Continual Learning of Diffusion Models with Generative Distillation
2311.14028
0
0

Abstract
Diffusion models are powerful generative models that achieve state-of-the-art performance in image synthesis. However, training them demands substantial amounts of data and computational resources. Continual learning would allow for incrementally learning new tasks and accumulating knowledge, thus enabling the reuse of trained models for further learning. One potentially suitable continual learning approach is generative replay, where a copy of a generative model trained on previous tasks produces synthetic data that are interleaved with data from the current task. However, standard generative replay applied to diffusion models results in a catastrophic loss in denoising capabilities. In this paper, we propose generative distillation, an approach that distils the entire reverse process of a diffusion model. We demonstrate that our approach substantially improves the continual learning performance of generative replay with only a modest increase in the computational costs.
Create account to get full access
Overview
- This paper explores a novel approach for continual learning of diffusion models, which are a type of generative model used for tasks like image synthesis.
- The key idea is to use "generative distillation" - training a new diffusion model to match the outputs of a previously trained model on a new dataset, rather than training the new model from scratch.
- This allows the model to learn new data distributions without forgetting previous ones, addressing a common challenge in continual learning.
- The authors demonstrate the effectiveness of their approach through experiments on various image datasets, showing improved performance compared to baselines.
Plain English Explanation
Diffusion models are a powerful type of machine learning model that can generate new images, audio, or other data by learning patterns from existing examples. However, a common problem with these models is that as they are trained on new data over time, they tend to "forget" what they learned previously. This makes it difficult for the model to maintain high performance across multiple datasets.
The researchers in this paper propose a new technique called "generative distillation" to address this challenge. The key idea is to take an existing diffusion model that has been trained on one set of data, and use that model to help train a new diffusion model on a different dataset. This "distillation" process allows the new model to learn the new data distribution while preserving what the original model had learned.
[Imagine a teacher (the original model) helping a student (the new model) learn a new subject by providing guidance and examples, rather than having the student start from scratch. This helps the student learn the new material more efficiently while still retaining what they previously learned.]
Through experiments, the researchers demonstrate that their generative distillation approach allows diffusion models to continually learn new datasets without forgetting old ones. This is an important step forward, as it makes these powerful generative models more practical for real-world applications where data is constantly evolving.
Technical Explanation
The key technical components of this paper are:
-
Continual Learning of Diffusion Models: The authors tackle the problem of continual learning for diffusion models, where a model must learn new data distributions over time without forgetting previous ones. This is a challenging problem as diffusion models are trained in an unsupervised manner, making it difficult to incorporate new knowledge without catastrophically forgetting old knowledge.
-
Generative Distillation: To address this, the authors propose a "generative distillation" approach, where a new diffusion model is trained to match the outputs of a previously trained model on a new dataset. This allows the new model to learn the new data distribution while preserving the knowledge encoded in the original model. [This builds on prior work on diffusion model distillation, such as the paper "Distilling Diffusion Models for Text Generation."]
-
Experiments: The authors evaluate their approach on various image datasets, including CIFAR-10, CelebA, and ImageNet. They compare their generative distillation method to several baselines, including fine-tuning and joint training, and demonstrate improved performance in terms of both sample quality and downstream task performance.
-
Insights: The paper provides insights into the benefits of their generative distillation approach, showing that it allows diffusion models to continually learn new data distributions without forgetting previous ones. This is a significant advancement, as it makes these powerful generative models more practical for real-world applications where data is constantly evolving.
Critical Analysis
The authors provide a thorough evaluation of their generative distillation approach, considering various baselines and dataset settings. However, some potential limitations and areas for further research include:
- The experiments are primarily focused on image datasets, and it would be valuable to explore the method's performance on other data modalities, such as audio or text.
- The paper does not address potential issues with the computational or memory overhead of maintaining multiple diffusion models over time, which could be an important practical consideration.
- While the authors demonstrate improved performance compared to baselines, there may be room for further innovations to enhance the efficiency and effectiveness of the continual learning process.
Overall, the paper presents a compelling approach to a relevant problem in the field of generative modeling, and the authors have made a valuable contribution to the ongoing research on continual learning for powerful generative models like diffusion models.
Conclusion
This paper introduces a novel approach for continual learning of diffusion models, a type of generative model used for tasks like image synthesis. The key innovation is the use of "generative distillation," where a new diffusion model is trained to match the outputs of a previously trained model on a new dataset, rather than starting from scratch.
