A Contrastive Symmetric Forward-Forward Algorithm (SFFA) for Continual Learning Tasks

0

Sign in to get full access
Overview
- This paper proposes a new continual learning algorithm called the Symmetric Forward-Forward Algorithm (SFFA).
- The SFFA aims to improve the performance of neural networks on sequential learning tasks by leveraging a contrastive symmetric forward-forward training process.
- The authors compare the SFFA to other continual learning approaches and demonstrate its effectiveness on several benchmark datasets.
Plain English Explanation
The paper introduces a new machine learning technique called the Symmetric Forward-Forward Algorithm (SFFA) that can help neural networks learn better when faced with a series of different tasks over time. This is known as continual learning.
The key idea behind the SFFA is to train the neural network to not just learn the current task, but also remember and contrast what it has learned before. This is done by having the network make two predictions for each input - one based on its current knowledge, and one based on what it remembers from the past.
By encouraging the network to keep these two predictions symmetric (similar), the SFFA helps the network maintain a stable internal representation as it learns new tasks. This can lead to better generalization and performance compared to other continual learning methods that don't explicitly focus on preserving the network's knowledge over time.
The authors show that the SFFA outperforms several existing continual learning algorithms on a variety of benchmark datasets. This suggests the SFFA is a promising approach for building machine learning systems that can continuously learn and adapt to new information without forgetting what they've learned before.
Technical Explanation
The paper proposes a new continual learning algorithm called the Symmetric Forward-Forward Algorithm (SFFA). The key elements of the SFFA are:
-
Symmetric Forward-Forward Training: During training, the network makes two forward passes for each input - one based on its current knowledge, and one based on its remembered past knowledge. A contrastive loss is used to encourage these two predictions to be similar, helping the network maintain a stable internal representation.
-
Incremental Representation Learning: The SFFA uses a shared representation across all tasks, which is incrementally updated as new tasks are learned. This allows the network to reuse knowledge from previous tasks, improving sample efficiency and performance.
-
Task-Conditioned Prediction Heads: The network has separate prediction heads for each task, which are conditioned on a task-specific input. This allows the network to make task-specific predictions while still sharing a common representation.
The authors evaluate the SFFA on several benchmark continual learning datasets, including permuted MNIST, split CIFAR-100, and the Avalanche benchmark. They show that the SFFA outperforms several state-of-the-art continual learning algorithms, demonstrating its effectiveness at mitigating catastrophic forgetting and improving generalization on sequential learning tasks.
Critical Analysis
The paper provides a thorough evaluation of the SFFA algorithm, including comparisons to a wide range of existing continual learning methods. The authors acknowledge some potential limitations, such as the need for task identities during inference and the computational overhead of the two forward passes.
One area for further research could be exploring ways to reduce the computational cost of the SFFA, perhaps through more efficient implementation or architectural choices. Additionally, it would be interesting to see how the SFFA performs on more complex or real-world continual learning scenarios, beyond the benchmark datasets used in this study.
Overall, the SFFA represents a promising approach to continual learning, with the authors presenting a well-designed algorithm and a comprehensive experimental evaluation. The focus on preserving the network's internal representation through a contrastive symmetric training process is a novel and insightful contribution to the field.
Conclusion
This paper introduces the Symmetric Forward-Forward Algorithm (SFFA), a new continual learning algorithm that leverages a contrastive symmetric forward-forward training process to improve the performance of neural networks on sequential learning tasks. The SFFA outperforms several state-of-the-art continual learning methods on benchmark datasets, suggesting it is a valuable addition to the continual learning toolbox.
The SFFA's ability to maintain a stable internal representation while learning new tasks is a key strength, and the authors provide a thorough technical explanation and evaluation of the algorithm. While the method has some computational overhead, the promising results indicate that the SFFA is a compelling approach for building machine learning systems that can continuously adapt and learn without forgetting.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Contrastive Symmetric Forward-Forward Algorithm (SFFA) for Continual Learning Tasks
Erik B. Terres-Escudero, Javier Del Ser, Pablo Garcia Bringas
The so-called Forward-Forward Algorithm (FFA) has recently gained momentum as an alternative to the conventional back-propagation algorithm for neural network learning, yielding competitive performance across various modeling tasks. By replacing the backward pass of gradient back-propagation with two contrastive forward passes, the FFA avoids several shortcomings undergone by its predecessor (e.g., vanishing/exploding gradient) by enabling layer-wise training heuristics. In classification tasks, this contrastive method has been proven to effectively create a latent sparse representation of the input data, ultimately favoring discriminability. However, FFA exhibits an inherent asymmetric gradient behavior due to an imbalanced loss function between positive and negative data, adversely impacting on the model's generalization capabilities and leading to an accuracy degradation. To address this issue, this work proposes the Symmetric Forward-Forward Algorithm (SFFA), a novel modification of the original FFA which partitions each layer into positive and negative neurons. This allows the local fitness function to be defined as the ratio between the activation of positive neurons and the overall layer activity, resulting in a symmetric loss landscape during the training phase. To evaluate the enhanced convergence of our method, we conduct several experiments using multiple image classification benchmarks, comparing the accuracy of models trained with SFFA to those trained with its FFA counterpart. As a byproduct of this reformulation, we explore the advantages of using a layer-wise training algorithm for Continual Learning (CL) tasks. The specialization of neurons and the sparsity of their activations induced by layer-wise training algorithms enable efficient CL strategies that incorporate new knowledge (classes) into the neural network, while preventing catastrophic forgetting of previously...
