Continual Offline Reinforcement Learning via Diffusion-based Dual Generative Replay
2404.10662
0
0

Abstract
We study continual offline reinforcement learning, a practical paradigm that facilitates forward transfer and mitigates catastrophic forgetting to tackle sequential offline tasks. We propose a dual generative replay framework that retains previous knowledge by concurrent replay of generated pseudo-data. First, we decouple the continual learning policy into a diffusion-based generative behavior model and a multi-head action evaluation model, allowing the policy to inherit distributional expressivity for encompassing a progressive range of diverse behaviors. Second, we train a task-conditioned diffusion model to mimic state distributions of past tasks. Generated states are paired with corresponding responses from the behavior generator to represent old tasks with high-fidelity replayed samples. Finally, by interleaving pseudo samples with real ones of the new task, we continually update the state and behavior generators to model progressively diverse behaviors, and regularize the multi-head critic via behavior cloning to mitigate forgetting. Experiments demonstrate that our method achieves better forward transfer with less forgetting, and closely approximates the results of using previous ground-truth data due to its high-fidelity replay of the sample space. Our code is available at href{https://github.com/NJU-RL/CuGRO}{https://github.com/NJU-RL/CuGRO}.
Create account to get full access
Overview
- This paper introduces a novel approach called Continual Offline Reinforcement Learning via Diffusion-based Dual Generative Replay (CODGER) for continual learning in offline reinforcement learning settings.
- The key idea is to use diffusion models to generate diverse yet high-quality samples from past tasks, which are then used to update the current policy without catastrophic forgetting.
- The authors demonstrate CODGER's effectiveness on several continuous control tasks, showing it can outperform state-of-the-art continual learning methods.
Plain English Explanation
In offline reinforcement learning, an agent learns from a fixed dataset of past experiences, without the ability to interact with the environment. This is a challenging setting, as the agent must learn new skills without forgetting old ones.
The authors of this paper propose a new method called CODGER to address this challenge. The key insight is to use diffusion models - a type of generative AI model - to generate diverse yet high-quality samples from past tasks. These samples are then used to update the agent's policy, allowing it to learn new skills without forgetting old ones.
This approach is inspired by the concept of generative replay, where an agent learns by repeatedly generating and learning from samples of past experiences. By using diffusion models, CODGER can generate more realistic and diverse samples compared to traditional generative replay methods.
The authors evaluate CODGER on several continuous control tasks, where the agent must learn to perform different physical skills over time. They show that CODGER outperforms state-of-the-art continual learning methods, demonstrating its effectiveness in the challenging offline reinforcement learning setting.
Technical Explanation
The authors first formalize the problem of continual offline reinforcement learning, where the agent must learn a sequence of tasks from a fixed dataset without forgetting previously learned skills.
To address this, the authors propose CODGER, which uses two key components:
-
A diffusion-based generator to produce diverse yet high-quality samples from past tasks. This allows the agent to generate samples that are similar to the original data, but different enough to avoid catastrophic forgetting.
-
A dual learning setup, where the agent simultaneously learns to predict the next state and action from the generated samples (the "generative" objective) and to maximize the expected return (the "policy" objective). This helps the agent learn effective policies while also maintaining a diverse set of past experiences.
The authors conduct experiments on several continuous control benchmarks, where the agent must learn a sequence of locomotion and manipulation tasks. They show that CODGER outperforms state-of-the-art continual learning methods, such as Offline Trajectory Generalization and Distributed Distributional Dueling DQN, in terms of final performance and the ability to retain past skills.
Critical Analysis
The authors acknowledge several limitations of their work. First, the performance of CODGER is still dependent on the quality of the initial offline dataset, and it may struggle in settings with significant distribution shift between tasks. Additionally, the computational cost of training the diffusion model and the dual learning objectives may be higher than simpler continual learning methods.
It would also be interesting to see how CODGER performs on more diverse task sequences, such as those involving both discrete and continuous control problems, or tasks with significantly different state and action spaces. The authors' evaluation is primarily focused on continuous control tasks, and it's unclear how well the method would generalize to other domains.
Furthermore, the paper does not provide a detailed analysis of the type of samples generated by the diffusion model or how they contribute to the agent's learning. A deeper understanding of the generative process and its relationship to the agent's policy updates could lead to further improvements in the method.
