Controlled Text Generation for Large Language Model with Dynamic Attribute Graphs
2402.11218
0
0
🛸
Abstract
Controlled Text Generation (CTG) aims to produce texts that exhibit specific desired attributes. In this study, we introduce a pluggable CTG framework for Large Language Models (LLMs) named Dynamic Attribute Graphs-based controlled text generation (DATG). This framework utilizes an attribute scorer to evaluate the attributes of sentences generated by LLMs and constructs dynamic attribute graphs. DATG modulates the occurrence of key attribute words and key anti-attribute words, achieving effective attribute control without compromising the original capabilities of the model. We conduct experiments across four datasets in two tasks: toxicity mitigation and sentiment transformation, employing five LLMs as foundational models. Our findings highlight a remarkable enhancement in control accuracy, achieving a peak improvement of 19.29% over baseline methods in the most favorable task across four datasets. Additionally, we observe a significant decrease in perplexity, markedly improving text fluency.
Create account to get full access
Overview
- This paper introduces a new framework called Dynamic Attribute Graphs-based controlled text generation (DATG) for producing text with specific desired attributes using large language models (LLMs).
- The framework uses an attribute scorer to evaluate the attributes of sentences generated by LLMs and constructs dynamic attribute graphs to modulate the occurrence of key attribute and anti-attribute words.
- The goal is to achieve effective attribute control without compromising the original capabilities of the language model.
Plain English Explanation
The researchers have developed a new system that allows you to generate text with specific desired qualities or "attributes" using large language models. The key idea is to use an evaluator to assess the attributes of the text generated by the language model, and then adjust the model's output to increase or decrease the presence of certain words related to those attributes.
For example, if you wanted to generate text that is less "toxic" or offensive, the system would identify the words in the generated text that are associated with toxicity, and then adjust the language model to use fewer of those words. This allows you to control the attributes of the generated text without fundamentally changing the model's underlying capabilities.
Technical Explanation
The researchers introduce the Dynamic Attribute Graphs-based controlled text generation (DATG) framework for achieving controlled text generation (CTG) using large language models (LLMs). DATG utilizes an attribute scorer to evaluate the attributes of sentences generated by the LLM, and then constructs dynamic attribute graphs to modulate the occurrence of key attribute words and key anti-attribute words.
This approach allows DATG to achieve effective attribute control without compromising the original capabilities of the language model. The researchers evaluate DATG across four datasets and two tasks: toxicity mitigation and sentiment transformation, using five different LLMs as the foundational models. Their results show a remarkable enhancement in control accuracy, with a peak improvement of 19.29% over baseline methods in the most favorable task across the four datasets. They also observe a significant decrease in perplexity, indicating improved text fluency.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the DATG framework, considering multiple tasks, datasets, and language models. The results demonstrate the effectiveness of the approach in achieving controlled text generation without degrading the underlying model's performance.
However, the paper does not delve deeply into the limitations or potential drawbacks of the DATG framework. For example, it would be interesting to understand how the framework scales to more complex or nuanced attributes, or how it might perform in real-world applications where the target attributes may be more contextual or subjective.
Additionally, the paper does not explore the potential ethical implications of using such a system, such as the risk of amplifying or perpetuating biases in the training data or language model. As with any text generation system, careful consideration of these issues is crucial.
Overall, the DATG framework represents an interesting and promising approach to controlled text generation, but further research is needed to fully understand its limitations and potential risks.
Conclusion
The researchers have developed a new framework called DATG that allows for effective control over the attributes of text generated by large language models. By using an attribute scorer and dynamic attribute graphs, DATG can modulate the presence of key attribute and anti-attribute words, improving control accuracy and text fluency without compromising the model's underlying capabilities.
This work represents an important step forward in the field of controlled text generation, with potential applications in areas like text generation for few-shot learning and citation generation through knowledge graphs. As the field of large language models continues to evolve, techniques like DATG will become increasingly valuable for ensuring the responsible and targeted use of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

GAugLLM: Improving Graph Contrastive Learning for Text-Attributed Graphs with Large Language Models
Yi Fang, Dongzhe Fan, Daochen Zha, Qiaoyu Tan
0
0
This work studies self-supervised graph learning for text-attributed graphs (TAGs) where nodes are represented by textual attributes. Unlike traditional graph contrastive methods that perturb the numerical feature space and alter the graph's topological structure, we aim to improve view generation through language supervision. This is driven by the prevalence of textual attributes in real applications, which complement graph structures with rich semantic information. However, this presents challenges because of two major reasons. First, text attributes often vary in length and quality, making it difficulty to perturb raw text descriptions without altering their original semantic meanings. Second, although text attributes complement graph structures, they are not inherently well-aligned. To bridge the gap, we introduce GAugLLM, a novel framework for augmenting TAGs. It leverages advanced large language models like Mistral to enhance self-supervised graph learning. Specifically, we introduce a mixture-of-prompt-expert technique to generate augmented node features. This approach adaptively maps multiple prompt experts, each of which modifies raw text attributes using prompt engineering, into numerical feature space. Additionally, we devise a collaborative edge modifier to leverage structural and textual commonalities, enhancing edge augmentation by examining or building connections between nodes. Empirical results across five benchmark datasets spanning various domains underscore our framework's ability to enhance the performance of leading contrastive methods as a plug-in tool. Notably, we observe that the augmented features and graph structure can also enhance the performance of standard generative methods, as well as popular graph neural networks. The open-sourced implementation of our GAugLLM is available at Github.
