Contrastive Federated Learning with Tabular Data Silos

0

Sign in to get full access
Overview
- Examines a contrastive learning approach for federated learning with tabular data silos
- Proposes a novel contrastive federated learning (CFL) algorithm to improve model performance and overcome data heterogeneity
- Demonstrates effectiveness on various benchmark datasets through extensive experiments
Plain English Explanation
The paper introduces a new technique called contrastive federated learning (CFL) to address challenges in federated learning, where multiple parties collaborate to train a shared machine learning model without sharing their private data.
In a typical federated learning setup, each participant holds their own dataset, which can vary greatly in distribution and characteristics. This data heterogeneity makes it difficult to train an effective global model. The authors propose using contrastive learning, a technique that learns representations by maximizing the similarity between related data samples and minimizing the similarity between unrelated samples.
By incorporating contrastive learning into the federated training process, the CFL algorithm is able to learn more robust and generalizable representations that better account for the diverse data distributions across participants. This leads to improved model performance compared to standard federated learning approaches.
The key idea is to have each participant learn not only the primary task, but also to capture the underlying structure and relationships within their local data through the contrastive objective. The central server then aggregates these learned representations to build a global model that is more effective at handling statistical heterogeneity across the federated dataset.
Technical Explanation
The paper proposes a contrastive federated learning (CFL) algorithm to address the challenges of data heterogeneity in federated learning settings. The core idea is to incorporate contrastive learning into the standard federated learning framework to learn more robust and generalizable representations.
In the CFL approach, each participant trains a local model not only on the primary task, but also on a contrastive learning objective. This contrastive objective aims to maximize the similarity between related data samples (e.g., samples from the same class) and minimize the similarity between unrelated samples. By learning these representations, the local models can better capture the underlying structure and relationships within the participant's private dataset.
The central server then aggregates the learned representations from the participants to build a global model. This global model is expected to be more effective at handling the statistical heterogeneity across the federated dataset compared to standard federated learning approaches.
The authors evaluate the CFL algorithm on various benchmark datasets and demonstrate its effectiveness in improving model performance over baseline federated learning methods. The results show that CFL is able to learn more informative representations and achieve higher accuracy on the primary task, even in the presence of significant data heterogeneity.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated approach to addressing the data heterogeneity challenge in federated learning. The authors provide a compelling motivation for using contrastive learning to capture the underlying structure of the participants' private datasets and incorporate this information into the global model.
One potential limitation of the CFL approach is the increased computational and communication overhead compared to standard federated learning. The additional contrastive learning objective at the local level may require more training time and resources, which could be a concern for resource-constrained participants.
Additionally, the paper does not explore the impact of hyperparameter tuning or the sensitivity of the CFL algorithm to different levels of data heterogeneity. Further research could investigate these aspects to provide a more comprehensive understanding of the method's strengths and limitations.
Overall, the paper makes a valuable contribution to the field of federated learning by demonstrating the benefits of incorporating contrastive learning techniques to improve model performance in the presence of data heterogeneity. The CFL algorithm provides a promising direction for enhancing federated learning systems and deserves further exploration and refinement.
Conclusion
The paper introduces a novel contrastive federated learning (CFL) algorithm that leverages contrastive learning to address the data heterogeneity challenge in federated learning. By having each participant learn representations that capture the underlying structure of their local data, the CFL approach is able to build a more effective global model that can better handle the diverse data distributions across the federated dataset.
The authors demonstrate the effectiveness of CFL through extensive experiments on various benchmark datasets, showing significant performance improvements over standard federated learning methods. This work contributes to the growing body of research exploring techniques to enhance federated learning systems and overcome the limitations imposed by data heterogeneity.
