ViT-TTS: Visual Text-to-Speech with Scalable Diffusion Transformer
2305.12708
0
0
🌀
Abstract
Text-to-speech(TTS) has undergone remarkable improvements in performance, particularly with the advent of Denoising Diffusion Probabilistic Models (DDPMs). However, the perceived quality of audio depends not solely on its content, pitch, rhythm, and energy, but also on the physical environment. In this work, we propose ViT-TTS, the first visual TTS model with scalable diffusion transformers. ViT-TTS complement the phoneme sequence with the visual information to generate high-perceived audio, opening up new avenues for practical applications of AR and VR to allow a more immersive and realistic audio experience. To mitigate the data scarcity in learning visual acoustic information, we 1) introduce a self-supervised learning framework to enhance both the visual-text encoder and denoiser decoder; 2) leverage the diffusion transformer scalable in terms of parameters and capacity to learn visual scene information. Experimental results demonstrate that ViT-TTS achieves new state-of-the-art results, outperforming cascaded systems and other baselines regardless of the visibility of the scene. With low-resource data (1h, 2h, 5h), ViT-TTS achieves comparative results with rich-resource baselines.~footnote{Audio samples are available at url{https://ViT-TTS.github.io/.}}
Create account to get full access
Overview
- Text-to-speech (TTS) technology has seen significant improvements, particularly with the advent of Denoising Diffusion Probabilistic Models (DDPMs).
- However, the perceived quality of audio depends not only on its content, pitch, rhythm, and energy, but also on the physical environment.
- This work introduces ViT-TTS, the first visual TTS model with scalable diffusion transformers.
- ViT-TTS complements the phoneme sequence with visual information to generate high-perceived audio, enabling new applications in augmented reality (AR) and virtual reality (VR) for a more immersive and realistic audio experience.
- To address the data scarcity in learning visual acoustic information, the authors introduce a self-supervised learning framework and leverage scalable diffusion transformers to learn visual scene information.
Plain English Explanation
Text-to-speech (TTS) technology has come a long way in recent years, with the help of a machine learning technique called Denoising Diffusion Probabilistic Models (DDPMs). These models have made TTS sound much more natural and realistic.
However, the quality of the audio doesn't just depend on the content, pitch, rhythm, and energy of the speech. It also depends on the physical environment where the speech is taking place. For example, a person's voice might sound different in a small room compared to a large, open space.
The researchers in this study have developed a new TTS system called ViT-TTS that takes visual information into account, in addition to the speech itself. This allows the system to generate audio that sounds more realistic and tailored to the physical environment.
To do this, the researchers had to find a way to train the system effectively, even when there is limited data available on how visual information affects audio quality. They developed a self-supervised learning approach and used a type of machine learning model called a "diffusion transformer" that can handle large amounts of information.
The end result is a TTS system that can produce high-quality audio that feels more immersive and realistic, especially for applications in augmented reality (AR) and virtual reality (VR). This could lead to improvements in things like video conferencing, gaming, and other multimedia experiences.
Technical Explanation
The proposed ViT-TTS model is the first visual TTS system that leverages scalable diffusion transformers. It aims to complement the phoneme sequence with visual information to generate high-perceived audio, enabling new applications in AR and VR.
To address the data scarcity in learning visual acoustic information, the authors introduce a self-supervised learning framework. This framework enhances both the visual-text encoder and denoiser decoder. Additionally, the researchers leverage the scalable diffusion transformer architecture to learn visual scene information effectively.
The ViT-TTS model consists of two main components: a visual-text encoder and a denoiser decoder. The visual-text encoder takes the phoneme sequence and the corresponding visual scene as input, and produces a joint representation. The denoiser decoder then uses this representation to generate the final audio output.
The self-supervised learning framework involves two stages: pretraining and finetuning. In the pretraining stage, the visual-text encoder and denoiser decoder are trained on a large amount of unlabeled data using self-supervised objectives, such as prior-agnostic multi-scale contrastive text-audio and TANGO 2 alignment. In the finetuning stage, the pretrained model is further trained on the target TTS dataset, which may be smaller in size.
