Contract Scheduling with Distributional and Multiple Advice
2404.12485
0
0

Abstract
Contract scheduling is a widely studied framework for designing real-time systems with interruptible capabilities. Previous work has showed that a prediction on the interruption time can help improve the performance of contract-based systems, however it has relied on a single prediction that is provided by a deterministic oracle. In this work, we introduce and study more general and realistic learning-augmented settings in which the prediction is in the form of a probability distribution, or it is given as a set of multiple possible interruption times. For both prediction settings, we design and analyze schedules which perform optimally if the prediction is accurate, while simultaneously guaranteeing the best worst-case performance if the prediction is adversarial. We also provide evidence that the resulting system is robust to prediction errors in the distributional setting. Last, we present an experimental evaluation that confirms the theoretical findings, and illustrates the performance improvements that can be attained in practice.
Create account to get full access
Overview
- This paper explores a contract scheduling problem where the goal is to assign tasks to workers under time and budget constraints while leveraging distributional and multiple advice.
- The authors propose a novel approach that combines reinforcement learning with distributional and ensemble methods to improve scheduling decisions.
- The research aims to advance the field of contract scheduling, which has important real-world applications in areas like project management, manufacturing, and service industries.
Plain English Explanation
In the real world, companies often need to assign tasks or "contracts" to workers while dealing with time and budget limitations. This is known as the "contract scheduling problem." The authors of this paper have developed a new way to approach this problem by using machine learning techniques like reinforcement learning, which allows the system to learn from experience, and ensemble methods, which combine multiple prediction models to improve accuracy.
A key innovation in this paper is the use of "distributional" and "multiple" advice. "Distributional" advice means the system considers a range of possible outcomes, rather than just a single prediction. "Multiple" advice means the system uses input from several different sources, like expert opinions or data from past projects, to make its decisions. This can help the system make more informed and robust scheduling choices.
Overall, this research aims to make contract scheduling more efficient and effective, which could have important benefits for businesses and organizations in many industries. By using advanced machine learning techniques, the authors hope to create scheduling systems that can adapt to different situations and constraints, leading to better outcomes for both workers and the companies they serve.
Technical Explanation
The authors propose a reinforcement learning-based approach to the contract scheduling problem that incorporates distributional and ensemble methods. The core idea is to learn a scheduling policy that can efficiently allocate tasks to workers while considering multiple sources of advice and uncertainty in the problem parameters.
The technical approach involves the following key elements:
-
Distributional Advice: Rather than relying on point estimates of problem parameters (e.g., task durations), the system models these as probability distributions. This allows it to reason about the range of possible outcomes and make more robust decisions.
-
Multiple Advice: The system aggregates input from various sources, such as expert knowledge and historical data, using an ensemble method. This ensemble advice is then used to guide the reinforcement learning process.
-
Scheduling Policy Learning: The authors formulate the contract scheduling problem as a Markov Decision Process and use a deep reinforcement learning algorithm to learn an effective scheduling policy. This policy maps the current state of the scheduling problem to the best action to take (i.e., which task to assign to which worker).
Through extensive experiments, the authors demonstrate that their approach outperforms several baseline methods on a range of contract scheduling problem instances. They also provide insights into the relative importance of distributional and ensemble advice in achieving high-quality scheduling decisions.
Critical Analysis
The authors have made a valuable contribution to the contract scheduling literature by introducing a novel reinforcement learning-based approach that leverages distributional and ensemble methods. This work shows how advanced machine learning techniques can be applied to solve complex real-world scheduling problems more effectively.
One potential limitation of the research is the reliance on simulated problem instances. While this allows for controlled experimentation, it would be beneficial to evaluate the proposed approach on real-world contract scheduling data to assess its practicality and generalizability. Additionally, the authors do not provide a detailed analysis of the computational complexity and scalability of their method, which are important considerations for large-scale scheduling problems.
Furthermore, the paper does not explore the implications of the distributional and ensemble advice on the interpretability and explainability of the learned scheduling policy. In many real-world applications, it is crucial to understand the reasoning behind scheduling decisions, and this aspect could be further investigated in future research.
