Converting Anyone's Voice: End-to-End Expressive Voice Conversion with a Conditional Diffusion Model
2405.01730
0
0

Abstract
Expressive voice conversion (VC) conducts speaker identity conversion for emotional speakers by jointly converting speaker identity and emotional style. Emotional style modeling for arbitrary speakers in expressive VC has not been extensively explored. Previous approaches have relied on vocoders for speech reconstruction, which makes speech quality heavily dependent on the performance of vocoders. A major challenge of expressive VC lies in emotion prosody modeling. To address these challenges, this paper proposes a fully end-to-end expressive VC framework based on a conditional denoising diffusion probabilistic model (DDPM). We utilize speech units derived from self-supervised speech models as content conditioning, along with deep features extracted from speech emotion recognition and speaker verification systems to model emotional style and speaker identity. Objective and subjective evaluations show the effectiveness of our framework. Codes and samples are publicly available.
Create account to get full access
Overview
• This paper introduces an end-to-end expressive voice conversion system that can convert anyone's voice into a target speaker's voice while preserving the original speaker's emotional and prosodic expression.
• The key innovation is the use of a conditional diffusion model, which is a type of generative AI model, to perform the voice conversion task.
• The system is capable of converting a wide range of voice styles and emotions, making it a potentially powerful tool for applications like audio editing, voice cloning, and interactive voice experiences.
Plain English Explanation
This research paper describes a new way to change someone's voice to sound like a different person, while also keeping the original person's emotional tone and speaking style. The researchers used a type of machine learning model called a "conditional diffusion model" to achieve this.
Normally, voice conversion systems struggle to preserve the original speaker's expression and emotion when converting their voice. But this new approach allows the converted voice to still sound natural and authentic, with the same energy and feeling as the original.
This could be useful for many applications, like editing audio recordings, creating custom voice assistants, or even interactive experiences where a person's voice can be transformed on-the-fly. By being able to convert anyone's voice while keeping their characteristic style, this technology opens up new creative possibilities.
The key innovation is the use of a conditional diffusion model, which is a powerful type of AI system that can generate highly realistic audio. This allows the voice conversion to be done in an end-to-end fashion, without needing complex pre-processing steps.
Technical Explanation
The paper introduces an end-to-end expressive voice conversion system that can convert a source speaker's voice into a target speaker's voice, while preserving the original speaker's emotional and prosodic expression.
The core of the system is a conditional diffusion model, which is a type of generative AI model that can learn to transform a noisy input signal into a high-quality output. In this case, the input is the source speaker's audio, and the output is the converted voice in the target speaker's style.
The model is trained on a dataset of parallel speech recordings, where the same utterances are spoken by multiple speakers with different voice characteristics and emotional expressions. This allows the model to learn the mapping between source and target speaker voices, while also preserving the original speaker's expressive qualities.
Experiments show that the proposed system outperforms previous voice conversion and speech synthesis approaches in terms of speech quality, speaker similarity, and expression preservation. It can convert a wide range of voice styles and emotions, demonstrating its flexibility and versatility.
Critical Analysis
The paper presents a compelling approach to expressive voice conversion, but there are a few potential limitations and areas for further exploration:
-
The system was only evaluated on a relatively small dataset of parallel speech recordings. Its performance on more diverse, real-world speech data remains to be seen.
-
While the model can preserve the original speaker's emotional expression, it's unclear how much control the system allows over the target speaker's expressiveness. More flexibility in this area could be valuable for certain applications.
-
The computational cost and inference speed of the conditional diffusion model may limit its practicality for real-time voice conversion applications. Further optimizations may be needed.
-
The paper does not address potential ethical concerns around the misuse of voice cloning technology, such as for creating deepfakes. Thoughtful consideration of these issues would be important.
Overall, the proposed voice conversion system represents an exciting advance in expressive speech modeling, with promising applications in audio production, interactive experiences, and beyond. However, further research is needed to fully realize its potential and address its limitations.
Conclusion
This paper introduces an innovative end-to-end voice conversion system that can transform a source speaker's voice into a target speaker's voice while preserving the original speaker's emotional and prosodic expression. The key innovation is the use of a conditional diffusion model, which enables high-quality voice conversion in a single, integrated system.
