Controllable Text Generation in the Instruction-Tuning Era
2405.01490
0
0
Abstract
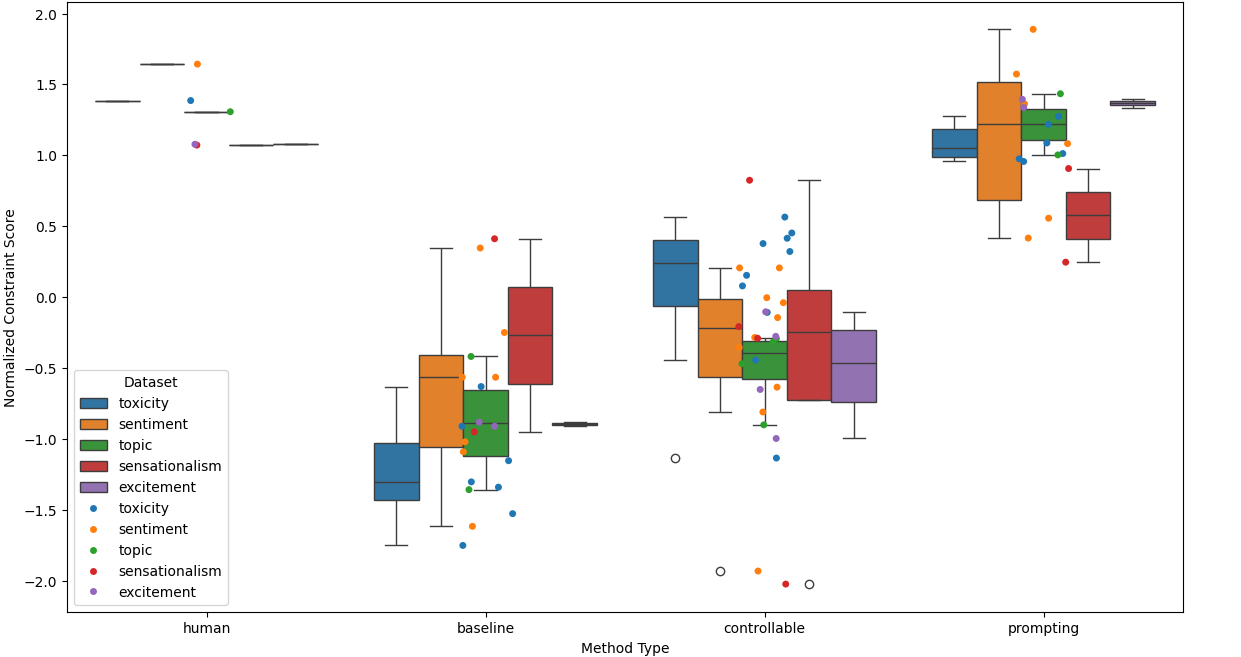
While most research on controllable text generation has focused on steering base Language Models, the emerging instruction-tuning and prompting paradigm offers an alternate approach to controllability. We compile and release ConGenBench, a testbed of 17 different controllable generation tasks, using a subset of it to benchmark the performance of 9 different baselines and methods on Instruction-tuned Language Models. To our surprise, we find that prompting-based approaches outperform controllable text generation methods on most datasets and tasks, highlighting a need for research on controllable text generation with Instruction-tuned Language Models in specific. Prompt-based approaches match human performance on most stylistic tasks while lagging on structural tasks, foregrounding a need to study more varied constraints and more challenging stylistic tasks. To facilitate such research, we provide an algorithm that uses only a task dataset and a Large Language Model with in-context capabilities to automatically generate a constraint dataset. This method eliminates the fields dependence on pre-curated constraint datasets, hence vastly expanding the range of constraints that can be studied in the future.
Create account to get full access
Overview
- This paper explores techniques for improving the controllability of text generation models, particularly in the context of the recent "instruction-tuning" approach to model training.
- The authors investigate methods for reducing the dependence of text generation on the initial prompt, allowing for greater control over the output.
- They propose several strategies, including using prompt engineering, prompt learning, and self-supervised learning, and evaluate their effectiveness on various text generation tasks.
Plain English Explanation
The paper focuses on making text generation models more controllable, which means being able to better direct the content and style of the text they produce. This is an important challenge as these models become more powerful and widely used.
The key idea is to reduce the influence of the initial prompt (the starting text provided to the model) on the final output. This would give users more control over the direction and characteristics of the generated text, rather than having the model's output heavily dependent on the prompt.
The researchers test several approaches to achieve this, including:
- Prompt Engineering: Carefully crafting the prompt to guide the model in the desired direction.
- Prompt Learning: Training the model to learn effective prompts for different tasks.
- Self-Supervised Learning: Having the model learn to generate text while also learning to control its own outputs.
By evaluating these techniques across various text generation tasks, the authors aim to make progress on the important challenge of improving the controllability of powerful text models.
Technical Explanation
The paper explores methods for increasing the controllability of text generation models, particularly in the context of the "instruction-tuning" training approach. Instruction-tuning involves training large language models on a diverse set of tasks specified through natural language instructions, rather than fine-tuning on specific datasets.
The authors investigate techniques to reduce the dependence of generated text on the initial prompt, which is a key challenge in achieving greater control over model outputs. They propose and evaluate several strategies:
- Prompt Engineering: Carefully designing the prompts used to guide the model, exploring factors like prompt length, structure, and content.
- Prompt Learning: Training the model to learn effective prompts for different generation tasks, instead of relying on manually crafted ones.
- Self-Supervised Learning: Incorporating self-supervised objectives that incentivize the model to learn to generate text while also learning to control its own outputs.