Conclusion
This paper presents a promising approach to the contract scheduling problem that combines reinforcement learning with distributional and ensemble methods. By considering a range of possible outcomes and aggregating advice from multiple sources, the system is able to make more informed and robust scheduling decisions. While further research is needed to fully assess the practical implications of this work, the authors have made a valuable contribution to the field of scheduling optimization and decision-making under uncertainty.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
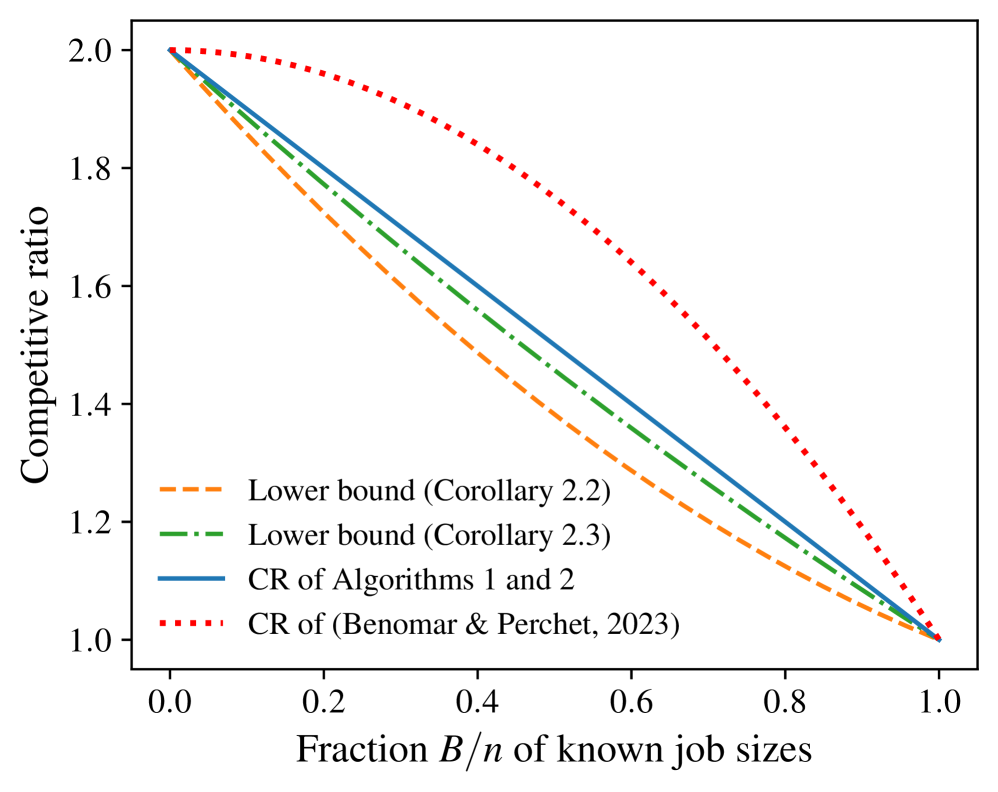
Non-clairvoyant Scheduling with Partial Predictions
Ziyad Benomar, Vianney Perchet
0
0
The non-clairvoyant scheduling problem has gained new interest within learning-augmented algorithms, where the decision-maker is equipped with predictions without any quality guarantees. In practical settings, access to predictions may be reduced to specific instances, due to cost or data limitations. Our investigation focuses on scenarios where predictions for only $B$ job sizes out of $n$ are available to the algorithm. We first establish near-optimal lower bounds and algorithms in the case of perfect predictions. Subsequently, we present a learning-augmented algorithm satisfying the robustness, consistency, and smoothness criteria, and revealing a novel tradeoff between consistency and smoothness inherent in the scenario with a restricted number of predictions.
5/3/2024
🏅
Design and Scheduling of an AI-based Queueing System
Jiung Lee, Hongseok Namkoong, Yibo Zeng
0
0
To leverage prediction models to make optimal scheduling decisions in service systems, we must understand how predictive errors impact congestion due to externalities on the delay of other jobs. Motivated by applications where prediction models interact with human servers (e.g., content moderation), we consider a large queueing system comprising of many single server queues where the class of a job is estimated using a prediction model. By characterizing the impact of mispredictions on congestion cost in heavy traffic, we design an index-based policy that incorporates the predicted class information in a near-optimal manner. Our theoretical results guide the design of predictive models by providing a simple model selection procedure with downstream queueing performance as a central concern, and offer novel insights on how to design queueing systems with AI-based triage. We illustrate our framework on a content moderation task based on real online comments, where we construct toxicity classifiers by finetuning large language models.
