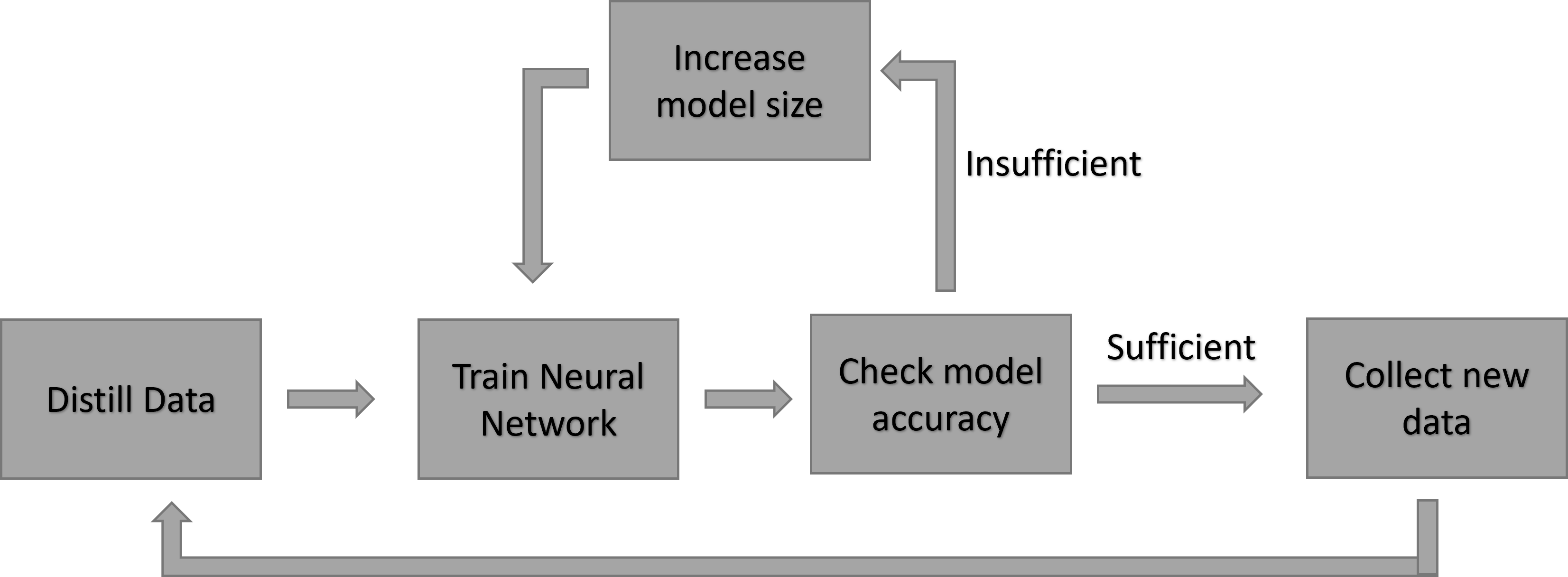
This research paper introduces a new approach for training tiny machine learning (TinyML) models directly on edge devices, such as smartphones or IoT sensors. The key challenge is that these devices have very limited memory and processing power, making it difficult to train complex models.
The researchers propose a technique called dataset distillation that can compress large training datasets into a smaller set of "distilled" samples. This allows the model to be trained on-device using the compressed dataset, rather than the full original dataset which would be too large to fit in the device's memory.
Additionally, the researchers developed a model size adaptation approach that can dynamically adjust the size of the neural network model to fit within the tight memory constraints of the edge device. This allows the model to be trained and run efficiently on-device.
The combination of dataset distillation and model size adaptation enables a continual and incremental learning approach, where the model can be updated and fine-tuned over time directly on the edge device. This is important for applications like personalized recommendations or activity recognition, where the model needs to adapt to the user's changing preferences or behavior.
Technical Explanation
The paper proposes a novel approach for enabling on-device training of TinyML models, which is critical for edge AI applications with tight resource constraints.
The key components of the approach are:
-
Dataset Distillation: The researchers developed a dataset distillation technique that can compress large training datasets into a smaller set of "distilled" samples. This allows the model to be trained on-device using the compressed dataset, rather than the full original dataset which would be too large to fit in the device's memory.