This allows the model to learn new data distributions without forgetting previous ones, addressing a common challenge in continual learning. Through experiments on various image datasets, the authors demonstrate the effectiveness of their approach, showing improved performance compared to baselines.
The findings in this paper represent an important step forward in making powerful generative models like diffusion models more practical for real-world applications where data is constantly evolving. The insights and techniques presented here could inspire further research on continual learning for a wide range of generative modeling tasks and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
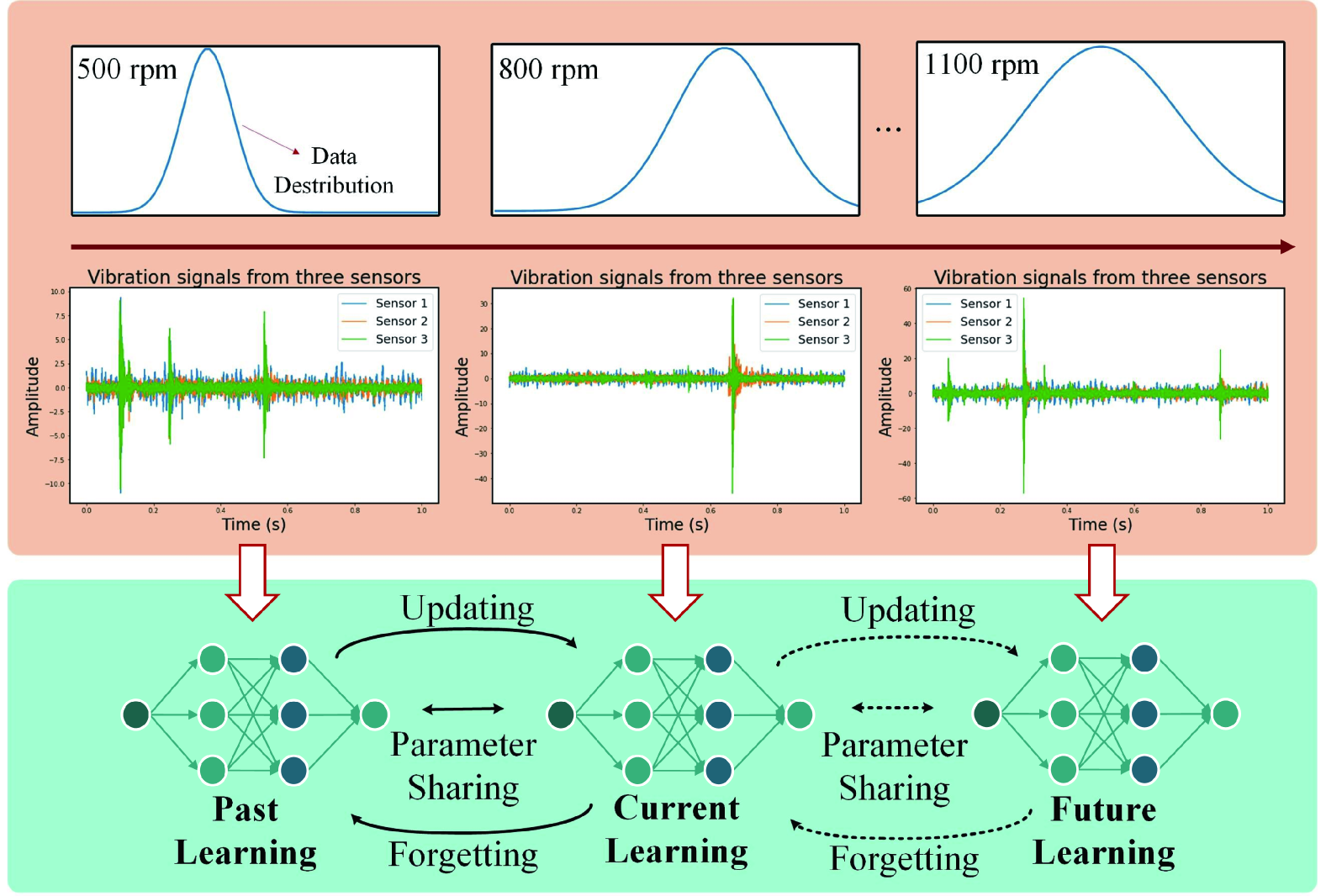
Continual Learning with Diffusion-based Generative Replay for Industrial Streaming Data
Jiayi He, Jiao Chen, Qianmiao Liu, Suyan Dai, Jianhua Tang, Dongpo Liu
0
0
The Industrial Internet of Things (IIoT) integrates interconnected sensors and devices to support industrial applications, but its dynamic environments pose challenges related to data drift. Considering the limited resources and the need to effectively adapt models to new data distributions, this paper introduces a Continual Learning (CL) approach, i.e., Distillation-based Self-Guidance (DSG), to address challenges presented by industrial streaming data via a novel generative replay mechanism. DSG utilizes knowledge distillation to transfer knowledge from the previous diffusion-based generator to the updated one, improving both the stability of the generator and the quality of reproduced data, thereby enhancing the mitigation of catastrophic forgetting. Experimental results on CWRU, DSA, and WISDM datasets demonstrate the effectiveness of DSG. DSG outperforms the state-of-the-art baseline in accuracy, demonstrating improvements ranging from 2.9% to 5.0% on key datasets, showcasing its potential for practical industrial applications.
