Controllable Human-Object Interaction Synthesis

0
🌀
Sign in to get full access
Overview
- This paper addresses the challenge of generating synchronized object motion and human motion guided by language descriptions in 3D scenes.
- The authors propose a method called Controllable Human-Object Interaction Synthesis (CHOIS) that uses a conditional diffusion model to generate both object and human motion simultaneously based on language descriptions, initial states, and sparse object waypoints.
- The key innovations include an object geometry loss to improve alignment with waypoints and guidance terms to enforce contact constraints during the diffusion process.
- The method can be integrated with a path planning module to enable the generation of long-term human-object interactions in 3D environments.
Plain English Explanation
The paper focuses on a critical problem in simulating realistic human behaviors: generating synchronized object motion and human motion guided by language descriptions in 3D scenes. The authors present an approach called Controllable Human-Object Interaction Synthesis (CHOIS) that can generate these interactions using a conditional diffusion model.
The key idea is to use language descriptions to inform the style and intent of the interaction, while also using sparse object waypoints to ground the motion in the 3D scene. This allows the system to generate realistic human-object interactions that follow the provided instructions and constraints.
One challenge the authors address is that a naive diffusion model fails to accurately align the generated object motion with the input waypoints. To overcome this, they introduce an object geometry loss to better match the generated motion to the waypoints. They also design guidance terms to enforce realistic contact constraints during the diffusion process, ensuring the human and objects interact in a natural way.
The resulting system can synthesize realistic human-object interactions that adhere to the provided language descriptions and waypoint conditions. Furthermore, the authors show that their module can be seamlessly integrated with a path planning system, enabling the generation of long-term interactions in complex 3D environments.
Technical Explanation
The Controllable Human-Object Interaction Synthesis (CHOIS) approach uses a conditional diffusion model to generate synchronized object motion and human motion based on language descriptions, initial states, and sparse object waypoints.
The authors first identify the key challenges in this task: a naive diffusion model fails to accurately align the generated object motion with input waypoints, and it cannot ensure the realism of interactions that require precise hand-object and human-floor contact.
To address these issues, CHOIS introduces two main innovations:
-
Object Geometry Loss: The authors add an object geometry loss as additional supervision to improve the matching between the generated object motion and the input object waypoints.
-
Guidance Terms: They design guidance terms to enforce contact constraints during the sampling process of the trained diffusion model, ensuring realistic human-object interactions.
The CHOIS architecture takes as input a language description, initial object and human states, and sparse object waypoints. It then uses a conditional diffusion model to generate the synchronized object and human motion. The object geometry loss and contact guidance terms are integrated into the diffusion process to improve the quality and realism of the generated interactions.
The authors demonstrate that their method can synthesize realistic human-object interactions that adhere to the provided textual descriptions and sparse waypoint conditions. Furthermore, they show that the CHOIS module can be seamlessly integrated with a path planning system, enabling the generation of long-term interactions in complex 3D environments.
Critical Analysis
The paper makes a significant contribution to the field of realistic human behavior simulation by addressing the challenging problem of generating synchronized object motion and human motion guided by language descriptions.
One potential limitation of the work is that it relies on sparse object waypoints, which may not always be available or easy to obtain. It would be interesting to see if the method could be extended to work with more general or high-level scene descriptions, without the need for explicit waypoint information.
Additionally, the paper does not provide a thorough analysis of the computational complexity or runtime performance of the CHOIS approach. As the method is intended for real-time applications, understanding the scalability and efficiency of the approach would be valuable.
While the authors demonstrate the integration of CHOIS with a path planning module, it would be useful to see more extensive evaluations of the system's ability to generate long-term, coherent interactions in complex 3D environments. Exploring the robustness of the method to changing conditions or unexpected events could also be an area for future research.
Overall, the CHOIS approach represents an important step forward in the field of human-object interaction synthesis, and the authors have made a compelling case for the significance of this work. Continued research and refinement of the method could lead to significant advancements in the simulation of realistic human behaviors.
