Convert and Speak: Zero-shot Accent Conversion with Minimum Supervision

0
Sign in to get full access
Overview
- The paper proposes a zero-shot accent conversion model that can convert speech from one accent to another with minimal supervision.
- The model leverages a generative architecture to transfer the accent features while preserving the speaker's identity and speech content.
- Experiments show the model can effectively convert speech across a variety of accents with high quality.
Plain English Explanation
The research paper describes a new machine learning model that can change the accent of someone's speech without needing a lot of training data. This is called "zero-shot accent conversion" - the model can convert speech to a new accent it hasn't been explicitly trained on before.
The key idea is to use a generative model that can take the original speech and convert it to a new accent, while still preserving the speaker's identity and the content of what they're saying. This allows the model to transfer just the accent features without changing other aspects of the speech.
The researchers tested the model on converting speech across a variety of accents, and found it could do so effectively and produce high-quality converted speech. This accent conversion technology could be useful for applications like language learning, speech synthesis, and multi-lingual voice assistants.
Technical Explanation
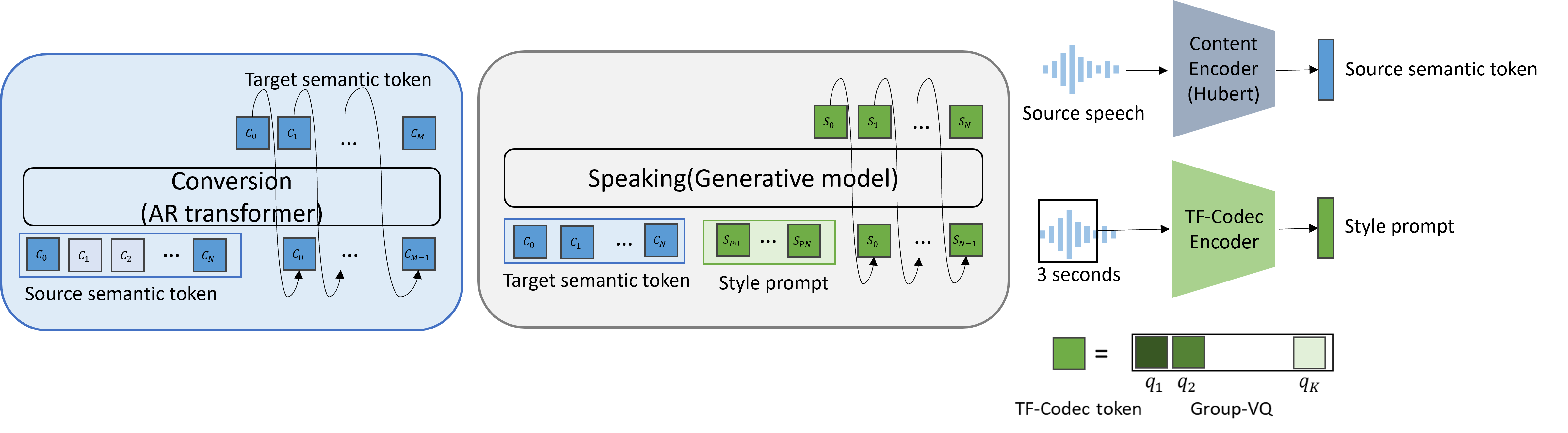
The paper proposes a [zero-shot accent conversion] model that can transform speech from one accent to another with minimal supervision. The key components are:
- Accent Encoder: This module encodes the accent features from the input speech, without capturing speaker identity or content.
- Speaker Encoder: This module extracts the speaker identity features from the input speech, preserving the speaker characteristics.
- Content Encoder: This module distills the speech content information, independent of accent or speaker.
- Accent Converter: This generative module combines the accent, speaker, and content features to synthesize the output speech in the target accent.
The model is trained on a dataset of multi-accent speech, but can then perform zero-shot conversion to accents not seen during training. Experiments demonstrate the model's ability to effectively convert speech across a variety of accents while maintaining high audio quality and preserving the original speaker identity and content.
Critical Analysis
The paper makes a compelling case for the proposed zero-shot accent conversion model, providing thorough experiments and quantitative results to support its effectiveness. However, a few caveats and limitations are worth noting:
- The training dataset, while multi-accent, may not capture the full diversity of global accents. Further evaluation on a broader range of accents would strengthen the claims of generalization.
- The model assumes the input and target accents are known a priori. In real-world applications, automatically detecting the input accent could be a challenging prerequisite.
- The paper does not address potential biases or fairness issues that could arise from accent conversion, such as perpetuating stereotypes or discrimination. This is an important consideration for real-world deployment.
- While the audio quality seems high, subjective evaluations of naturalness and preference compared to human speech or other TTS systems are not provided.
Overall, the research represents an interesting advance in accent conversion technology, but further exploration of edge cases, biases, and real-world applicability would strengthen the contribution.