6/26/2024

Continual Offline Reinforcement Learning via Diffusion-based Dual Generative Replay
Jinmei Liu, Wenbin Li, Xiangyu Yue, Shilin Zhang, Chunlin Chen, Zhi Wang
0
0
We study continual offline reinforcement learning, a practical paradigm that facilitates forward transfer and mitigates catastrophic forgetting to tackle sequential offline tasks. We propose a dual generative replay framework that retains previous knowledge by concurrent replay of generated pseudo-data. First, we decouple the continual learning policy into a diffusion-based generative behavior model and a multi-head action evaluation model, allowing the policy to inherit distributional expressivity for encompassing a progressive range of diverse behaviors. Second, we train a task-conditioned diffusion model to mimic state distributions of past tasks. Generated states are paired with corresponding responses from the behavior generator to represent old tasks with high-fidelity replayed samples. Finally, by interleaving pseudo samples with real ones of the new task, we continually update the state and behavior generators to model progressively diverse behaviors, and regularize the multi-head critic via behavior cloning to mitigate forgetting. Experiments demonstrate that our method achieves better forward transfer with less forgetting, and closely approximates the results of using previous ground-truth data due to its high-fidelity replay of the sample space. Our code is available at href{https://github.com/NJU-RL/CuGRO}{https://github.com/NJU-RL/CuGRO}.
4/19/2024

Online Continual Learning of Video Diffusion Models From a Single Video Stream
Jason Yoo, Dylan Green, Geoff Pleiss, Frank Wood
0
0
Diffusion models have shown exceptional capabilities in generating realistic videos. Yet, their training has been predominantly confined to offline environments where models can repeatedly train on i.i.d. data to convergence. This work explores the feasibility of training diffusion models from a semantically continuous video stream, where correlated video frames sequentially arrive one at a time. To investigate this, we introduce two novel continual video generative modeling benchmarks, Lifelong Bouncing Balls and Windows 95 Maze Screensaver, each containing over a million video frames generated from navigating stationary environments. Surprisingly, our experiments show that diffusion models can be effectively trained online using experience replay, achieving performance comparable to models trained with i.i.d. samples given the same number of gradient steps.
6/10/2024
📉
Distilling Diffusion Models into Conditional GANs
Minguk Kang, Richard Zhang, Connelly Barnes, Sylvain Paris, Suha Kwak, Jaesik Park, Eli Shechtman, Jun-Yan Zhu, Taesung Park
0
0
We propose a method to distill a complex multistep diffusion model into a single-step conditional GAN student model, dramatically accelerating inference, while preserving image quality. Our approach interprets diffusion distillation as a paired image-to-image translation task, using noise-to-image pairs of the diffusion model's ODE trajectory. For efficient regression loss computation, we propose E-LatentLPIPS, a perceptual loss operating directly in diffusion model's latent space, utilizing an ensemble of augmentations. Furthermore, we adapt a diffusion model to construct a multi-scale discriminator with a text alignment loss to build an effective conditional GAN-based formulation. E-LatentLPIPS converges more efficiently than many existing distillation methods, even accounting for dataset construction costs. We demonstrate that our one-step generator outperforms cutting-edge one-step diffusion distillation models -- DMD, SDXL-Turbo, and SDXL-Lightning -- on the zero-shot COCO benchmark.
6/17/2024