Cracking the Code of Juxtaposition: Can AI Models Understand the Humorous Contradictions

0

Sign in to get full access
Overview
- This paper explores whether AI models can understand and generate humorous contradictions, a key aspect of humor.
- The researchers investigate how well language models can recognize and produce contradictory statements that are intended to be funny.
- They draw on related work in areas like red-teaming language models, humor generation, and irony detection.
Plain English Explanation
Humor often relies on contradictions or unexpected juxtapositions of ideas. For example, a comedian might say something like "I'm not superstitious, but I am a little stitious." This combines the serious concept of not being superstitious with the made-up word "stitious" to create a humorous effect.
The researchers wanted to see if AI language models could learn to recognize and generate this type of humorous contradiction. They looked at how well models could identify contradictory statements that were intended to be funny, and also whether the models could create their own humorous contradictions.
This builds on previous work that has explored using AI for things like detecting irony and aligning video and language. The researchers are pushing the boundaries of what AI can do by tasking it with understanding and generating more complex, nuanced forms of humor.
Technical Explanation
The paper first reviews related research in areas like red-teaming language models to probe their limitations, humor generation systems, and irony detection in text.
They then present two main experiments. In the first, they task large language models with identifying which statements in a set are intended to be humorous contradictions. The models must distinguish these from non-contradictory statements or contradictions that are not humorous.
In the second experiment, the researchers have the models generate their own humorous contradictions, building on the comment-aided video language alignment approach. They evaluate the models' outputs for coherence, humor, and contradiction.
The results show that current language models struggle to fully understand and produce the nuanced juxtapositions of ideas that make humorous contradictions effective. While the models can identify some clear cases, they often fail to recognize more subtle forms of contradiction-based humor.
Critical Analysis
The paper acknowledges several limitations of the current research. The datasets used are relatively small, and the humor annotations may be subjective. Additionally, the generative task of producing original humorous contradictions proves very challenging for models.
One could argue that truly understanding and generating humor requires a deeper level of common sense reasoning and world knowledge that today's language models lack. Recognizing the incongruity and playfulness of humorous contradictions may necessitate abilities that go beyond just language understanding.
Further research in this area could explore incorporating additional training signals, like human feedback or reinforcement learning, to help models better grasp the nuances of humor. Expanding the datasets and exploring alternative model architectures may also yield improvements.
Overall, this work highlights the difficulties AI systems face in mastering sophisticated forms of human communication like humor. While progress is being made, there remains significant room for advancement in this domain.
Conclusion
This paper investigates the ability of AI language models to understand and generate humorous contradictions - a key component of what makes many jokes and puns effective. The results show that current models struggle with this task, highlighting the limitations of their language understanding capabilities when it comes to more complex, context-dependent forms of communication.
However, the researchers view this as an important frontier for AI development. By pushing models to engage with humor, they hope to drive advancements that will allow AI to better comprehend and participate in natural human interactions. Continued progress in this area could have implications for a wide range of applications, from conversational assistants to entertainment generation.
While significant challenges remain, this work represents an intriguing step forward in the quest to imbue AI with a more nuanced grasp of language and human cognition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Cracking the Code of Juxtaposition: Can AI Models Understand the Humorous Contradictions
Zhe Hu, Tuo Liang, Jing Li, Yiren Lu, Yunlai Zhou, Yiran Qiao, Jing Ma, Yu Yin
Recent advancements in large multimodal language models have demonstrated remarkable proficiency across a wide range of tasks. Yet, these models still struggle with understanding the nuances of human humor through juxtaposition, particularly when it involves nonlinear narratives that underpin many jokes and humor cues. This paper investigates this challenge by focusing on comics with contradictory narratives, where each comic consists of two panels that create a humorous contradiction. We introduce the YesBut benchmark, which comprises tasks of varying difficulty aimed at assessing AI's capabilities in recognizing and interpreting these comics, ranging from literal content comprehension to deep narrative reasoning. Through extensive experimentation and analysis of recent commercial or open-sourced large (vision) language models, we assess their capability to comprehend the complex interplay of the narrative humor inherent in these comics. Our results show that even state-of-the-art models still lag behind human performance on this task. Our findings offer insights into the current limitations and potential improvements for AI in understanding human creative expressions.