-
Model Size Adaptation: The researchers also introduced a model size adaptation approach that can dynamically adjust the size of the neural network model to fit within the tight memory constraints of the edge device. This allows the model to be trained and run efficiently on-device.
-
Continual and Incremental Learning: By combining dataset distillation and model size adaptation, the researchers enabled a continual and incremental learning approach, where the model can be updated and fine-tuned over time directly on the edge device. This is crucial for applications like personalized recommendations or activity recognition, where the model needs to adapt to the user's changing preferences or behavior.
The researchers conducted extensive experiments to evaluate their approach, demonstrating its effectiveness in training TinyML models on-device with limited resources. They showed that their method can achieve comparable accuracy to traditional training approaches while significantly reducing the memory and computational requirements.
Critical Analysis
The researchers acknowledge several limitations and areas for further research in their work:
-
Generalization: While the approach shows promise for on-device training, the researchers note that further research is needed to understand how well the distilled datasets and adapted models generalize to new tasks and environments.
-
Scalability: The paper focuses on a single-task learning scenario, and the researchers highlight the need to extend the approach to handle more complex, multi-task learning scenarios on edge devices.
-
Interpretability: The paper does not address the interpretability of the trained models, which is an important consideration for many real-world applications of TinyML systems.
-
Hardware Constraints: The experiments in the paper were conducted on simulated edge device environments. Further research is needed to validate the approach on actual hardware platforms with diverse resource constraints.
Overall, the researchers have made a significant contribution to the field of on-device training for TinyML systems. However, as with any research, there are still opportunities for further improvements and extensions to address the identified limitations and expand the applicability of the approach.
Conclusion
This research paper presents a novel continual and incremental learning approach for training TinyML models directly on edge devices. By leveraging dataset distillation and model size adaptation, the proposed method enables efficient on-device training despite the tight memory and computational constraints of these edge devices.
The ability to train and update models on-device is crucial for a wide range of edge AI applications, such as personalized recommendations, activity recognition, and sensor-based analytics. The researchers' work represents an important step forward in making TinyML a practical reality, empowering devices at the edge to adapt and learn autonomously.
While the paper identifies several areas for further research, the core ideas and techniques introduced here have the potential to significantly advance the field of on-device learning for resource-constrained embedded systems. As the demand for intelligent, personalized, and adaptive edge devices continues to grow, this research offers a promising path forward for enabling truly intelligent and self-learning TinyML systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Continual and Incremental Learning Approach for TinyML On-device Training Using Dataset Distillation and Model Size Adaption
Marcus Rub, Philipp Tuchel, Axel Sikora, Daniel Mueller-Gritschneder
A new algorithm for incremental learning in the context of Tiny Machine learning (TinyML) is presented, which is optimized for low-performance and energy efficient embedded devices. TinyML is an emerging field that deploys machine learning models on resource-constrained devices such as microcontrollers, enabling intelligent applications like voice recognition, anomaly detection, predictive maintenance, and sensor data processing in environments where traditional machine learning models are not feasible. The algorithm solve the challenge of catastrophic forgetting through the use of knowledge distillation to create a small, distilled dataset. The novelty of the method is that the size of the model can be adjusted dynamically, so that the complexity of the model can be adapted to the requirements of the task. This offers a solution for incremental learning in resource-constrained environments, where both model size and computational efficiency are critical factors. Results show that the proposed algorithm offers a promising approach for TinyML incremental learning on embedded devices. The algorithm was tested on five datasets including: CIFAR10, MNIST, CORE50, HAR, Speech Commands. The findings indicated that, despite using only 43% of Floating Point Operations (FLOPs) compared to a larger fixed model, the algorithm experienced a negligible accuracy loss of just 1%. In addition, the presented method is memory efficient. While state-of-the-art incremental learning is usually very memory intensive, the method requires only 1% of the original data set.