Read more9/12/2024

0
On the Improvement of Generalization and Stability of Forward-Only Learning via Neural Polarization
Erik B. Terres-Escudero, Javier Del Ser, Pablo Garcia-Bringas
Forward-only learning algorithms have recently gained attention as alternatives to gradient backpropagation, replacing the backward step of this latter solver with an additional contrastive forward pass. Among these approaches, the so-called Forward-Forward Algorithm (FFA) has been shown to achieve competitive levels of performance in terms of generalization and complexity. Networks trained using FFA learn to contrastively maximize a layer-wise defined goodness score when presented with real data (denoted as positive samples) and to minimize it when processing synthetic data (corr. negative samples). However, this algorithm still faces weaknesses that negatively affect the model accuracy and training stability, primarily due to a gradient imbalance between positive and negative samples. To overcome this issue, in this work we propose a novel implementation of the FFA algorithm, denoted as Polar-FFA, which extends the original formulation by introducing a neural division (emph{polarization}) between positive and negative instances. Neurons in each of these groups aim to maximize their goodness when presented with their respective data type, thereby creating a symmetric gradient behavior. To empirically gauge the improved learning capabilities of our proposed Polar-FFA, we perform several systematic experiments using different activation and goodness functions over image classification datasets. Our results demonstrate that Polar-FFA outperforms FFA in terms of accuracy and convergence speed. Furthermore, its lower reliance on hyperparameters reduces the need for hyperparameter tuning to guarantee optimal generalization capabilities, thereby allowing for a broader range of neural network configurations.
Read more9/12/2024

0
Emerging NeoHebbian Dynamics in Forward-Forward Learning: Implications for Neuromorphic Computing
Erik B. Terres-Escudero, Javier Del Ser, Pablo Garc'ia-Bringas
Advances in neural computation have predominantly relied on the gradient backpropagation algorithm (BP). However, the recent shift towards non-stationary data modeling has highlighted the limitations of this heuristic, exposing that its adaptation capabilities are far from those seen in biological brains. Unlike BP, where weight updates are computed through a reverse error propagation path, Hebbian learning dynamics provide synaptic updates using only information within the layer itself. This has spurred interest in biologically plausible learning algorithms, hypothesized to overcome BP's shortcomings. In this context, Hinton recently introduced the Forward-Forward Algorithm (FFA), which employs local learning rules for each layer and has empirically proven its efficacy in multiple data modeling tasks. In this work we argue that when employing a squared Euclidean norm as a goodness function driving the local learning, the resulting FFA is equivalent to a neo-Hebbian Learning Rule. To verify this result, we compare the training behavior of FFA in analog networks with its Hebbian adaptation in spiking neural networks. Our experiments demonstrate that both versions of FFA produce similar accuracy and latent distributions. The findings herein reported provide empirical evidence linking biological learning rules with currently used training algorithms, thus paving the way towards extrapolating the positive outcomes from FFA to Hebbian learning rules. Simultaneously, our results imply that analog networks trained under FFA could be directly applied to neuromorphic computing, leading to reduced energy usage and increased computational speed.