The authors evaluate ViT-TTS on the TAVGBENCH benchmark, which measures the perceived quality of the generated audio. The results show that ViT-TTS outperforms cascaded systems and other baselines, regardless of the visibility of the scene. Notably, with limited training data (1h, 2h, 5h), ViT-TTS achieves comparable results to rich-resource baselines.
Critical Analysis
The paper presents a promising approach to improving TTS systems by incorporating visual information, which is an important aspect of perceived audio quality that has been largely overlooked in the past. The authors' use of self-supervised learning and scalable diffusion transformers to address the data scarcity issue is a novel and compelling solution.
However, the paper does not delve into the potential limitations or drawbacks of the ViT-TTS system. For example, it would be helpful to understand the computational and memory requirements of the model, as well as any potential performance degradation when scaling to larger or more complex visual scenes.
Additionally, the paper could benefit from a deeper discussion of the specific applications and use cases that could benefit most from this technology. While the authors mention AR and VR, there may be other domains, such as improving language model-based zero-shot text generation, where the visual-audio integration could have a significant impact.
Overall, the ViT-TTS system represents an exciting advancement in TTS technology, and the authors' innovative approach to addressing data scarcity is a valuable contribution to the field. Further research and analysis of the system's limitations and broader applications would help to fully understand its potential impact.
Conclusion
The ViT-TTS model introduces a novel approach to text-to-speech generation by incorporating visual information alongside the phoneme sequence. This allows the system to generate high-quality, perceived audio that is tailored to the physical environment, opening up new possibilities for immersive experiences in AR, VR, and other multimedia applications.
The key innovations of this work include the use of a self-supervised learning framework to address data scarcity, as well as the leveraging of scalable diffusion transformers to effectively learn visual scene information. The results demonstrate the superiority of ViT-TTS over existing cascaded systems and baselines, even with limited training data.
As TTS technology continues to advance, the integration of visual information, as showcased by ViT-TTS, represents an important step towards creating more natural and realistic audio experiences that seamlessly blend with the user's environment. This work has the potential to significantly impact the development of next-generation multimedia and interactive technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

DiTTo-TTS: Efficient and Scalable Zero-Shot Text-to-Speech with Diffusion Transformer
Keon Lee, Dong Won Kim, Jaehyeon Kim, Jaewoong Cho
0
0
Large-scale diffusion models have shown outstanding generative abilities across multiple modalities including images, videos, and audio. However, text-to-speech (TTS) systems typically involve domain-specific modeling factors (e.g., phonemes and phoneme-level durations) to ensure precise temporal alignments between text and speech, which hinders the efficiency and scalability of diffusion models for TTS. In this work, we present an efficient and scalable Diffusion Transformer (DiT) that utilizes off-the-shelf pre-trained text and speech encoders. Our approach addresses the challenge of text-speech alignment via cross-attention mechanisms with the prediction of the total length of speech representations. To achieve this, we enhance the DiT architecture to suit TTS and improve the alignment by incorporating semantic guidance into the latent space of speech. We scale the training dataset and the model size to 82K hours and 790M parameters, respectively. Our extensive experiments demonstrate that the large-scale diffusion model for TTS without domain-specific modeling not only simplifies the training pipeline but also yields superior or comparable zero-shot performance to state-of-the-art TTS models in terms of naturalness, intelligibility, and speaker similarity. Our speech samples are available at https://ditto-tts.github.io.