Conclusion
This paper presents a novel approach called CODGER for tackling the challenge of continual offline reinforcement learning. By leveraging diffusion models to generate diverse yet high-quality samples from past tasks, CODGER is able to learn new skills without forgetting old ones. The authors demonstrate the effectiveness of their method on several continuous control benchmarks, outperforming state-of-the-art continual learning approaches.
While the paper has some limitations, CODGER represents an important step forward in addressing the challenging problem of continual learning in offline reinforcement learning settings. The use of generative models to address catastrophic forgetting is a promising direction, and this work could inspire further research in this area with implications for a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Continual Learning of Diffusion Models with Generative Distillation
Sergi Masip, Pau Rodriguez, Tinne Tuytelaars, Gido M. van de Ven
0
0
Diffusion models are powerful generative models that achieve state-of-the-art performance in image synthesis. However, training them demands substantial amounts of data and computational resources. Continual learning would allow for incrementally learning new tasks and accumulating knowledge, thus enabling the reuse of trained models for further learning. One potentially suitable continual learning approach is generative replay, where a copy of a generative model trained on previous tasks produces synthetic data that are interleaved with data from the current task. However, standard generative replay applied to diffusion models results in a catastrophic loss in denoising capabilities. In this paper, we propose generative distillation, an approach that distils the entire reverse process of a diffusion model. We demonstrate that our approach substantially improves the continual learning performance of generative replay with only a modest increase in the computational costs.
5/21/2024

t-DGR: A Trajectory-Based Deep Generative Replay Method for Continual Learning in Decision Making
William Yue, Bo Liu, Peter Stone
0
0
Deep generative replay has emerged as a promising approach for continual learning in decision-making tasks. This approach addresses the problem of catastrophic forgetting by leveraging the generation of trajectories from previously encountered tasks to augment the current dataset. However, existing deep generative replay methods for continual learning rely on autoregressive models, which suffer from compounding errors in the generated trajectories. In this paper, we propose a simple, scalable, and non-autoregressive method for continual learning in decision-making tasks using a generative model that generates task samples conditioned on the trajectory timestep. We evaluate our method on Continual World benchmarks and find that our approach achieves state-of-the-art performance on the average success rate metric among continual learning methods. Code is available at https://github.com/WilliamYue37/t-DGR.
6/18/2024
🏅
OER: Offline Experience Replay for Continual Offline Reinforcement Learning
Sibo Gai, Donglin Wang, Li He
0
0
The capability of continuously learning new skills via a sequence of pre-collected offline datasets is desired for an agent. However, consecutively learning a sequence of offline tasks likely leads to the catastrophic forgetting issue under resource-limited scenarios. In this paper, we formulate a new setting, continual offline reinforcement learning (CORL), where an agent learns a sequence of offline reinforcement learning tasks and pursues good performance on all learned tasks with a small replay buffer without exploring any of the environments of all the sequential tasks. For consistently learning on all sequential tasks, an agent requires acquiring new knowledge and meanwhile preserving old knowledge in an offline manner. To this end, we introduced continual learning algorithms and experimentally found experience replay (ER) to be the most suitable algorithm for the CORL problem. However, we observe that introducing ER into CORL encounters a new distribution shift problem: the mismatch between the experiences in the replay buffer and trajectories from the learned policy. To address such an issue, we propose a new model-based experience selection (MBES) scheme to build the replay buffer, where a transition model is learned to approximate the state distribution. This model is used to bridge the distribution bias between the replay buffer and the learned model by filtering the data from offline data that most closely resembles the learned model for storage. Moreover, in order to enhance the ability on learning new tasks, we retrofit the experience replay method with a new dual behavior cloning (DBC) architecture to avoid the disturbance of behavior-cloning loss on the Q-learning process. In general, we call our algorithm offline experience replay (OER). Extensive experiments demonstrate that our OER method outperforms SOTA baselines in widely-used Mujoco environments.