The authors evaluate these approaches on a range of text generation tasks, including story writing, summarization, and dialogue generation. They analyze the impact of these techniques on metrics like perplexity, diversity, and control over specific attributes of the generated text.
Critical Analysis
The paper presents a thoughtful exploration of techniques to improve the controllability of text generation models, an important challenge as these models become more capable and widely used. The authors' focus on reducing prompt dependence is a valuable direction, as it could lead to more user-directed text generation.
However, the paper does not address some potential limitations and areas for further research. For example, it does not discuss the scalability of these techniques, particularly for very large language models that may be more difficult to fine-tune. Additionally, the paper does not explore the potential for unintended biases or safety issues that could arise from increased control over text generation.
Further research could investigate the long-term implications of these techniques, as well as potential trade-offs between control and other desirable properties, such as creativity or authenticity. Exploring ways to maintain a balance between user control and model autonomy could also be a fruitful area for future work.
Conclusion
This paper presents several promising approaches for improving the controllability of text generation models, particularly in the context of the instruction-tuning paradigm. By reducing the dependence on initial prompts, the authors aim to give users more control over the content and characteristics of the generated text.
The proposed techniques, including prompt engineering, prompt learning, and self-supervised learning, show potential for enhancing control across various text generation tasks. As large language models become more powerful and ubiquitous, this research highlights the importance of developing methods to ensure these models can be directed and constrained according to users' needs and societal values.
While the paper does not address all potential limitations, it represents an important step forward in the ongoing effort to make text generation more controllable and aligned with human preferences. Further research in this area could have significant implications for the responsible development and deployment of advanced language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Plug and Play with Prompts: A Prompt Tuning Approach for Controlling Text Generation
Rohan Deepak Ajwani, Zining Zhu, Jonathan Rose, Frank Rudzicz
0
0
Transformer-based Large Language Models (LLMs) have shown exceptional language generation capabilities in response to text-based prompts. However, controlling the direction of generation via textual prompts has been challenging, especially with smaller models. In this work, we explore the use of Prompt Tuning to achieve controlled language generation. Generated text is steered using prompt embeddings, which are trained using a small language model, used as a discriminator. Moreover, we demonstrate that these prompt embeddings can be trained with a very small dataset, with as low as a few hundred training examples. Our method thus offers a data and parameter efficient solution towards controlling language model outputs. We carry out extensive evaluation on four datasets: SST-5 and Yelp (sentiment analysis), GYAFC (formality) and JIGSAW (toxic language). Finally, we demonstrate the efficacy of our method towards mitigating harmful, toxic, and biased text generated by language models.
4/9/2024

Fine-grained Controllable Text Generation through In-context Learning with Feedback
Sarubi Thillainathan, Alexander Koller
0
0
We present a method for rewriting an input sentence to match specific values of nontrivial linguistic features, such as dependency depth. In contrast to earlier work, our method uses in-context learning rather than finetuning, making it applicable in use cases where data is sparse. We show that our model performs accurate rewrites and matches the state of the art on rewriting sentences to a specified school grade level.
6/18/2024
📉
JsonTuning: Towards Generalizable, Robust, and Controllable Instruction Tuning
Chang Gao, Wenxuan Zhang, Guizhen Chen, Wai Lam
0
0
Instruction tuning has become an essential process for optimizing the performance of large language models (LLMs). However, current text-to-text instruction tuning methods, referred to as TextTuning, exhibit significant limitations in terms of generalization, robustness, and controllability, primarily due to the absence of explicit task structures. In this paper, we introduce JsonTuning, a novel structure-to-structure approach for instruction tuning. By utilizing the versatile and structured format of JSON to represent tasks, JsonTuning enhances generalization by enabling the model to comprehend essential task elements and their interrelations, improves robustness by reducing ambiguity, and increases controllability by providing explicit control over the output. We conduct a comprehensive comparative analysis between JsonTuning and TextTuning using various language models and evaluation benchmarks. Our experimental results demonstrate that JsonTuning consistently outperforms TextTuning across a range of applications, showing marked improvements in performance, robustness, and controllability. By addressing the inherent limitations of TextTuning, JsonTuning reveals significant potential for developing more effective and reliable LLMs capable of managing diverse scenarios.
5/27/2024

Genixer: Empowering Multimodal Large Language Models as a Powerful Data Generator
Henry Hengyuan Zhao, Pan Zhou, Mike Zheng Shou
0
0
Multimodal Large Language Models (MLLMs) demonstrate exceptional problem-solving capabilities, but there is limited research focusing on their ability to generate data by converting unlabeled images into visual instruction tuning data. To this end, this paper is the first to explore the potential of empowering MLLM to generate data rather than prompting GPT-4. We introduce Genixer, a holistic data generation pipeline consisting of four key steps: (i) instruction data collection, (ii) instruction template design, (iii) empowering MLLMs, and (iv) data generation and filtering. Additionally, we outline two modes of data generation: task-agnostic and task-specific, enabling controllable output. We demonstrate that a synthetic VQA-like dataset trained with LLaVA1.5 enhances performance on 10 out of 12 multimodal benchmarks. Additionally, the grounding MLLM Shikra, when trained with a REC-like synthetic dataset, shows improvements on 7 out of 8 REC datasets. Through experiments and synthetic data analysis, our findings are: (1) current MLLMs can serve as robust data generators without assistance from GPT-4V; (2) MLLMs trained with task-specific datasets can surpass GPT-4V in generating complex instruction tuning data; (3) synthetic datasets enhance performance across various multimodal benchmarks and help mitigate model hallucinations. The data, code, and models can be found at https://github.com/zhaohengyuan1/Genixer.
5/21/2024