6/12/2024
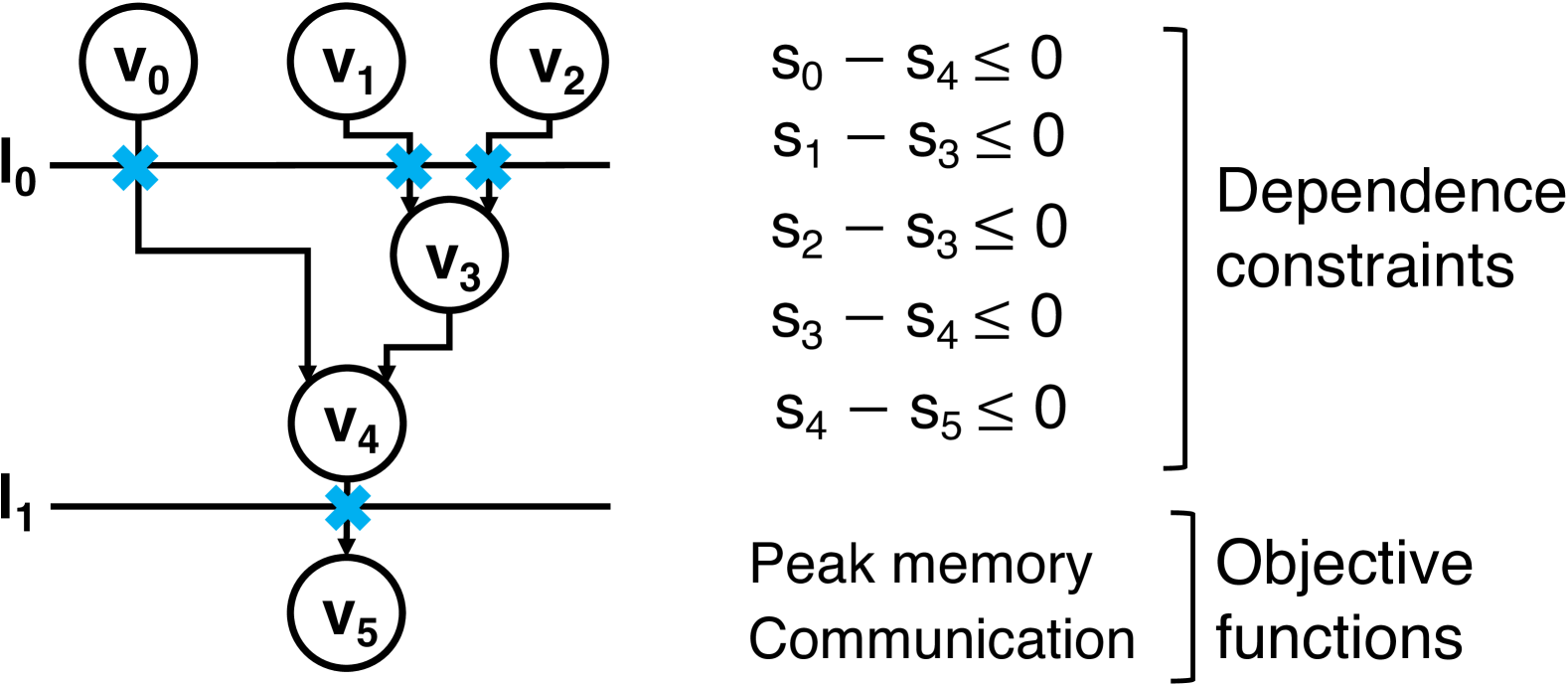
Differentiable Combinatorial Scheduling at Scale
Mingju Liu, Yingjie Li, Jiaqi Yin, Zhiru Zhang, Cunxi Yu
0
0
This paper addresses the complex issue of resource-constrained scheduling, an NP-hard problem that spans critical areas including chip design and high-performance computing. Traditional scheduling methods often stumble over scalability and applicability challenges. We propose a novel approach using a differentiable combinatorial scheduling framework, utilizing Gumbel-Softmax differentiable sampling technique. This new technical allows for a fully differentiable formulation of linear programming (LP) based scheduling, extending its application to a broader range of LP formulations. To encode inequality constraints for scheduling tasks, we introduce textit{constrained Gumbel Trick}, which adeptly encodes arbitrary inequality constraints. Consequently, our method facilitates an efficient and scalable scheduling via gradient descent without the need for training data. Comparative evaluations on both synthetic and real-world benchmarks highlight our capability to significantly improve the optimization efficiency of scheduling, surpassing state-of-the-art solutions offered by commercial and open-source solvers such as CPLEX, Gurobi, and CP-SAT in the majority of the designs.
6/12/2024
🔄
Efficient Multi-Processor Scheduling in Increasingly Realistic Models
P'al Andr'as Papp, Georg Anegg, Aikaterini Karanasiou, A. N. Yzelman
0
0
We study the problem of efficiently scheduling a computational DAG on multiple processors. The majority of previous works have developed and compared algorithms for this problem in relatively simple models; in contrast to this, we analyze this problem in a more realistic model that captures many real-world aspects, such as communication costs, synchronization costs, and the hierarchical structure of modern processing architectures. For this we extend the well-established BSP model of parallel computing with non-uniform memory access (NUMA) effects. We then develop a range of new scheduling algorithms to minimize the scheduling cost in this more complex setting: several initialization heuristics, a hill-climbing local search method, and several approaches that formulate (and solve) the scheduling problem as an Integer Linear Program (ILP). We combine these algorithms into a single framework, and conduct experiments on a diverse set of real-world computational DAGs to show that the resulting scheduler significantly outperforms both academic and practical baselines. In particular, even without NUMA effects, our scheduler finds solutions of 24%-44% smaller cost on average than the baselines, and in case of NUMA effects, it achieves up to a factor $2.5times$ improvement compared to the baselines. Finally, we also develop a multilevel scheduling algorithm, which provides up to almost a factor $5times$ improvement in the special case when the problem is dominated by very high communication costs.
4/24/2024