4/23/2024
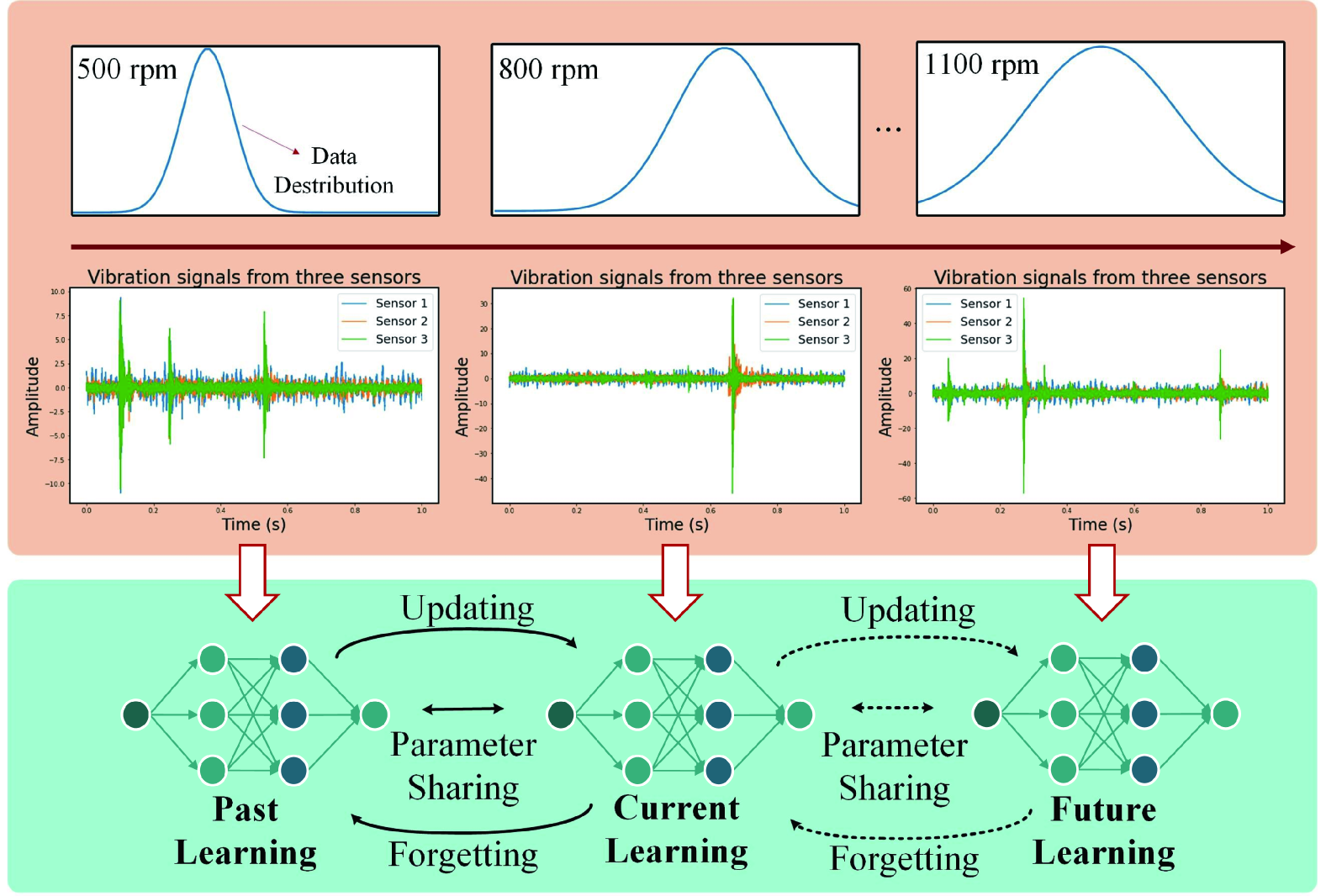
Continual Learning with Diffusion-based Generative Replay for Industrial Streaming Data
Jiayi He, Jiao Chen, Qianmiao Liu, Suyan Dai, Jianhua Tang, Dongpo Liu
0
0
The Industrial Internet of Things (IIoT) integrates interconnected sensors and devices to support industrial applications, but its dynamic environments pose challenges related to data drift. Considering the limited resources and the need to effectively adapt models to new data distributions, this paper introduces a Continual Learning (CL) approach, i.e., Distillation-based Self-Guidance (DSG), to address challenges presented by industrial streaming data via a novel generative replay mechanism. DSG utilizes knowledge distillation to transfer knowledge from the previous diffusion-based generator to the updated one, improving both the stability of the generator and the quality of reproduced data, thereby enhancing the mitigation of catastrophic forgetting. Experimental results on CWRU, DSA, and WISDM datasets demonstrate the effectiveness of DSG. DSG outperforms the state-of-the-art baseline in accuracy, demonstrating improvements ranging from 2.9% to 5.0% on key datasets, showcasing its potential for practical industrial applications.
6/26/2024