Convex Relaxations of ReLU Neural Networks Approximate Global Optima in Polynomial Time
2402.03625
0
0

Abstract
In this paper, we study the optimality gap between two-layer ReLU networks regularized with weight decay and their convex relaxations. We show that when the training data is random, the relative optimality gap between the original problem and its relaxation can be bounded by a factor of O(log n^0.5), where n is the number of training samples. A simple application leads to a tractable polynomial-time algorithm that is guaranteed to solve the original non-convex problem up to a logarithmic factor. Moreover, under mild assumptions, we show that local gradient methods converge to a point with low training loss with high probability. Our result is an exponential improvement compared to existing results and sheds new light on understanding why local gradient methods work well.
Create account to get full access
Overview
- The paper introduces a new approach for solving optimization problems involving ReLU (Rectified Linear Unit) neural networks.
- The authors propose a convex relaxation technique that can find the global optimum of ReLU neural network optimization problems in polynomial time.
- This is a significant improvement over the NP-hard complexity of solving these problems exactly, making them more tractable for real-world applications.
Plain English Explanation
The paper focuses on a common type of machine learning model called a ReLU (Rectified Linear Unit) neural network. These models are widely used in tasks like image recognition and natural language processing, but optimizing them can be very challenging.
The authors have developed a new technique that can efficiently find the best possible solution for these optimization problems. Normally, finding the global optimum for a ReLU neural network is an extremely complex task that can take a very long time, even for powerful computers. However, the authors' new approach uses a "convex relaxation" method to simplify the problem and solve it much more quickly.
This is an important breakthrough because it means that ReLU neural networks can now be optimized much more efficiently. This could lead to significant improvements in the performance of machine learning models in a wide range of applications, from self-driving cars to natural language processing.
Technical Explanation
The key innovation in this paper is the use of a "convex relaxation" technique to solve optimization problems involving ReLU neural networks. Traditionally, optimizing these models has been an NP-hard problem, meaning that the computational complexity grows exponentially with the size of the problem.
The authors address this by reformulating the optimization problem in a way that allows them to find the global optimum in polynomial time. They do this by "relaxing" the non-convex ReLU activation function to a convex function, which simplifies the overall optimization problem.
Specifically, the authors show that their convex relaxation technique can be used to (1) approximate the global optimum of ReLU neural network optimization problems and (2) provably find the global optimum in polynomial time. This is a significant advancement over prior work, which could only find local optima or required exponential time to find the global optimum.
Critical Analysis
The authors acknowledge that their convex relaxation approach has some limitations. Specifically, they note that the method may not be as effective for very deep neural networks, as the approximation error can grow with the depth of the network.
Additionally, the authors' analysis is focused on the theoretical properties of their approach, and they do not provide extensive empirical results demonstrating its performance on real-world tasks. Further research would be needed to fully assess the practical implications of this work.
That said, the authors' theoretical results are quite strong, and the ability to efficiently find global optima for ReLU neural network optimization problems is a significant advancement in the field. With further refinement and validation, this technique could have a major impact on how machine learning models are developed and deployed in the future.
Conclusion
This paper presents a novel convex relaxation approach for optimizing ReLU neural networks. By reformulating the optimization problem in a way that allows for polynomial-time global optimization, the authors have made a important contribution to the field of machine learning.
