Time Machine GPT
2404.18543
0
0
🤿
Abstract
Large language models (LLMs) are often trained on extensive, temporally indiscriminate text corpora, reflecting the lack of datasets with temporal metadata. This approach is not aligned with the evolving nature of language. Conventional methods for creating temporally adapted language models often depend on further pre-training static models on time-specific data. This paper presents a new approach: a series of point-in-time LLMs called Time Machine GPT (TiMaGPT), specifically designed to be nonprognosticative. This ensures they remain uninformed about future factual information and linguistic changes. This strategy is beneficial for understanding language evolution and is of critical importance when applying models in dynamic contexts, such as time-series forecasting, where foresight of future information can prove problematic. We provide access to both the models and training datasets.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Large language models (LLMs) are often trained on extensive, temporally indiscriminate text corpora, which does not align with the evolving nature of language.
- Conventional methods for creating temporally adapted language models often depend on further pre-training static models on time-specific data.
- This paper presents a new approach: a series of point-in-time LLMs called Time Machine GPT (TiMaGPT), specifically designed to be nonprognosticative, ensuring they remain uninformed about future factual information and linguistic changes.
Plain English Explanation
The paper discusses a new approach to training large language models (LLMs) that addresses a common issue with how these models are typically developed. LLMs are usually trained on a vast amount of text data from various sources, without considering the temporal aspect of language evolution. This means the models may not accurately reflect how language changes over time.
Conventional methods for creating temporally adapted language models often involve further pre-training static models on time-specific data. However, the paper introduces a different solution: Time Machine GPT (TiMaGPT), a series of point-in-time LLMs that are specifically designed to be "nonprognosticative." This means the models are kept uninformed about future factual information and linguistic changes, ensuring they remain aligned with the evolving nature of language.
This approach is beneficial for understanding language evolution and is crucial when applying models in dynamic contexts, such as time-series forecasting, where foresight of future information can be problematic. By providing access to both the models and training datasets, the researchers aim to enable further exploration and application of this technique.
Technical Explanation
The paper presents a new approach to training large language models (LLMs) called Time Machine GPT (TiMaGPT), which are designed to be "nonprognosticative." This means the models are trained in a way that ensures they remain uninformed about future factual information and linguistic changes, in contrast with the typical approach of training LLMs on extensive, temporally indiscriminate text corpora.
The researchers highlight that conventional methods for creating temporally adapted language models often rely on further pre-training static models on time-specific data. However, the TiMaGPT approach offers a novel solution by creating a series of point-in-time LLMs that are designed to be nonprognosticative.
This strategy is beneficial for understanding language evolution and is of critical importance when applying models in dynamic contexts, such as time-series forecasting, where foresight of future information can prove problematic. By providing access to both the models and training datasets, the researchers aim to enable further exploration and application of this technique.
Critical Analysis
The paper presents a compelling approach to addressing the issue of temporally indiscriminate training of large language models (LLMs). The Time Machine GPT (TiMaGPT) models are designed to be nonprognosticative, which helps to ensure they remain aligned with the evolving nature of language.
However, the paper does not provide a detailed evaluation of the performance of the TiMaGPT models compared to conventional LLMs or other temporally adapted language models. It would be helpful to see how the nonprognosticative approach affects the models' performance on tasks such as time-series forecasting or other applications where the temporal aspect of language is critical.
Additionally, the paper does not address the potential challenges or limitations of the TiMaGPT approach, such as the availability and quality of the training data, the scalability of the method to larger corpora, or the potential tradeoffs between the nonprognosticative design and the overall performance of the models.
It would also be valuable to see the researchers explore the divergent inductive biases that may arise from the TiMaGPT approach and how they compare to those of other language models, as this could provide deeper insights into the strengths and weaknesses of the proposed method.
Conclusion
The paper presents a novel approach to training large language models (LLMs) called Time Machine GPT (TiMaGPT), which are designed to be nonprognosticative. This means the models are trained in a way that ensures they remain uninformed about future factual information and linguistic changes, in contrast with the typical approach of training LLMs on extensive, temporally indiscriminate text corpora.
The TiMaGPT approach is beneficial for understanding language evolution and is of critical importance when applying models in dynamic contexts, such as time-series forecasting, where foresight of future information can prove problematic. By providing access to both the models and training datasets, the researchers aim to enable further exploration and application of this technique.
While the paper presents a promising solution, further evaluation and exploration of the TiMaGPT approach, including its limitations and potential tradeoffs, would be valuable to fully assess its impact and applicability in the field of natural language processing and time-series modeling.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
TimeGPT in Load Forecasting: A Large Time Series Model Perspective
Wenlong Liao, Fernando Porte-Agel, Jiannong Fang, Christian Rehtanz, Shouxiang Wang, Dechang Yang, Zhe Yang
0
0
Machine learning models have made significant progress in load forecasting, but their forecast accuracy is limited in cases where historical load data is scarce. Inspired by the outstanding performance of large language models (LLMs) in computer vision and natural language processing, this paper aims to discuss the potential of large time series models in load forecasting with scarce historical data. Specifically, the large time series model is constructed as a time series generative pre-trained transformer (TimeGPT), which is trained on massive and diverse time series datasets consisting of 100 billion data points (e.g., finance, transportation, banking, web traffic, weather, energy, healthcare, etc.). Then, the scarce historical load data is used to fine-tune the TimeGPT, which helps it to adapt to the data distribution and characteristics associated with load forecasting. Simulation results show that TimeGPT outperforms the benchmarks (e.g., popular machine learning models and statistical models) for load forecasting on several real datasets with scarce training samples, particularly for short look-ahead times. However, it cannot be guaranteed that TimeGPT is always superior to benchmarks for load forecasting with scarce data, since the performance of TimeGPT may be affected by the distribution differences between the load data and the training data. In practical applications, we can divide the historical data into a training set and a validation set, and then use the validation set loss to decide whether TimeGPT is the best choice for a specific dataset.