Read more5/30/2024

0
Getting Serious about Humor: Crafting Humor Datasets with Unfunny Large Language Models
Zachary Horvitz, Jingru Chen, Rahul Aditya, Harshvardhan Srivastava, Robert West, Zhou Yu, Kathleen McKeown
Humor is a fundamental facet of human cognition and interaction. Yet, despite recent advances in natural language processing, humor detection remains a challenging task that is complicated by the scarcity of datasets that pair humorous texts with similar non-humorous counterparts. In our work, we investigate whether large language models (LLMs), can generate synthetic data for humor detection via editing texts. We benchmark LLMs on an existing human dataset and show that current LLMs display an impressive ability to 'unfun' jokes, as judged by humans and as measured on the downstream task of humor detection. We extend our approach to a code-mixed English-Hindi humor dataset, where we find that GPT-4's synthetic data is highly rated by bilingual annotators and provides challenging adversarial examples for humor classifiers.
Read more6/24/2024
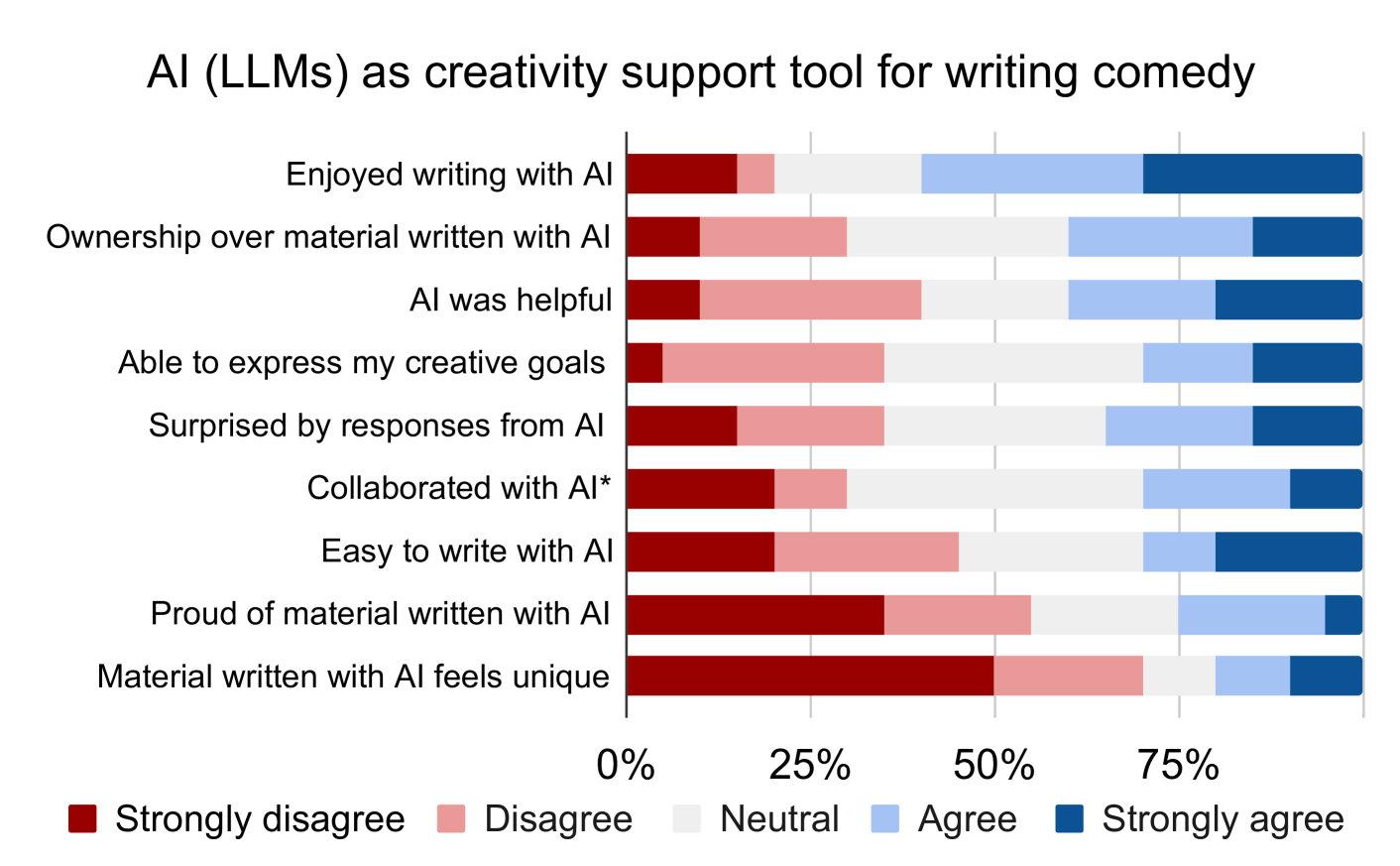
0
A Robot Walks into a Bar: Can Language Models Serve asCreativity Support Tools for Comedy? An Evaluation of LLMs' Humour Alignment with Comedians
Piotr Wojciech Mirowski, Juliette Love, Kory W. Mathewson, Shakir Mohamed
We interviewed twenty professional comedians who perform live shows in front of audiences and who use artificial intelligence in their artistic process as part of 3-hour workshops on ``AI x Comedy'' conducted at the Edinburgh Festival Fringe in August 2023 and online. The workshop consisted of a comedy writing session with large language models (LLMs), a human-computer interaction questionnaire to assess the Creativity Support Index of AI as a writing tool, and a focus group interrogating the comedians' motivations for and processes of using AI, as well as their ethical concerns about bias, censorship and copyright. Participants noted that existing moderation strategies used in safety filtering and instruction-tuned LLMs reinforced hegemonic viewpoints by erasing minority