The system's ability to convert a wide range of voice styles and emotions makes it a potentially powerful tool for various applications, such as audio editing, voice cloning, and interactive voice experiences. While the paper presents promising results, there are also some limitations and ethical considerations that warrant further exploration.
Overall, this research represents an important step forward in expressive speech modeling and voice conversion technology, with the potential to unlock new creative possibilities and enhance the way we interact with voice-based systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Learning Expressive Disentangled Speech Representations with Soft Speech Units and Adversarial Style Augmentation
Yimin Deng, Jianzong Wang, Xulong Zhang, Ning Cheng, Jing Xiao
0
0
Voice conversion is the task to transform voice characteristics of source speech while preserving content information. Nowadays, self-supervised representation learning models are increasingly utilized in content extraction. However, in these representations, a lot of hidden speaker information leads to timbre leakage while the prosodic information of hidden units lacks use. To address these issues, we propose a novel framework for expressive voice conversion called SAVC based on soft speech units from HuBert-soft. Taking soft speech units as input, we design an attribute encoder to extract content and prosody features respectively. Specifically, we first introduce statistic perturbation imposed by adversarial style augmentation to eliminate speaker information. Then the prosody is implicitly modeled on soft speech units with knowledge distillation. Experiment results show that the intelligibility and naturalness of converted speech outperform previous work.
5/2/2024
⛏️
SelfVC: Voice Conversion With Iterative Refinement using Self Transformations
Paarth Neekhara, Shehzeen Hussain, Rafael Valle, Boris Ginsburg, Rishabh Ranjan, Shlomo Dubnov, Farinaz Koushanfar, Julian McAuley
0
0
We propose SelfVC, a training strategy to iteratively improve a voice conversion model with self-synthesized examples. Previous efforts on voice conversion focus on factorizing speech into explicitly disentangled representations that separately encode speaker characteristics and linguistic content. However, disentangling speech representations to capture such attributes using task-specific loss terms can lead to information loss. In this work, instead of explicitly disentangling attributes with loss terms, we present a framework to train a controllable voice conversion model on entangled speech representations derived from self-supervised learning (SSL) and speaker verification models. First, we develop techniques to derive prosodic information from the audio signal and SSL representations to train predictive submodules in the synthesis model. Next, we propose a training strategy to iteratively improve the synthesis model for voice conversion, by creating a challenging training objective using self-synthesized examples. We demonstrate that incorporating such self-synthesized examples during training improves the speaker similarity of generated speech as compared to a baseline voice conversion model trained solely on heuristically perturbed inputs. Our framework is trained without any text and achieves state-of-the-art results in zero-shot voice conversion on metrics evaluating naturalness, speaker similarity, and intelligibility of synthesized audio.