Read more9/12/2024
🤷
0
On-device Online Learning and Semantic Management of TinyML Systems
Haoyu Ren, Xue Li, Darko Anicic, Thomas A. Runkler
Recent advances in Tiny Machine Learning (TinyML) empower low-footprint embedded devices for real-time on-device Machine Learning. While many acknowledge the potential benefits of TinyML, its practical implementation presents unique challenges. This study aims to bridge the gap between prototyping single TinyML models and developing reliable TinyML systems in production: (1) Embedded devices operate in dynamically changing conditions. Existing TinyML solutions primarily focus on inference, with models trained offline on powerful machines and deployed as static objects. However, static models may underperform in the real world due to evolving input data distributions. We propose online learning to enable training on constrained devices, adapting local models towards the latest field conditions. (2) Nevertheless, current on-device learning methods struggle with heterogeneous deployment conditions and the scarcity of labeled data when applied across numerous devices. We introduce federated meta-learning incorporating online learning to enhance model generalization, facilitating rapid learning. This approach ensures optimal performance among distributed devices by knowledge sharing. (3) Moreover, TinyML's pivotal advantage is widespread adoption. Embedded devices and TinyML models prioritize extreme efficiency, leading to diverse characteristics ranging from memory and sensors to model architectures. Given their diversity and non-standardized representations, managing these resources becomes challenging as TinyML systems scale up. We present semantic management for the joint management of models and devices at scale. We demonstrate our methods through a basic regression example and then assess them in three real-world TinyML applications: handwritten character image classification, keyword audio classification, and smart building presence detection, confirming our approaches' effectiveness.
Read more5/17/2024
🏋️
0
TinyTrain: Resource-Aware Task-Adaptive Sparse Training of DNNs at the Data-Scarce Edge
Young D. Kwon, Rui Li, Stylianos I. Venieris, Jagmohan Chauhan, Nicholas D. Lane, Cecilia Mascolo
On-device training is essential for user personalisation and privacy. With the pervasiveness of IoT devices and microcontroller units (MCUs), this task becomes more challenging due to the constrained memory and compute resources, and the limited availability of labelled user data. Nonetheless, prior works neglect the data scarcity issue, require excessively long training time (e.g. a few hours), or induce substantial accuracy loss (>10%). In this paper, we propose TinyTrain, an on-device training approach that drastically reduces training time by selectively updating parts of the model and explicitly coping with data scarcity. TinyTrain introduces a task-adaptive sparse-update method that dynamically selects the layer/channel to update based on a multi-objective criterion that jointly captures user data, the memory, and the compute capabilities of the target device, leading to high accuracy on unseen tasks with reduced computation and memory footprint. TinyTrain outperforms vanilla fine-tuning of the entire network by 3.6-5.0% in accuracy, while reducing the backward-pass memory and computation cost by up to 1,098x and 7.68x, respectively. Targeting broadly used real-world edge devices, TinyTrain achieves 9.5x faster and 3.5x more energy-efficient training over status-quo approaches, and 2.23x smaller memory footprint than SOTA methods, while remaining within the 1 MB memory envelope of MCU-grade platforms.
Read more6/12/2024
🏋️
7
On-Device Training Under 256KB Memory
Ji Lin, Ligeng Zhu, Wei-Ming Chen, Wei-Chen Wang, Chuang Gan, Song Han
On-device training enables the model to adapt to new data collected from the sensors by fine-tuning a pre-trained model. Users can benefit from customized AI models without having to transfer the data to the cloud, protecting the privacy. However, the training memory consumption is prohibitive for IoT devices that have tiny memory resources. We propose an algorithm-system co-design framework to make on-device training possible with only 256KB of memory. On-device training faces two unique challenges: (1) the quantized graphs of neural networks are hard to optimize due to low bit-precision and the lack of normalization; (2) the limited hardware resource does not allow full back-propagation. To cope with the optimization difficulty, we propose Quantization-Aware Scaling to calibrate the gradient scales and stabilize 8-bit quantized training. To reduce the memory footprint, we propose Sparse Update to skip the gradient computation of less important layers and sub-tensors. The algorithm innovation is implemented by a lightweight training system, Tiny Training Engine, which prunes the backward computation graph to support sparse updates and offload the runtime auto-differentiation to compile time. Our framework is the first solution to enable tiny on-device training of convolutional neural networks under 256KB SRAM and 1MB Flash without auxiliary memory, using less than 1/1000 of the memory of PyTorch and TensorFlow while matching the accuracy on tinyML application VWW. Our study enables IoT devices not only to perform inference but also to continuously adapt to new data for on-device lifelong learning. A video demo can be found here: https://youtu.be/0pUFZYdoMY8.
Read more4/4/2024