Read more6/26/2024
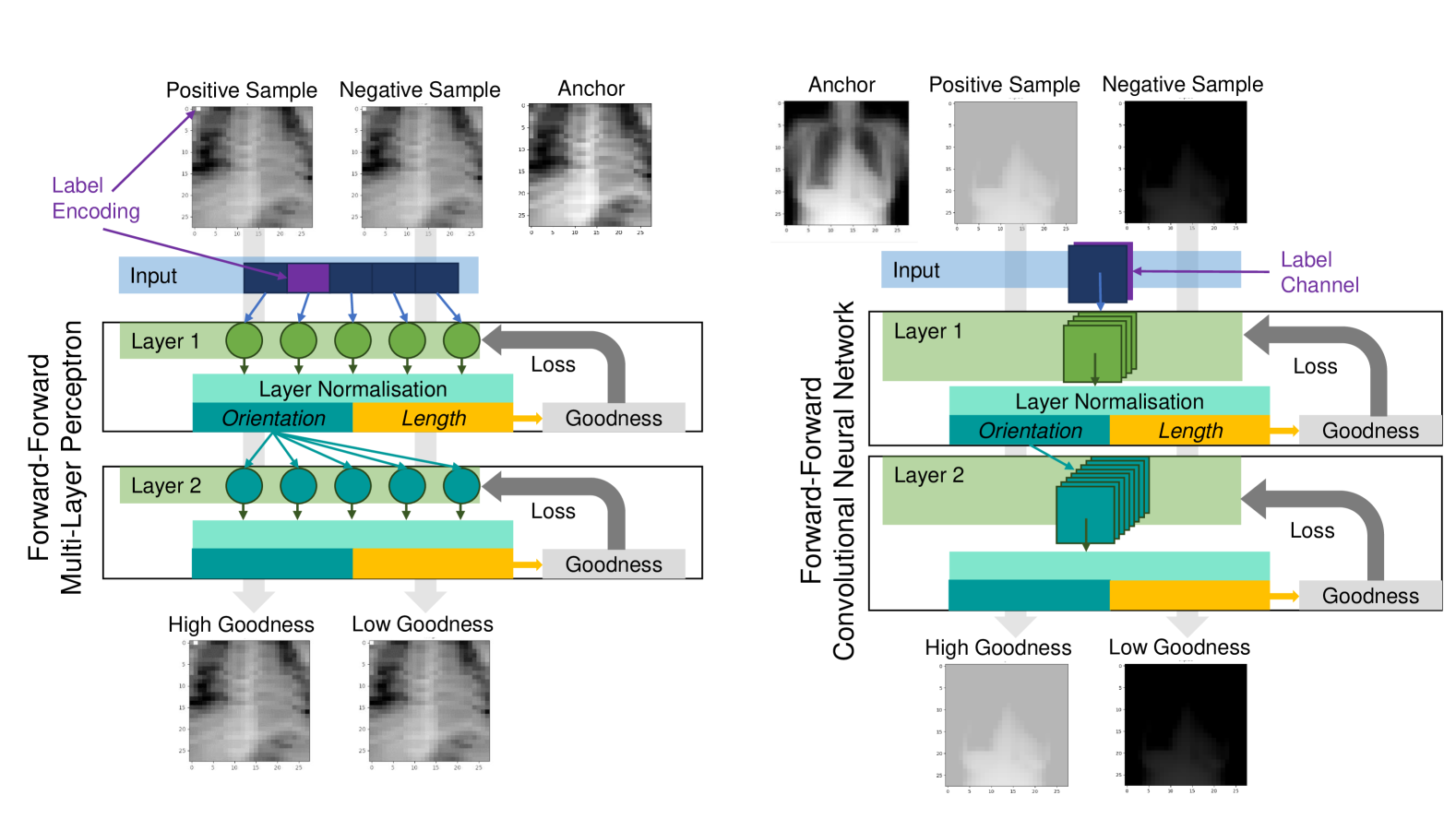
0
Resource-efficient Medical Image Analysis with Self-adapting Forward-Forward Networks
Johanna P. Muller, Bernhard Kainz
We introduce a fast Self-adapting Forward-Forward Network (SaFF-Net) for medical imaging analysis, mitigating power consumption and resource limitations, which currently primarily stem from the prevalent reliance on back-propagation for model training and fine-tuning. Building upon the recently proposed Forward-Forward Algorithm (FFA), we introduce the Convolutional Forward-Forward Algorithm (CFFA), a parameter-efficient reformulation that is suitable for advanced image analysis and overcomes the speed and generalisation constraints of the original FFA. To address hyper-parameter sensitivity of FFAs we are also introducing a self-adapting framework SaFF-Net fine-tuning parameters during warmup and training in parallel. Our approach enables more effective model training and eliminates the previously essential requirement for an arbitrarily chosen Goodness function in FFA. We evaluate our approach on several benchmarking datasets in comparison with standard Back-Propagation (BP) neural networks showing that FFA-based networks with notably fewer parameters and function evaluations can compete with standard models, especially, in one-shot scenarios and large batch sizes. The code will be available at the time of the conference.
Read more7/18/2024