Conclusion
The paper presents a novel approach called Controllable Human-Object Interaction Synthesis (CHOIS) that addresses the challenge of generating synchronized object motion and human motion guided by language descriptions in 3D scenes. The key innovations include an object geometry loss to improve alignment with waypoints and guidance terms to enforce contact constraints during the diffusion process.
The authors demonstrate that their method can synthesize realistic human-object interactions that adhere to the provided textual descriptions and sparse waypoint conditions. Furthermore, the CHOIS module can be seamlessly integrated with a path planning system, enabling the generation of long-term interactions in complex 3D environments.
This work represents an important step forward in the field of human behavior simulation, with potential applications in areas such as robotics, virtual reality, and film production. Continued research and refinement of the CHOIS approach could lead to even more realistic and controllable human-object interactions, further advancing the state of the art in this domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌀
0
Controllable Human-Object Interaction Synthesis
Jiaman Li, Alexander Clegg, Roozbeh Mottaghi, Jiajun Wu, Xavier Puig, C. Karen Liu
Synthesizing semantic-aware, long-horizon, human-object interaction is critical to simulate realistic human behaviors. In this work, we address the challenging problem of generating synchronized object motion and human motion guided by language descriptions in 3D scenes. We propose Controllable Human-Object Interaction Synthesis (CHOIS), an approach that generates object motion and human motion simultaneously using a conditional diffusion model given a language description, initial object and human states, and sparse object waypoints. Here, language descriptions inform style and intent, and waypoints, which can be effectively extracted from high-level planning, ground the motion in the scene. Naively applying a diffusion model fails to predict object motion aligned with the input waypoints; it also cannot ensure the realism of interactions that require precise hand-object and human-floor contact. To overcome these problems, we introduce an object geometry loss as additional supervision to improve the matching between generated object motion and input object waypoints; we also design guidance terms to enforce contact constraints during the sampling process of the trained diffusion model. We demonstrate that our learned interaction module can synthesize realistic human-object interactions, adhering to provided textual descriptions and sparse waypoint conditions. Additionally, our module seamlessly integrates with a path planning module, enabling the generation of long-term interactions in 3D environments.
Read more7/16/2024

0
Human-Object Interaction from Human-Level Instructions
Zhen Wu, Jiaman Li, C. Karen Liu
Intelligent agents need to autonomously navigate and interact within contextual environments to perform a wide range of daily tasks based on human-level instructions. These agents require a foundational understanding of the world, incorporating common sense and knowledge, to interpret such instructions. Moreover, they must possess precise low-level skills for movement and interaction to execute the detailed task plans derived from these instructions. In this work, we address the task of synthesizing continuous human-object interactions for manipulating large objects within contextual environments, guided by human-level instructions. Our goal is to generate synchronized object motion, full-body human motion, and detailed finger motion, all essential for realistic interactions. Our framework consists of a large language model (LLM) planning module and a low-level motion generator. We use LLMs to deduce spatial object relationships and devise a method for accurately determining their positions and orientations in target scene layouts. Additionally, the LLM planner outlines a detailed task plan specifying a sequence of sub-tasks. This task plan, along with the target object poses, serves as input for our low-level motion generator, which seamlessly alternates between navigation and interaction modules. We present the first complete system that can synthesize object motion, full-body motion, and finger motion simultaneously from human-level instructions. Our experiments demonstrate the effectiveness of our high-level planner in generating plausible target layouts and our low-level motion generator in synthesizing realistic interactions for diverse objects. Please refer to our project page for more results: https://hoifhli.github.io/.