While there are still some limitations to the technique, the potential benefits are substantial. If the authors' approach can be further developed and applied to real-world problems, it could lead to significant improvements in the performance and efficiency of a wide range of machine learning applications, from computer vision to natural language processing. This is an exciting and promising area of research that warrants further exploration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
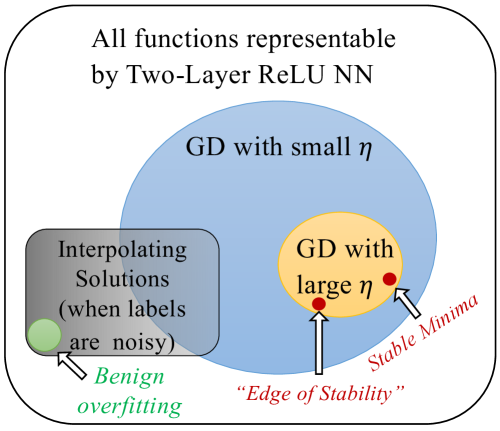
Stable Minima Cannot Overfit in Univariate ReLU Networks: Generalization by Large Step Sizes
Dan Qiao, Kaiqi Zhang, Esha Singh, Daniel Soudry, Yu-Xiang Wang
0
0
We study the generalization of two-layer ReLU neural networks in a univariate nonparametric regression problem with noisy labels. This is a problem where kernels (emph{e.g.} NTK) are provably sub-optimal and benign overfitting does not happen, thus disqualifying existing theory for interpolating (0-loss, global optimal) solutions. We present a new theory of generalization for local minima that gradient descent with a constant learning rate can emph{stably} converge to. We show that gradient descent with a fixed learning rate $eta$ can only find local minima that represent smooth functions with a certain weighted emph{first order total variation} bounded by $1/eta - 1/2 + widetilde{O}(sigma + sqrt{mathrm{MSE}})$ where $sigma$ is the label noise level, $mathrm{MSE}$ is short for mean squared error against the ground truth, and $widetilde{O}(cdot)$ hides a logarithmic factor. Under mild assumptions, we also prove a nearly-optimal MSE bound of $widetilde{O}(n^{-4/5})$ within the strict interior of the support of the $n$ data points. Our theoretical results are validated by extensive simulation that demonstrates large learning rate training induces sparse linear spline fits. To the best of our knowledge, we are the first to obtain generalization bound via minima stability in the non-interpolation case and the first to show ReLU NNs without regularization can achieve near-optimal rates in nonparametric regression.
6/12/2024
🏋️
Adversarial Training of Two-Layer Polynomial and ReLU Activation Networks via Convex Optimization
Daniel Kuelbs, Sanjay Lall, Mert Pilanci
0
0
Training neural networks which are robust to adversarial attacks remains an important problem in deep learning, especially as heavily overparameterized models are adopted in safety-critical settings. Drawing from recent work which reformulates the training problems for two-layer ReLU and polynomial activation networks as convex programs, we devise a convex semidefinite program (SDP) for adversarial training of polynomial activation networks via the S-procedure. We also derive a convex SDP to compute the minimum distance from a correctly classified example to the decision boundary of a polynomial activation network. Adversarial training for two-layer ReLU activation networks has been explored in the literature, but, in contrast to prior work, we present a scalable approach which is compatible with standard machine libraries and GPU acceleration. The adversarial training SDP for polynomial activation networks leads to large increases in robust test accuracy against $ell^infty$ attacks on the Breast Cancer Wisconsin dataset from the UCI Machine Learning Repository. For two-layer ReLU networks, we leverage our scalable implementation to retrain the final two fully connected layers of a Pre-Activation ResNet-18 model on the CIFAR-10 dataset. Our 'robustified' model achieves higher clean and robust test accuracies than the same architecture trained with sharpness-aware minimization.
5/24/2024
↗️
Nonparametric regression using over-parameterized shallow ReLU neural networks
Yunfei Yang, Ding-Xuan Zhou
0
0
It is shown that over-parameterized neural networks can achieve minimax optimal rates of convergence (up to logarithmic factors) for learning functions from certain smooth function classes, if the weights are suitably constrained or regularized. Specifically, we consider the nonparametric regression of estimating an unknown $d$-variate function by using shallow ReLU neural networks. It is assumed that the regression function is from the Holder space with smoothness $alpha<(d+3)/2$ or a variation space corresponding to shallow neural networks, which can be viewed as an infinitely wide neural network. In this setting, we prove that least squares estimators based on shallow neural networks with certain norm constraints on the weights are minimax optimal, if the network width is sufficiently large. As a byproduct, we derive a new size-independent bound for the local Rademacher complexity of shallow ReLU neural networks, which may be of independent interest.
5/16/2024
🧠
On the growth of the parameters of approximating ReLU neural networks
Erion Morina, Martin Holler
0
0
This work focuses on the analysis of fully connected feed forward ReLU neural networks as they approximate a given, smooth function. In contrast to conventionally studied universal approximation properties under increasing architectures, e.g., in terms of width or depth of the networks, we are concerned with the asymptotic growth of the parameters of approximating networks. Such results are of interest, e.g., for error analysis or consistency results for neural network training. The main result of our work is that, for a ReLU architecture with state of the art approximation error, the realizing parameters grow at most polynomially. The obtained rate with respect to a normalized network size is compared to existing results and is shown to be superior in most cases, in particular for high dimensional input.
6/24/2024