groups and their perspectives, and qualified this as a form of censorship. At the same time, most participants felt the LLMs did not succeed as a creativity support tool, by producing bland and biased comedy tropes, akin to ``cruise ship comedy material from the 1950s, but a bit less racist''. Our work extends scholarship about the subtle difference between, one the one hand, harmful speech, and on the other hand, ``offensive'' language as a practice of resistance, satire and ``punching up''. We also interrogate the global value alignment behind such language models, and discuss the importance of community-based value alignment and data ownership to build AI tools that better suit artists' needs.
Read more6/5/2024

0
Humor in AI: Massive Scale Crowd-Sourced Preferences and Benchmarks for Cartoon Captioning
Jifan Zhang, Lalit Jain, Yang Guo, Jiayi Chen, Kuan Lok Zhou, Siddharth Suresh, Andrew Wagenmaker, Scott Sievert, Timothy Rogers, Kevin Jamieson, Robert Mankoff, Robert Nowak
We present a novel multimodal preference dataset for creative tasks, consisting of over 250 million human ratings on more than 2.2 million captions, collected through crowdsourcing rating data for The New Yorker's weekly cartoon caption contest over the past eight years. This unique dataset supports the development and evaluation of multimodal large language models and preference-based fine-tuning algorithms for humorous caption generation. We propose novel benchmarks for judging the quality of model-generated captions, utilizing both GPT4 and human judgments to establish ranking-based evaluation strategies. Our experimental results highlight the limitations of current fine-tuning methods, such as RLHF and DPO, when applied to creative tasks. Furthermore, we demonstrate that even state-of-the-art models like GPT4 and Claude currently underperform top human contestants in generating humorous captions. As we conclude this extensive data collection effort, we release the entire preference dataset to the research community, fostering further advancements in AI humor generation and evaluation.
Read more6/18/2024