6/19/2024
🚀
DTGB: A Comprehensive Benchmark for Dynamic Text-Attributed Graphs
Jiasheng Zhang, Jialin Chen, Menglin Yang, Aosong Feng, Shuang Liang, Jie Shao, Rex Ying
0
0
Dynamic text-attributed graphs (DyTAGs) are prevalent in various real-world scenarios, where each node and edge are associated with text descriptions, and both the graph structure and text descriptions evolve over time. Despite their broad applicability, there is a notable scarcity of benchmark datasets tailored to DyTAGs, which hinders the potential advancement in many research fields. To address this gap, we introduce Dynamic Text-attributed Graph Benchmark (DTGB), a collection of large-scale, time-evolving graphs from diverse domains, with nodes and edges enriched by dynamically changing text attributes and categories. To facilitate the use of DTGB, we design standardized evaluation procedures based on four real-world use cases: future link prediction, destination node retrieval, edge classification, and textual relation generation. These tasks require models to understand both dynamic graph structures and natural language, highlighting the unique challenges posed by DyTAGs. Moreover, we conduct extensive benchmark experiments on DTGB, evaluating 7 popular dynamic graph learning algorithms and their variants of adapting to text attributes with LLM embeddings, along with 6 powerful large language models (LLMs). Our results show the limitations of existing models in handling DyTAGs. Our analysis also demonstrates the utility of DTGB in investigating the incorporation of structural and textual dynamics. The proposed DTGB fosters research on DyTAGs and their broad applications. It offers a comprehensive benchmark for evaluating and advancing models to handle the interplay between dynamic graph structures and natural language. The dataset and source code are available at https://github.com/zjs123/DTGB.
6/21/2024
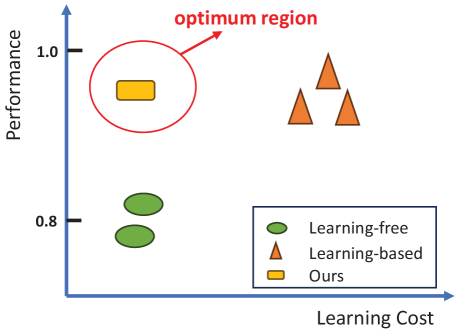
FreeCtrl: Constructing Control Centers with Feedforward Layers for Learning-Free Controllable Text Generation
Zijian Feng, Hanzhang Zhou, Zixiao Zhu, Kezhi Mao
0
0
Controllable text generation (CTG) seeks to craft texts adhering to specific attributes, traditionally employing learning-based techniques such as training, fine-tuning, or prefix-tuning with attribute-specific datasets. These approaches, while effective, demand extensive computational and data resources. In contrast, some proposed learning-free alternatives circumvent learning but often yield inferior results, exemplifying the fundamental machine learning trade-off between computational expense and model efficacy. To overcome these limitations, we propose FreeCtrl, a learning-free approach that dynamically adjusts the weights of selected feedforward neural network (FFN) vectors to steer the outputs of large language models (LLMs). FreeCtrl hinges on the principle that the weights of different FFN vectors influence the likelihood of different tokens appearing in the output. By identifying and adaptively adjusting the weights of attribute-related FFN vectors, FreeCtrl can control the output likelihood of attribute keywords in the generated content. Extensive experiments on single- and multi-attribute control reveal that the learning-free FreeCtrl outperforms other learning-free and learning-based methods, successfully resolving the dilemma between learning costs and model performance.
6/17/2024

Multi-Aspect Controllable Text Generation with Disentangled Counterfactual Augmentation
Yi Liu, Xiangyu Liu, Xiangrong Zhu, Wei Hu
0
0
Multi-aspect controllable text generation aims to control the generated texts in attributes from multiple aspects (e.g., positive from sentiment and sport from topic). For ease of obtaining training samples, existing works neglect attribute correlations formed by the intertwining of different attributes. Particularly, the stereotype formed by imbalanced attribute correlations significantly affects multi-aspect control. In this paper, we propose MAGIC, a new multi-aspect controllable text generation method with disentangled counterfactual augmentation. We alleviate the issue of imbalanced attribute correlations during training using counterfactual feature vectors in the attribute latent space by disentanglement. During inference, we enhance attribute correlations by target-guided counterfactual augmentation to further improve multi-aspect control. Experiments show that MAGIC outperforms state-of-the-art baselines in both imbalanced and balanced attribute correlation scenarios. Our source code and data are available at https://github.com/nju-websoft/MAGIC.
5/31/2024