6/18/2024
Visual Echoes: A Simple Unified Transformer for Audio-Visual Generation
Shiqi Yang, Zhi Zhong, Mengjie Zhao, Shusuke Takahashi, Masato Ishii, Takashi Shibuya, Yuki Mitsufuji
0
0
In recent years, with the realistic generation results and a wide range of personalized applications, diffusion-based generative models gain huge attention in both visual and audio generation areas. Compared to the considerable advancements of text2image or text2audio generation, research in audio2visual or visual2audio generation has been relatively slow. The recent audio-visual generation methods usually resort to huge large language model or composable diffusion models. Instead of designing another giant model for audio-visual generation, in this paper we take a step back showing a simple and lightweight generative transformer, which is not fully investigated in multi-modal generation, can achieve excellent results on image2audio generation. The transformer operates in the discrete audio and visual Vector-Quantized GAN space, and is trained in the mask denoising manner. After training, the classifier-free guidance could be deployed off-the-shelf achieving better performance, without any extra training or modification. Since the transformer model is modality symmetrical, it could also be directly deployed for audio2image generation and co-generation. In the experiments, we show that our simple method surpasses recent image2audio generation methods. Generated audio samples can be found at https://docs.google.com/presentation/d/1ZtC0SeblKkut4XJcRaDsSTuCRIXB3ypxmSi7HTY3IyQ/
5/27/2024
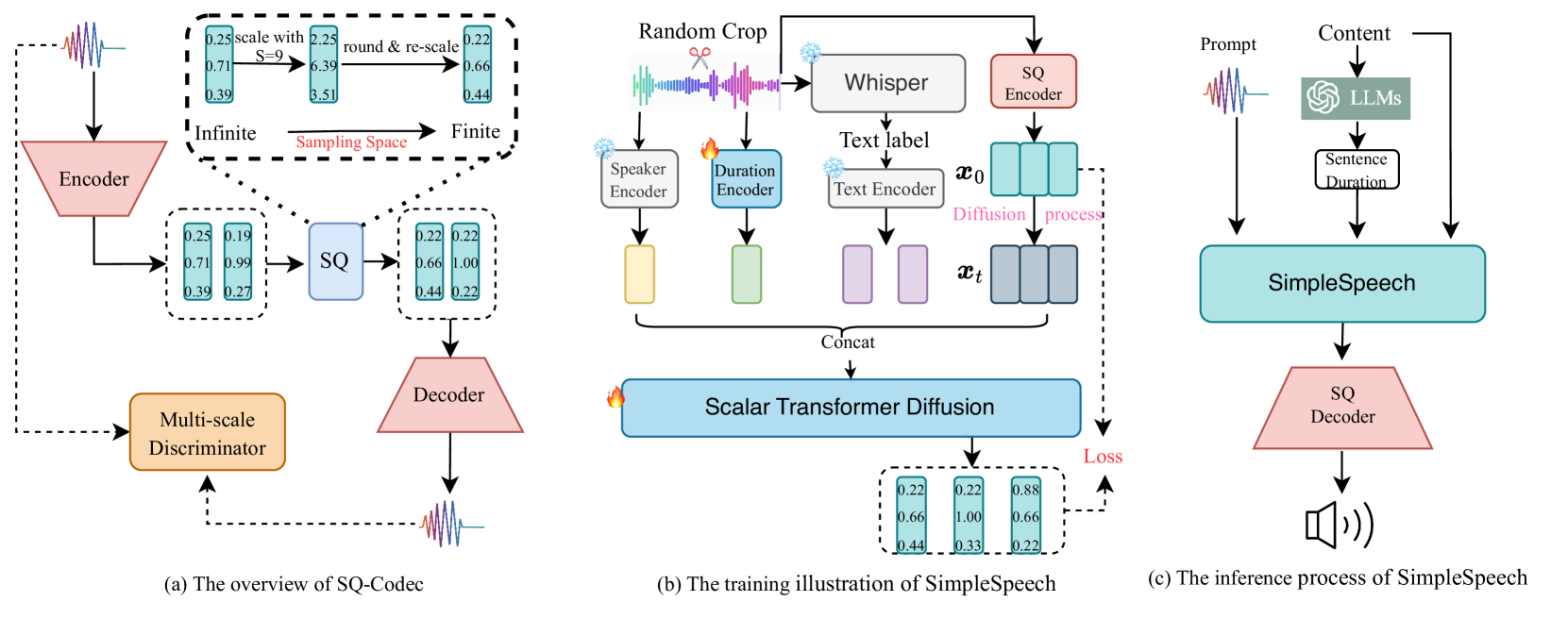
SimpleSpeech: Towards Simple and Efficient Text-to-Speech with Scalar Latent Transformer Diffusion Models
Dongchao Yang, Dingdong Wang, Haohan Guo, Xueyuan Chen, Xixin Wu, Helen Meng
0
0
In this study, we propose a simple and efficient Non-Autoregressive (NAR) text-to-speech (TTS) system based on diffusion, named SimpleSpeech. Its simpleness shows in three aspects: (1) It can be trained on the speech-only dataset, without any alignment information; (2) It directly takes plain text as input and generates speech through an NAR way; (3) It tries to model speech in a finite and compact latent space, which alleviates the modeling difficulty of diffusion. More specifically, we propose a novel speech codec model (SQ-Codec) with scalar quantization, SQ-Codec effectively maps the complex speech signal into a finite and compact latent space, named scalar latent space. Benefits from SQ-Codec, we apply a novel transformer diffusion model in the scalar latent space of SQ-Codec. We train SimpleSpeech on 4k hours of a speech-only dataset, it shows natural prosody and voice cloning ability. Compared with previous large-scale TTS models, it presents significant speech quality and generation speed improvement. Demos are released.