Read more6/27/2024
🛸
0
InterControl: Zero-shot Human Interaction Generation by Controlling Every Joint
Zhenzhi Wang, Jingbo Wang, Yixuan Li, Dahua Lin, Bo Dai
Text-conditioned motion synthesis has made remarkable progress with the emergence of diffusion models. However, the majority of these motion diffusion models are primarily designed for a single character and overlook multi-human interactions. In our approach, we strive to explore this problem by synthesizing human motion with interactions for a group of characters of any size in a zero-shot manner. The key aspect of our approach is the adaptation of human-wise interactions as pairs of human joints that can be either in contact or separated by a desired distance. In contrast to existing methods that necessitate training motion generation models on multi-human motion datasets with a fixed number of characters, our approach inherently possesses the flexibility to model human interactions involving an arbitrary number of individuals, thereby transcending the limitations imposed by the training data. We introduce a novel controllable motion generation method, InterControl, to encourage the synthesized motions maintaining the desired distance between joint pairs. It consists of a motion controller and an inverse kinematics guidance module that realistically and accurately aligns the joints of synthesized characters to the desired location. Furthermore, we demonstrate that the distance between joint pairs for human-wise interactions can be generated using an off-the-shelf Large Language Model (LLM). Experimental results highlight the capability of our framework to generate interactions with multiple human characters and its potential to work with off-the-shelf physics-based character simulators.
Read more6/18/2024
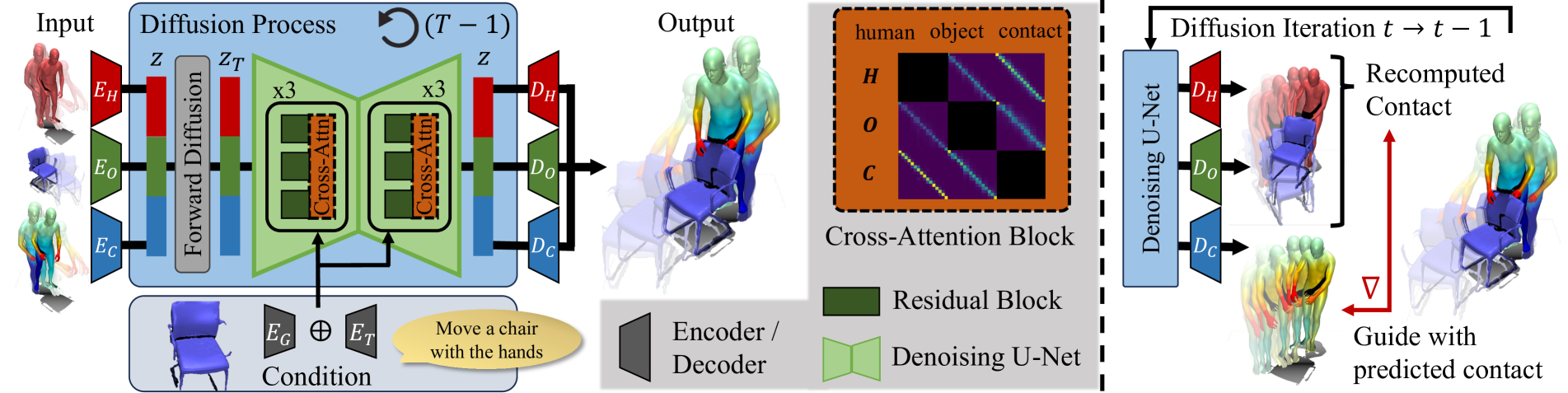
0
CG-HOI: Contact-Guided 3D Human-Object Interaction Generation
Christian Diller, Angela Dai
We propose CG-HOI, the first method to address the task of generating dynamic 3D human-object interactions (HOIs) from text. We model the motion of both human and object in an interdependent fashion, as semantically rich human motion rarely happens in isolation without any interactions. Our key insight is that explicitly modeling contact between the human body surface and object geometry can be used as strong proxy guidance, both during training and inference. Using this guidance to bridge human and object motion enables generating more realistic and physically plausible interaction sequences, where the human body and corresponding object move in a coherent manner. Our method first learns to model human motion, object motion, and contact in a joint diffusion process, inter-correlated through cross-attention. We then leverage this learned contact for guidance during inference to synthesize realistic and coherent HOIs. Extensive evaluation shows that our joint contact-based human-object interaction approach generates realistic and physically plausible sequences, and we show two applications highlighting the capabilities of our method. Conditioned on a given object trajectory, we can generate the corresponding human motion without re-training, demonstrating strong human-object interdependency learning. Our approach is also flexible, and can be applied to static real-world 3D scene scans.
Read more5/20/2024