4/9/2024
Large Language Models for Time Series: A Survey
Xiyuan Zhang, Ranak Roy Chowdhury, Rajesh K. Gupta, Jingbo Shang
0
0
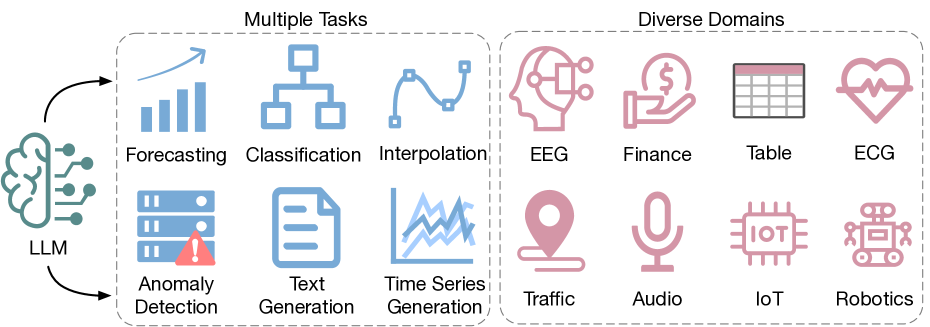
Large Language Models (LLMs) have seen significant use in domains such as natural language processing and computer vision. Going beyond text, image and graphics, LLMs present a significant potential for analysis of time series data, benefiting domains such as climate, IoT, healthcare, traffic, audio and finance. This survey paper provides an in-depth exploration and a detailed taxonomy of the various methodologies employed to harness the power of LLMs for time series analysis. We address the inherent challenge of bridging the gap between LLMs' original text data training and the numerical nature of time series data, and explore strategies for transferring and distilling knowledge from LLMs to numerical time series analysis. We detail various methodologies, including (1) direct prompting of LLMs, (2) time series quantization, (3) aligning techniques, (4) utilization of the vision modality as a bridging mechanism, and (5) the combination of LLMs with tools. Additionally, this survey offers a comprehensive overview of the existing multimodal time series and text datasets and delves into the challenges and future opportunities of this emerging field. We maintain an up-to-date Github repository which includes all the papers and datasets discussed in the survey.
5/8/2024
Large Language Models Can Learn Temporal Reasoning
Siheng Xiong, Ali Payani, Ramana Kompella, Faramarz Fekri
0
0
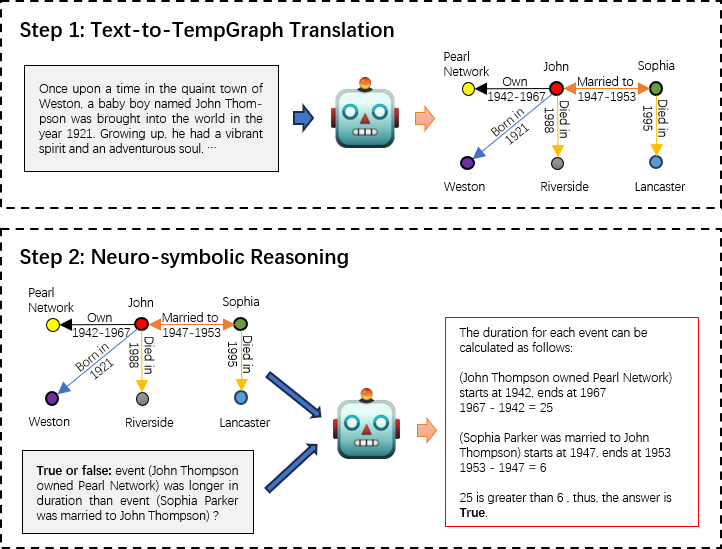
While large language models (LLMs) have demonstrated remarkable reasoning capabilities, they are not without their flaws and inaccuracies. Recent studies have introduced various methods to mitigate these limitations. Temporal reasoning (TR), in particular, presents a significant challenge for LLMs due to its reliance on diverse temporal expressions and intricate temporal logic. In this paper, we propose TG-LLM, a novel framework towards language-based TR. Instead of reasoning over the original context, we adopt a latent representation, temporal graph (TG) that facilitates the TR learning. A synthetic dataset (TGQA), which is fully controllable and requires minimal supervision, is constructed for fine-tuning LLMs on this text-to-TG translation task. We confirmed in experiments that the capability of TG translation learned on our dataset can be transferred to other TR tasks and benchmarks. On top of that, we teach LLM to perform deliberate reasoning over the TGs via Chain of Thought (CoT) bootstrapping and graph data augmentation. We observed that those strategies, which maintain a balance between usefulness and diversity, bring more reliable CoTs and final results than the vanilla CoT distillation.
4/23/2024
📈
ZzzGPT: An Interactive GPT Approach to Enhance Sleep Quality
Yonchanok Khaokaew, Kaixin Ji, Thuc Hanh Nguyen, Hiruni Kegalle, Marwah Alaofi, Hao Xue, Flora D. Salim
0
0
This paper explores the intersection of technology and sleep pattern comprehension, presenting a cutting-edge two-stage framework that harnesses the power of Large Language Models (LLMs). The primary objective is to deliver precise sleep predictions paired with actionable feedback, addressing the limitations of existing solutions. This innovative approach involves leveraging the GLOBEM dataset alongside synthetic data generated by LLMs. The results highlight significant improvements, underlining the efficacy of merging advanced machine-learning techniques with a user-centric design ethos. Through this exploration, we bridge the gap between technological sophistication and user-friendly design, ensuring that our framework yields accurate predictions and translates them into actionable insights.
5/8/2024