Critical Phase Transition in a Large Language Model
2406.05335
0
0

Abstract
The performance of large language models (LLMs) strongly depends on the textit{temperature} parameter. Empirically, at very low temperatures, LLMs generate sentences with clear repetitive structures, while at very high temperatures, generated sentences are often incomprehensible. In this study, using GPT-2, we numerically demonstrate that the difference between the two regimes is not just a smooth change but a phase transition with singular, divergent statistical quantities. Our extensive analysis shows that critical behaviors, such as a power-law decay of correlation in a text, emerge in the LLM at the transition temperature as well as in a natural language dataset. We also discuss that several statistical quantities characterizing the criticality should be useful to evaluate the performance of LLMs.
Create account to get full access
Overview
- This paper explores a critical phase transition in the output distribution of large language models (LLMs) as they scale in size and complexity.
- It investigates how the temperature parameter in LLMs affects their "creativity" and the emergence of novel patterns in their outputs.
- The research examines the relationship between the critical data size for LLMs to "grok" a task and the temperature parameter, shedding light on the so-called "time machine" effect in LLMs.
- The findings have implications for understanding the fundamental limits and emergent properties of these powerful AI systems.
Plain English Explanation
As large language models (LLMs) like GPT-3 and DALL-E become larger and more sophisticated, they can start to exhibit some strange and unexpected behaviors. This paper looks at one particular phenomenon: a "critical phase transition" in the way these models generate their outputs.
Imagine an LLM as a kind of AI that has been trained on a massive amount of text data, allowing it to generate human-like language. The researchers found that as these models get bigger and more complex, there's a point where the distribution of their outputs suddenly changes in a dramatic way. Before this transition, the model's outputs are relatively "tame" and predictable. But after the transition, the model starts generating much more novel and "creative" content - ideas and text that were not directly present in its training data.
The researchers also looked at how a key parameter in these models, called the "temperature," affects this phase transition. The temperature setting determines how "adventurous" the model is in exploring new ideas versus sticking to safe, familiar patterns. By adjusting the temperature, the researchers could control when this critical transition happens and how "creative" the model's outputs become.
This work helps us understand the fundamental limits and capabilities of these powerful AI systems. It suggests there may be inherent constraints on how "creative" and unpredictable LLMs can become, and how we can tune their behavior to balance reliability and novelty. This could have important implications as we continue to develop and deploy these technologies in the real world.
Technical Explanation
This paper investigates a critical phase transition in the output distribution of large language models (LLMs) as they scale in size and complexity. The researchers explore how the temperature parameter in LLMs affects the emergence of novel patterns and "creativity" in their generated outputs.
Through a series of experiments, the authors find that as LLMs grow in scale, there is a critical point where the distribution of their outputs undergoes a dramatic shift. Before this transition, the model's outputs are relatively constrained and predictable. But after the transition, the model starts generating much more diverse and "creative" content that departs significantly from its training data.
The researchers also examine the relationship between this critical phase transition and the critical data size required for an LLM to "grok" a given task. They find that the temperature parameter plays a key role in determining when this critical transition occurs, shedding light on the so-called "time machine" effect in LLMs.
The findings have broader implications for understanding the fundamental limits and emergent properties of large-scale language models. The curse of recursion in training on generated data may also be connected to these phase transition phenomena, suggesting inherent constraints on the "creativity" and unpredictability of LLM outputs.
Critical Analysis
The paper provides valuable insights into the complex dynamics underlying large language models, but it also raises some important caveats and areas for further research.
One key limitation is that the experiments were performed on relatively simple language modeling tasks, and it's unclear how well the findings would generalize to more complex, real-world applications of LLMs. The authors acknowledge that the critical phase transition may manifest differently in diverse domains and use cases.
Additionally, the paper focuses primarily on the temperature parameter as a lever for controlling the "creativity" of LLM outputs, but there may be other architectural or training choices that also play a significant role. Exploring these additional factors could help paint a more complete picture of the fundamental constraints and emergent properties of these systems.
It's also worth noting that the notion of "creativity" in the context of language models is inherently subjective and difficult to quantify. While the researchers propose metrics to assess novelty and diversity, there may be other important dimensions of "creativity" that are not captured by these measures.
Overall, this work represents an important step in understanding the fundamental limits and behaviors of large language models. By shedding light on the critical phase transitions in their output distributions, it lays the groundwork for further research into the complex dynamics and emergent properties of these powerful AI systems.
Conclusion
This paper uncovers a critical phase transition in the output distribution of large language models as they scale in size and complexity. The researchers demonstrate how the temperature parameter plays a key role in controlling the emergence of novel and "creative" patterns in the model's generated outputs.
The findings have important implications for our understanding of the fundamental limits and emergent properties of LLMs. They suggest inherent constraints on the "creativity" and unpredictability of these systems, which could inform the development and deployment of these technologies in the real world.