6/17/2024
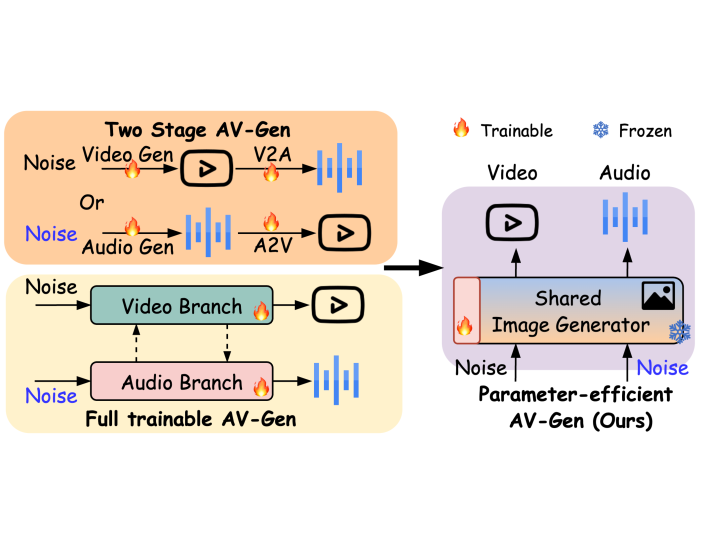
AV-DiT: Efficient Audio-Visual Diffusion Transformer for Joint Audio and Video Generation
Kai Wang, Shijian Deng, Jing Shi, Dimitrios Hatzinakos, Yapeng Tian
0
0
Recent Diffusion Transformers (DiTs) have shown impressive capabilities in generating high-quality single-modality content, including images, videos, and audio. However, it is still under-explored whether the transformer-based diffuser can efficiently denoise the Gaussian noises towards superb multimodal content creation. To bridge this gap, we introduce AV-DiT, a novel and efficient audio-visual diffusion transformer designed to generate high-quality, realistic videos with both visual and audio tracks. To minimize model complexity and computational costs, AV-DiT utilizes a shared DiT backbone pre-trained on image-only data, with only lightweight, newly inserted adapters being trainable. This shared backbone facilitates both audio and video generation. Specifically, the video branch incorporates a trainable temporal attention layer into a frozen pre-trained DiT block for temporal consistency. Additionally, a small number of trainable parameters adapt the image-based DiT block for audio generation. An extra shared DiT block, equipped with lightweight parameters, facilitates feature interaction between audio and visual modalities, ensuring alignment. Extensive experiments on the AIST++ and Landscape datasets demonstrate that AV-DiT achieves state-of-the-art performance in joint audio-visual generation with significantly fewer tunable parameters. Furthermore, our results highlight that a single shared image generative backbone with modality-specific adaptations is sufficient for constructing a joint audio-video generator. Our source code and pre-trained models will be released.
6/13/2024