Conclusion
This paper introduces a zero-shot accent conversion model that can transform speech from one accent to another with minimal supervision. The key innovation is a generative architecture that can transfer the accent features while preserving the speaker's identity and speech content.
Experiments demonstrate the model's effectiveness at converting speech across a variety of accents, producing high-quality audio output. This technology could have valuable applications in language learning, multilingual speech synthesis, and voice user interfaces, empowering users to communicate in their preferred accent.
While the research represents an interesting advance, further work is needed to address potential limitations around dataset diversity, accent detection, and ethical considerations. Overall, the paper highlights the potential for accent conversion to enable more natural and inclusive speech technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Convert and Speak: Zero-shot Accent Conversion with Minimum Supervision
Zhijun Jia, Huaying Xue, Xiulian Peng, Yan Lu
Low resource of parallel data is the key challenge of accent conversion(AC) problem in which both the pronunciation units and prosody pattern need to be converted. We propose a two-stage generative framework convert-and-speak in which the conversion is only operated on the semantic token level and the speech is synthesized conditioned on the converted semantic token with a speech generative model in target accent domain. The decoupling design enables the speaking module to use massive amount of target accent speech and relieves the parallel data required for the conversion module. Conversion with the bridge of semantic token also relieves the requirement for the data with text transcriptions and unlocks the usage of language pre-training technology to further efficiently reduce the need of parallel accent speech data. To reduce the complexity and latency of speaking, a single-stage AR generative model is designed to achieve good quality as well as lower computation cost. Experiments on Indian-English to general American-English conversion show that the proposed framework achieves state-of-the-art performance in accent similarity, speech quality, and speaker maintenance with only 15 minutes of weakly parallel data which is not constrained to the same speaker. Extensive experimentation with diverse accent types suggests that this framework possesses a high degree of adaptability, making it readily scalable to accommodate other accents with low-resource data. Audio samples are available at https://www.microsoft.com/en-us/research/project/convert-and-speak-zero-shot-accent-conversion-with-minimumsupervision/.
Read more8/23/2024
🛸
0
New!AccentBox: Towards High-Fidelity Zero-Shot Accent Generation
Jinzuomu Zhong, Korin Richmond, Zhiba Su, Siqi Sun
While recent Zero-Shot Text-to-Speech (ZS-TTS) models have achieved high naturalness and speaker similarity, they fall short in accent fidelity and control. To address this issue, we propose zero-shot accent generation that unifies Foreign Accent Conversion (FAC), accented TTS, and ZS-TTS, with a novel two-stage pipeline. In the first stage, we achieve state-of-the-art (SOTA) on Accent Identification (AID) with 0.56 f1 score on unseen speakers. In the second stage, we condition ZS-TTS system on the pretrained speaker-agnostic accent embeddings extracted by the AID model. The proposed system achieves higher accent fidelity on inherent/cross accent generation, and enables unseen accent generation.
Read more9/17/2024
📈
0
Non-autoregressive real-time Accent Conversion model with voice cloning
Vladimir Nechaev, Sergey Kosyakov
Currently, the development of Foreign Accent Conversion (FAC) models utilizes deep neural network architectures, as well as ensembles of neural networks for speech recognition and speech generation. The use of these models is limited by architectural features, which does not allow flexible changes in the timbre of the generated speech and requires the accumulation of context, leading to increased delays in generation and makes these systems unsuitable for use in real-time multi-user communication scenarios. We have developed the non-autoregressive model for real-time accent conversion with voice cloning. The model generates native-sounding L1 speech with minimal latency based on input L2 accented speech. The model consists of interconnected modules for extracting accent, gender, and speaker embeddings, converting speech, generating spectrograms, and decoding the resulting spectrogram into an audio signal. The model has the ability to save, clone and change the timbre, gender and accent of the speaker's voice in real time. The results of the objective assessment show that the model improves speech quality, leading to enhanced recognition performance in existing ASR systems. The results of subjective tests show that the proposed accent and gender encoder improves the generation quality. The developed model demonstrates high-quality low-latency accent conversion, voice cloning, and speech enhancement capabilities, making it suitable for real-time multi-user communication scenarios.
Read more5/24/2024
🗣️
0
New!MacST: Multi-Accent Speech Synthesis via Text Transliteration for Accent Conversion
Sho Inoue, Shuai Wang, Wanxing Wang, Pengcheng Zhu, Mengxiao Bi, Haizhou Li
In accented voice conversion or accent conversion, we seek to convert the accent in speech from one another while preserving speaker identity and semantic content. In this study, we formulate a novel method for creating multi-accented speech samples, thus pairs of accented speech samples by the same speaker, through text transliteration for training accent conversion systems. We begin by generating transliterated text with Large Language Models (LLMs), which is then fed into multilingual TTS models to synthesize accented English speech. As a reference system, we built a sequence-to-sequence model on the synthetic parallel corpus for accent conversion. We validated the proposed method for both native and non-native English speakers. Subjective and objective evaluations further validate our dataset's effectiveness in accent conversion studies.
Read more9/17/2024