Plug and Play with Prompts: A Prompt Tuning Approach for Controlling Text Generation
2404.05143
0
0
Abstract
Transformer-based Large Language Models (LLMs) have shown exceptional language generation capabilities in response to text-based prompts. However, controlling the direction of generation via textual prompts has been challenging, especially with smaller models. In this work, we explore the use of Prompt Tuning to achieve controlled language generation. Generated text is steered using prompt embeddings, which are trained using a small language model, used as a discriminator. Moreover, we demonstrate that these prompt embeddings can be trained with a very small dataset, with as low as a few hundred training examples. Our method thus offers a data and parameter efficient solution towards controlling language model outputs. We carry out extensive evaluation on four datasets: SST-5 and Yelp (sentiment analysis), GYAFC (formality) and JIGSAW (toxic language). Finally, we demonstrate the efficacy of our method towards mitigating harmful, toxic, and biased text generated by language models.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces a prompt tuning approach for controlling text generation in large language models.
- The method allows users to fine-tune the prompts used to generate text, rather than tuning the entire model.
- This "plug and play" approach provides more flexibility and control over the output compared to traditional fine-tuning.
Plain English Explanation
Large language models like GPT-3 can generate human-like text on a wide range of topics. However, it can be difficult to control the exact output of these models. The paper proposes a new technique called "prompt tuning" that gives users more control over the generated text.
Instead of fine-tuning the entire language model, the prompt tuning approach allows you to fine-tune just the input prompts. This acts like a "dial" that you can adjust to steer the model's output in the desired direction, without having to retrain the entire model.
For example, if you want the model to generate more positive or creative text, you can fine-tune the prompts to nudge the output in that direction. This "plug and play" approach is more flexible than traditional fine-tuning, as you don't need to retrain the whole model for each new task.
Convolutional Prompting Meets Language Models: Continual Learning and NeuroPROMPTS: An Adaptive Framework to Optimize Prompts for Text are related works that also explore ways to optimize prompts for language models.
Technical Explanation
The paper proposes a "prompt tuning" approach for controlling the output of large language models. Instead of fine-tuning the entire model, the method fine-tunes the input prompts used to generate text.
The authors start by training a base language model on a large corpus of text data. They then introduce a small "prompt encoder" module that sits between the input prompt and the language model. This prompt encoder can be fine-tuned on specific tasks or datasets, allowing the user to adjust the prompts to steer the model's output.
The experiments show that prompt tuning can outperform full model fine-tuning on a range of text generation tasks, including story completion, dialogue, and summarization. The method also requires fewer training examples and computational resources compared to fine-tuning the entire model.
The paper also introduces several techniques to improve the prompt tuning process, such as prompt ensembling and prompt augmentation. These methods help to make the prompts more robust and adaptable to different scenarios.
Critical Analysis
The prompt tuning approach presented in this paper is an interesting and promising technique for controlling the output of large language models. By focusing on fine-tuning the input prompts rather than the entire model, it provides a more flexible and efficient way to customize the text generation process.
One potential limitation is that the effectiveness of prompt tuning may depend on the quality and diversity of the initial prompt set. If the prompts are not well-designed or representative of the desired output, the fine-tuning process may not be able to steer the model effectively. The paper acknowledges this challenge and explores techniques like prompt ensembling and augmentation to address it.
Another area for further research could be exploring the interpretability and explainability of the prompt tuning process. Understanding how the prompt encoder module works and how it influences the language model's output could be valuable for building trust and transparency in these systems.
Overall, the prompt tuning approach showcased in this paper represents an important step forward in gaining more control and customization over large language models. As the field of text generation continues to evolve, techniques like this will be crucial for developing AI systems that can reliably and safely produce content tailored to specific needs and applications.
Conclusion
This paper introduces a "prompt tuning" approach that allows users to fine-tune the input prompts of large language models, rather than the entire model. This provides more flexibility and control over the generated text output compared to traditional fine-tuning techniques.
The experiments demonstrate that prompt tuning can outperform full model fine-tuning on a range of text generation tasks, while requiring fewer training examples and computational resources. The authors also explore techniques like prompt ensembling and augmentation to make the prompt tuning process more robust.