Overall, the CFL algorithm represents an important step forward in the field of federated learning, and the insights gained from this research can inspire further advancements in developing robust and adaptable federated learning solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Contrastive Federated Learning with Tabular Data Silos
Achmad Ginanjar, Xue Li, Wen Hua
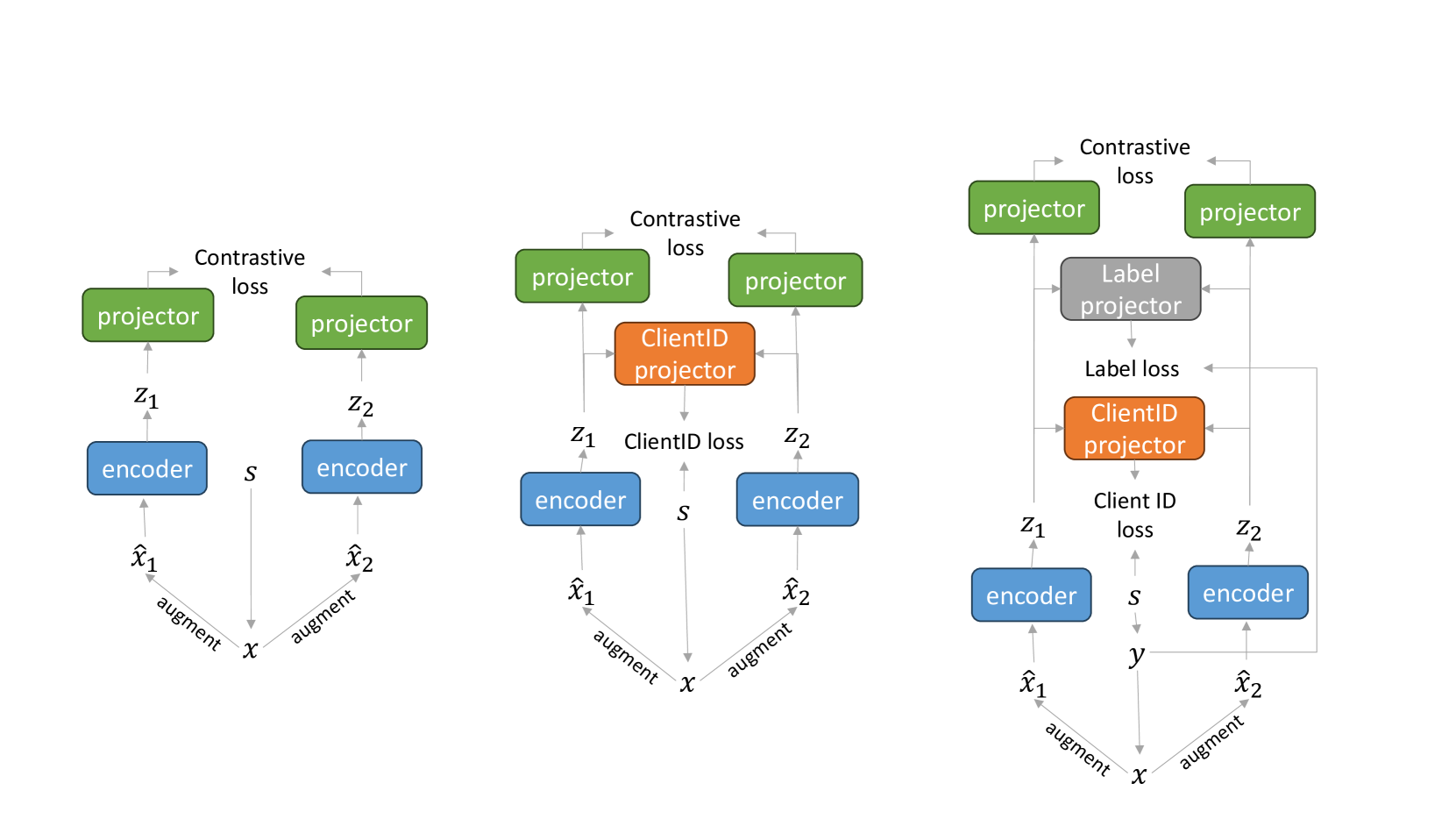
Learning from data silos is a difficult task for organizations that need to obtain knowledge of objects that appeared in multiple independent data silos. Objects in multi-organizations, such as government agents, are referred by different identifiers, such as driver license, passport number, and tax file number. The data distributions in data silos are mostly non-IID (Independently and Identically Distributed), labelless, and vertically partitioned (i.e., having different attributes). Privacy concerns harden the above issues. Conditions inhibit enthusiasm for collaborative work. While Federated Learning (FL) has been proposed to address these issues, the difficulty of labeling, namely, label costliness, often hinders optimal model performance. A potential solution lies in contrastive learning, an unsupervised self-learning technique to represent semantic data by contrasting similar data pairs. However, contrastive learning is currently not designed to handle tabular data silos that existed within multiple organizations where data linkage by quasi identifiers are needed. To address these challenges, we propose using semi-supervised contrastive federated learning, which we refer to as Contrastive Federated Learning with Data Silos (CFL). Our approach tackles the aforementioned issues with an integrated solution. Our experimental results demonstrate that CFL outperforms current methods in addressing these challenges and providing improvements in accuracy. Additionally, we present positive results that showcase the advantages of our contrastive federated learning approach in complex client environments.