5/6/2024
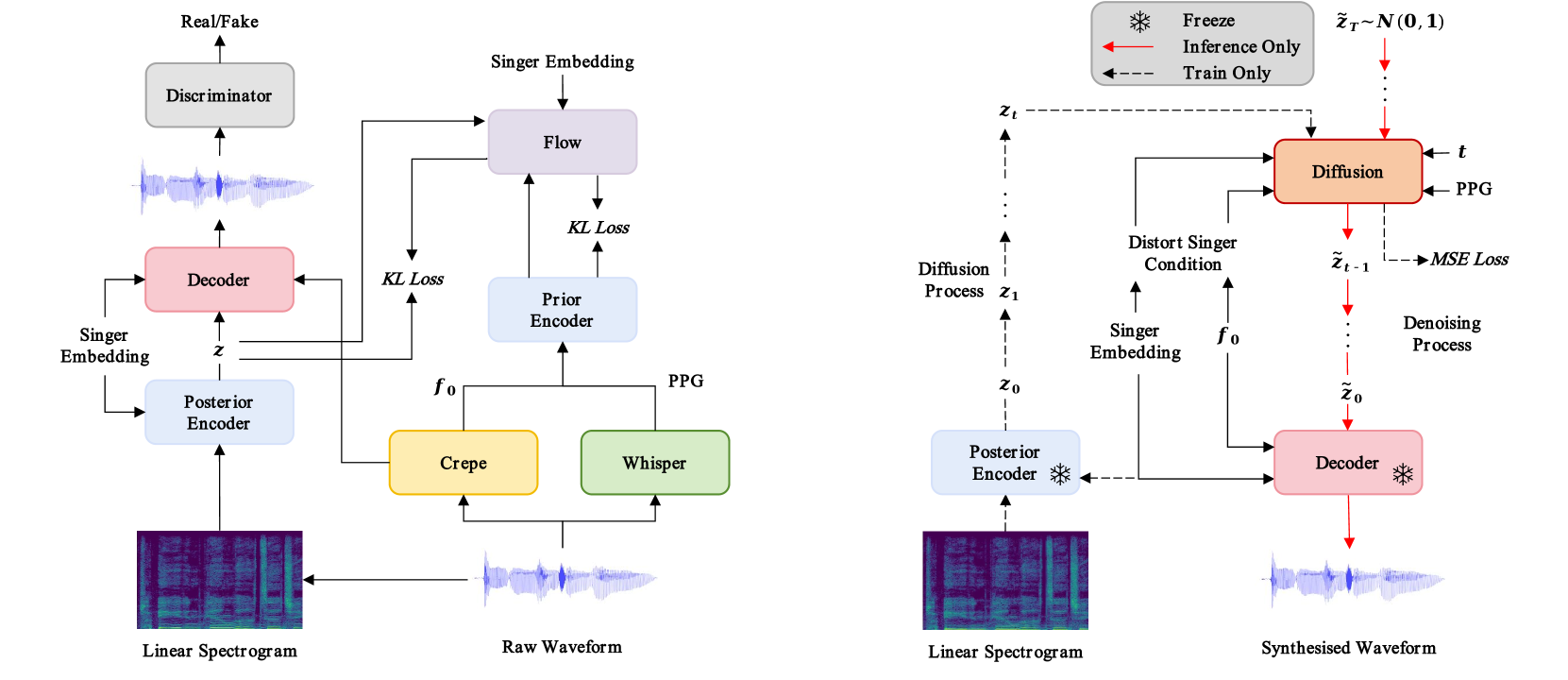
LDM-SVC: Latent Diffusion Model Based Zero-Shot Any-to-Any Singing Voice Conversion with Singer Guidance
Shihao Chen, Yu Gu, Jie Zhang, Na Li, Rilin Chen, Liping Chen, Lirong Dai
0
0
Any-to-any singing voice conversion (SVC) is an interesting audio editing technique, aiming to convert the singing voice of one singer into that of another, given only a few seconds of singing data. However, during the conversion process, the issue of timbre leakage is inevitable: the converted singing voice still sounds like the original singer's voice. To tackle this, we propose a latent diffusion model for SVC (LDM-SVC) in this work, which attempts to perform SVC in the latent space using an LDM. We pretrain a variational autoencoder structure using the noted open-source So-VITS-SVC project based on the VITS framework, which is then used for the LDM training. Besides, we propose a singer guidance training method based on classifier-free guidance to further suppress the timbre of the original singer. Experimental results show the superiority of the proposed method over previous works in both subjective and objective evaluations of timbre similarity.
6/11/2024

Who is Authentic Speaker
Qiang Huang
0
0
Voice conversion (VC) using deep learning technologies can now generate high quality one-to-many voices and thus has been used in some practical application fields, such as entertainment and healthcare. However, voice conversion can pose potential social issues when manipulated voices are employed for deceptive purposes. Moreover, it is a big challenge to find who are real speakers from the converted voices as the acoustic characteristics of source speakers are changed greatly. In this paper we attempt to explore the feasibility of identifying authentic speakers from converted voices. This study is conducted with the assumption that certain information from the source speakers persists, even when their voices undergo conversion into different target voices. Therefore our experiments are geared towards recognising the source speakers given the converted voices, which are generated by using FragmentVC on the randomly paired utterances from source and target speakers. To improve the robustness against converted voices, our recognition model is constructed by using hierarchical vector of locally aggregated descriptors (VLAD) in deep neural networks. The authentic speaker recognition system is mainly tested in two aspects, including the impact of quality of converted voices and the variations of VLAD. The dataset used in this work is VCTK corpus, where source and target speakers are randomly paired. The results obtained on the converted utterances show promising performances in recognising authentic speakers from converted voices.
5/2/2024