Overall, this work represents an important advancement in the field of text generation, paving the way for more customizable and controllable AI systems. As language models become more powerful and prevalent, methods like prompt tuning will be crucial for ensuring they can be reliably and safely applied to real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Controllable Text Generation in the Instruction-Tuning Era
Dhananjay Ashok, Barnabas Poczos
0
0
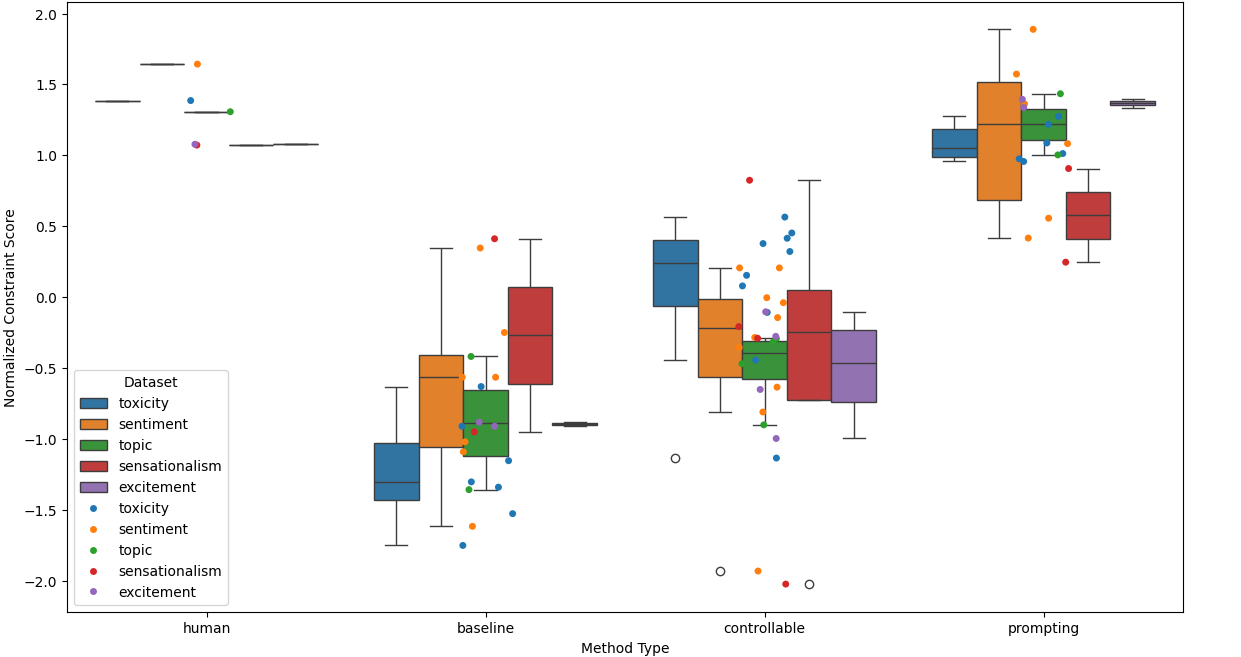
While most research on controllable text generation has focused on steering base Language Models, the emerging instruction-tuning and prompting paradigm offers an alternate approach to controllability. We compile and release ConGenBench, a testbed of 17 different controllable generation tasks, using a subset of it to benchmark the performance of 9 different baselines and methods on Instruction-tuned Language Models. To our surprise, we find that prompting-based approaches outperform controllable text generation methods on most datasets and tasks, highlighting a need for research on controllable text generation with Instruction-tuned Language Models in specific. Prompt-based approaches match human performance on most stylistic tasks while lagging on structural tasks, foregrounding a need to study more varied constraints and more challenging stylistic tasks. To facilitate such research, we provide an algorithm that uses only a task dataset and a Large Language Model with in-context capabilities to automatically generate a constraint dataset. This method eliminates the fields dependence on pre-curated constraint datasets, hence vastly expanding the range of constraints that can be studied in the future.
5/3/2024
🛠️
APrompt4EM: Augmented Prompt Tuning for Generalized Entity Matching
Yikuan Xia, Jiazun Chen, Xinchi Li, Jun Gao
0
0
Generalized Entity Matching (GEM), which aims at judging whether two records represented in different formats refer to the same real-world entity, is an essential task in data management. The prompt tuning paradigm for pre-trained language models (PLMs), including the recent PromptEM model, effectively addresses the challenges of low-resource GEM in practical applications, offering a robust solution when labeled data is scarce. However, existing prompt tuning models for GEM face the challenges of prompt design and information gap. This paper introduces an augmented prompt tuning framework for the challenges, which consists of two main improvements. The first is an augmented contextualized soft token-based prompt tuning method that extracts a guiding soft token benefit for the PLMs' prompt tuning, and the second is a cost-effective information augmentation strategy leveraging large language models (LLMs). Our approach performs well on the low-resource GEM challenges. Extensive experiments show promising advancements of our basic model without information augmentation over existing methods based on moderate-size PLMs (average 5.24%+), and our model with information augmentation achieves comparable performance compared with fine-tuned LLMs, using less than 14% of the API fee.
5/9/2024
📉
Can Better Text Semantics in Prompt Tuning Improve VLM Generalization?
Hari Chandana Kuchibhotla, Sai Srinivas Kancheti, Abbavaram Gowtham Reddy, Vineeth N Balasubramanian
0
0
Going beyond mere fine-tuning of vision-language models (VLMs), learnable prompt tuning has emerged as a promising, resource-efficient alternative. Despite their potential, effectively learning prompts faces the following challenges: (i) training in a low-shot scenario results in overfitting, limiting adaptability and yielding weaker performance on newer classes or datasets; (ii) prompt-tuning's efficacy heavily relies on the label space, with decreased performance in large class spaces, signaling potential gaps in bridging image and class concepts. In this work, we ask the question if better text semantics can help address these concerns. In particular, we introduce a prompt-tuning method that leverages class descriptions obtained from large language models (LLMs). Our approach constructs part-level description-guided views of both image and text features, which are subsequently aligned to learn more generalizable prompts. Our comprehensive experiments, conducted across 11 benchmark datasets, outperform established methods, demonstrating substantial improvements.
5/14/2024
Language Model Prompt Selection via Simulation Optimization
Haoting Zhang, Jinghai He, Rhonda Righter, Zeyu Zheng
0
0
With the advancement in generative language models, the selection of prompts has gained significant attention in recent years. A prompt is an instruction or description provided by the user, serving as a guide for the generative language model in content generation. Despite existing methods for prompt selection that are based on human labor, we consider facilitating this selection through simulation optimization, aiming to maximize a pre-defined score for the selected prompt. Specifically, we propose a two-stage framework. In the first stage, we determine a feasible set of prompts in sufficient numbers, where each prompt is represented by a moderate-dimensional vector. In the subsequent stage for evaluation and selection, we construct a surrogate model of the score regarding the moderate-dimensional vectors that represent the prompts. We propose sequentially selecting the prompt for evaluation based on this constructed surrogate model. We prove the consistency of the sequential evaluation procedure in our framework. We also conduct numerical experiments to demonstrate the efficacy of our proposed framework, providing practical instructions for implementation.
4/15/2024