While the paper focuses on relatively simple language modeling tasks, the insights it provides offer a valuable starting point for further research into the complex dynamics of large-scale AI systems. Exploring the generalization of these phase transition phenomena to more diverse domains and use cases could yield important new discoveries and help us navigate the evolving landscape of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Phase Transitions in the Output Distribution of Large Language Models
Julian Arnold, Flemming Holtorf, Frank Schafer, Niels Lorch
0
0
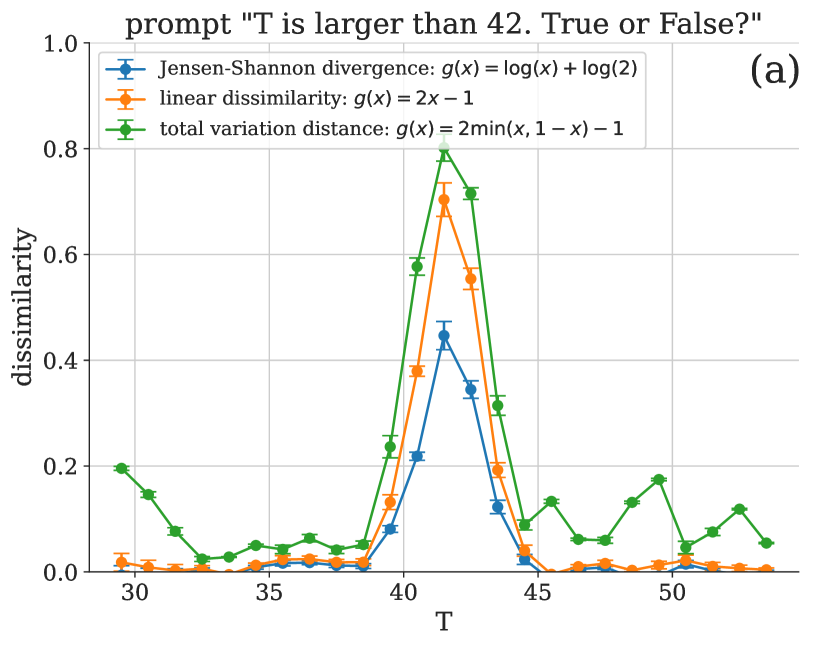
In a physical system, changing parameters such as temperature can induce a phase transition: an abrupt change from one state of matter to another. Analogous phenomena have recently been observed in large language models. Typically, the task of identifying phase transitions requires human analysis and some prior understanding of the system to narrow down which low-dimensional properties to monitor and analyze. Statistical methods for the automated detection of phase transitions from data have recently been proposed within the physics community. These methods are largely system agnostic and, as shown here, can be adapted to study the behavior of large language models. In particular, we quantify distributional changes in the generated output via statistical distances, which can be efficiently estimated with access to the probability distribution over next-tokens. This versatile approach is capable of discovering new phases of behavior and unexplored transitions -- an ability that is particularly exciting in light of the rapid development of language models and their emergent capabilities.
5/28/2024

Is Temperature the Creativity Parameter of Large Language Models?
Max Peeperkorn, Tom Kouwenhoven, Dan Brown, Anna Jordanous
0
0
Large language models (LLMs) are applied to all sorts of creative tasks, and their outputs vary from beautiful, to peculiar, to pastiche, into plain plagiarism. The temperature parameter of an LLM regulates the amount of randomness, leading to more diverse outputs; therefore, it is often claimed to be the creativity parameter. Here, we investigate this claim using a narrative generation task with a predetermined fixed context, model and prompt. Specifically, we present an empirical analysis of the LLM output for different temperature values using four necessary conditions for creativity in narrative generation: novelty, typicality, cohesion, and coherence. We find that temperature is weakly correlated with novelty, and unsurprisingly, moderately correlated with incoherence, but there is no relationship with either cohesion or typicality. However, the influence of temperature on creativity is far more nuanced and weak than suggested by the creativity parameter claim; overall results suggest that the LLM generates slightly more novel outputs as temperatures get higher. Finally, we discuss ideas to allow more controlled LLM creativity, rather than relying on chance via changing the temperature parameter.