Read more9/11/2024

0
Relaxed Contrastive Learning for Federated Learning
Seonguk Seo, Jinkyu Kim, Geeho Kim, Bohyung Han
We propose a novel contrastive learning framework to effectively address the challenges of data heterogeneity in federated learning. We first analyze the inconsistency of gradient updates across clients during local training and establish its dependence on the distribution of feature representations, leading to the derivation of the supervised contrastive learning (SCL) objective to mitigate local deviations. In addition, we show that a naive adoption of SCL in federated learning leads to representation collapse, resulting in slow convergence and limited performance gains. To address this issue, we introduce a relaxed contrastive learning loss that imposes a divergence penalty on excessively similar sample pairs within each class. This strategy prevents collapsed representations and enhances feature transferability, facilitating collaborative training and leading to significant performance improvements. Our framework outperforms all existing federated learning approaches by huge margins on the standard benchmarks through extensive experimental results.
Read more6/3/2024

0
Federated Impression for Learning with Distributed Heterogeneous Data
Sana Ayromlou, Atrin Arya, Armin Saadat, Purang Abolmaesumi, Xiaoxiao Li
Standard deep learning-based classification approaches may not always be practical in real-world clinical applications, as they require a centralized collection of all samples. Federated learning (FL) provides a paradigm that can learn from distributed datasets across clients without requiring them to share data, which can help mitigate privacy and data ownership issues. In FL, sub-optimal convergence caused by data heterogeneity is common among data from different health centers due to the variety in data collection protocols and patient demographics across centers. Through experimentation in this study, we show that data heterogeneity leads to the phenomenon of catastrophic forgetting during local training. We propose FedImpres which alleviates catastrophic forgetting by restoring synthetic data that represents the global information as federated impression. To achieve this, we distill the global model resulting from each communication round. Subsequently, we use the synthetic data alongside the local data to enhance the generalization of local training. Extensive experiments show that the proposed method achieves state-of-the-art performance on both the BloodMNIST and Retina datasets, which contain label imbalance and domain shift, with an improvement in classification accuracy of up to 20%.
Read more9/12/2024
0
A Mutual Information Perspective on Federated Contrastive Learning
Christos Louizos, Matthias Reisser, Denis Korzhenkov
We investigate contrastive learning in the federated setting through the lens of SimCLR and multi-view mutual information maximization. In doing so, we uncover a connection between contrastive representation learning and user verification; by adding a user verification loss to each client's local SimCLR loss we recover a lower bound to the global multi-view mutual information. To accommodate for the case of when some labelled data are available at the clients, we extend our SimCLR variant to the federated semi-supervised setting. We see that a supervised SimCLR objective can be obtained with two changes: a) the contrastive loss is computed between datapoints that share the same label and b) we require an additional auxiliary head that predicts the correct labels from either of the two views. Along with the proposed SimCLR extensions, we also study how different sources of non-i.i.d.-ness can impact the performance of federated unsupervised learning through global mutual information maximization; we find that a global objective is beneficial for some sources of non-i.i.d.-ness but can be detrimental for others. We empirically evaluate our proposed extensions in various tasks to validate our claims and furthermore demonstrate that our proposed modifications generalize to other pretraining methods.
Read more5/6/2024