5/2/2024
Critical Data Size of Language Models from a Grokking Perspective
Xuekai Zhu, Yao Fu, Bowen Zhou, Zhouhan Lin
0
0
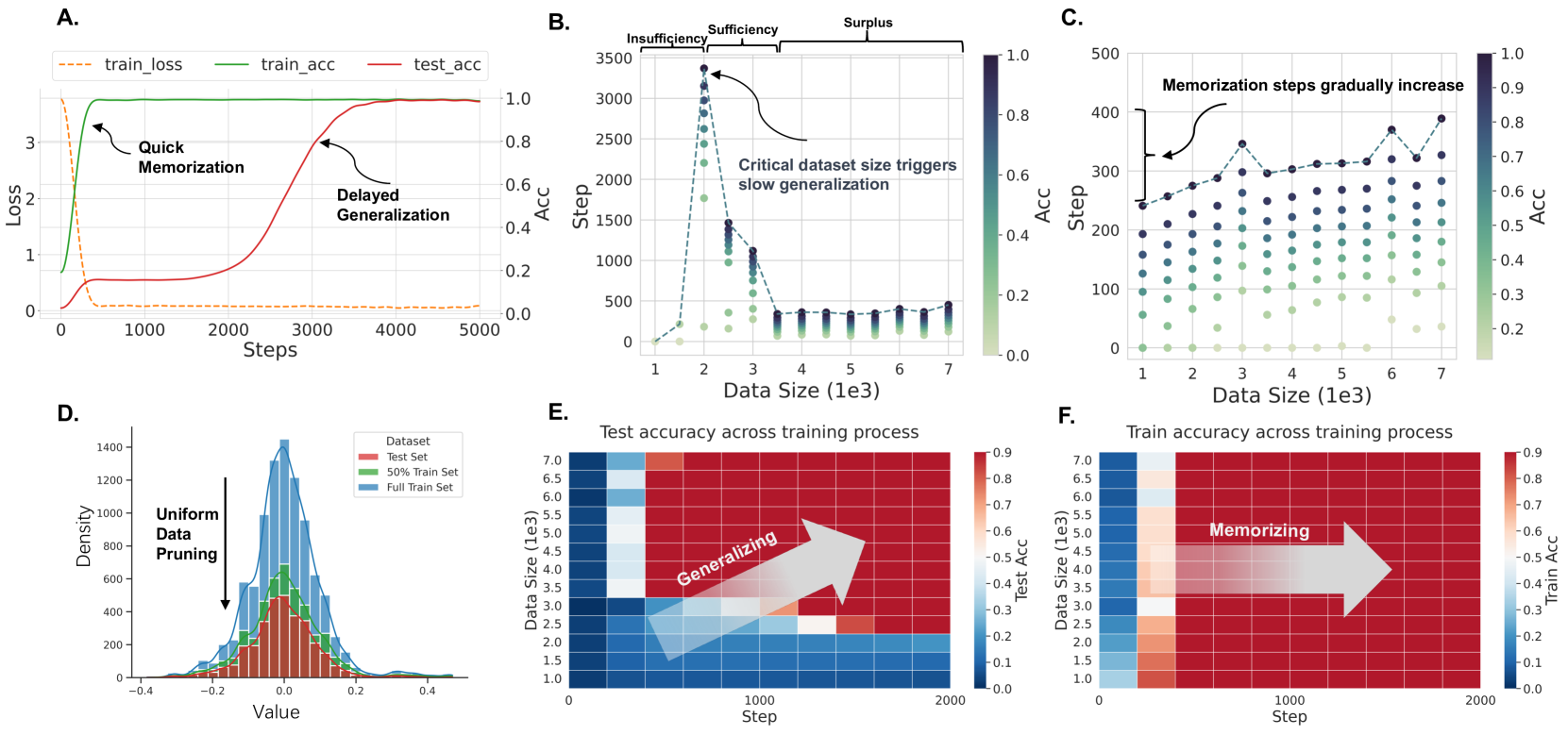
We explore the critical data size in language models, a threshold that marks a fundamental shift from quick memorization to slow generalization. We formalize the phase transition under the grokking configuration into the Data Efficiency Hypothesis and identify data insufficiency, sufficiency, and surplus regimes in language models training dynamics. We develop a grokking configuration to reproduce grokking on simplistic language models stably by rescaling initialization and weight decay. We show that generalization occurs only when language models reach a critical size. We analyze grokking across sample-wise and model-wise, verifying the proposed data efficiency hypothesis. Our experiments reveal smoother phase transitions occurring at the critical dataset size for language datasets. As the model size increases, this critical point also becomes larger, indicating that larger models require more data. Our results deepen the understanding of language model training, offering a novel perspective on the role of data in the learning mechanism of language models.
5/24/2024
🤿
Time Machine GPT
Felix Drinkall, Eghbal Rahimikia, Janet B. Pierrehumbert, Stefan Zohren
0
0
Large language models (LLMs) are often trained on extensive, temporally indiscriminate text corpora, reflecting the lack of datasets with temporal metadata. This approach is not aligned with the evolving nature of language. Conventional methods for creating temporally adapted language models often depend on further pre-training static models on time-specific data. This paper presents a new approach: a series of point-in-time LLMs called Time Machine GPT (TiMaGPT), specifically designed to be nonprognosticative. This ensures they remain uninformed about future factual information and linguistic changes. This strategy is beneficial for understanding language evolution and is of critical importance when applying models in dynamic contexts, such as time-series forecasting, where foresight of future information can prove problematic. We provide access to both the models and training datasets.
4/30/2024