A Cross-Domain Benchmark for Active Learning

0
Sign in to get full access
Overview
- This paper introduces a new benchmark for evaluating active learning algorithms across diverse domains.
- Active learning aims to reduce the amount of labeled data required for training machine learning models by iteratively selecting the most informative samples for human labeling.
- The proposed benchmark covers 10 diverse datasets spanning computer vision, natural language processing, and tabular data tasks.
- It enables comprehensive evaluation of active learning methods and provides insights into their strengths and weaknesses across different problem settings.
Plain English Explanation
The paper presents a Cross-Domain Benchmark for Active Learning. Active learning is a machine learning technique where the algorithm actively selects the most informative data samples for human labeling, in order to train a model with fewer labeled examples.
The researchers created a new benchmark that includes 10 diverse datasets covering computer vision, natural language processing, and tabular data problems. This allows testing how well active learning methods perform across a wide range of real-world tasks, rather than just on a single dataset.
By using this benchmark, researchers and practitioners can better understand the strengths and limitations of different active learning algorithms. They can see which methods work well in certain domains but struggle in others, providing insights to improve the algorithms. This comprehensive evaluation helps advance the state of active learning research and development.
Technical Explanation
The paper introduces a Cross-Domain Benchmark for Active Learning that includes 10 diverse datasets spanning computer vision, natural language processing, and tabular data tasks. These datasets were carefully selected to cover a range of problem settings, data modalities, and class distributions.
The benchmark is designed to enable comprehensive evaluation of active learning methods. It includes utilities for simulating active learning scenarios, tracking performance metrics over the learning process, and visualizing results. The researchers use this benchmark to extensively evaluate several state-of-the-art active learning algorithms across the 10 datasets.
The experiments reveal interesting insights about the performance of these methods. For example, some algorithms excel on certain data types but struggle on others. The benchmark also highlights the importance of considering the underlying data distribution when selecting an active learning strategy. These findings can guide the development of more robust and effective active learning approaches in the future.
Critical Analysis
The Cross-Domain Benchmark for Active Learning presented in this paper is a valuable contribution to the field. By evaluating active learning methods on a diverse set of real-world tasks, the benchmark provides a more realistic and comprehensive assessment compared to previous evaluations on individual datasets.
One potential limitation is that the benchmark does not include datasets with extremely large or high-dimensional feature spaces, which may pose additional challenges for active learning algorithms. Additionally, the paper does not explore the impact of noisy or corrupted labels, which can be a common issue in real-world applications of active learning.
Further research could investigate active learning strategies that are more robust to dataset shifts or label noise, or that can effectively handle complex data modalities like audio or video. Exploring the integration of active learning with other machine learning techniques, such as few-shot learning or transfer learning, could also lead to valuable insights.
Overall, the Cross-Domain Benchmark for Active Learning represents a significant step forward in evaluating and understanding the performance of active learning algorithms. It provides a valuable tool for the research community to drive further advancements in this important area of machine learning.
Conclusion
This paper introduces a Cross-Domain Benchmark for Active Learning that enables comprehensive evaluation of active learning algorithms across a diverse range of real-world tasks. The benchmark covers 10 datasets spanning computer vision, natural language processing, and tabular data problems, allowing researchers and practitioners to better understand the strengths and limitations of different active learning methods.
The experimental results provide valuable insights into the performance of state-of-the-art active learning algorithms, highlighting the importance of considering the underlying data distribution when selecting an appropriate strategy. This benchmark represents an important contribution to the field, as it can guide the development of more robust and effective active learning approaches that can be deployed in a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Cross-Domain Benchmark for Active Learning
Thorben Werner, Johannes Burchert, Maximilian Stubbemann, Lars Schmidt-Thieme
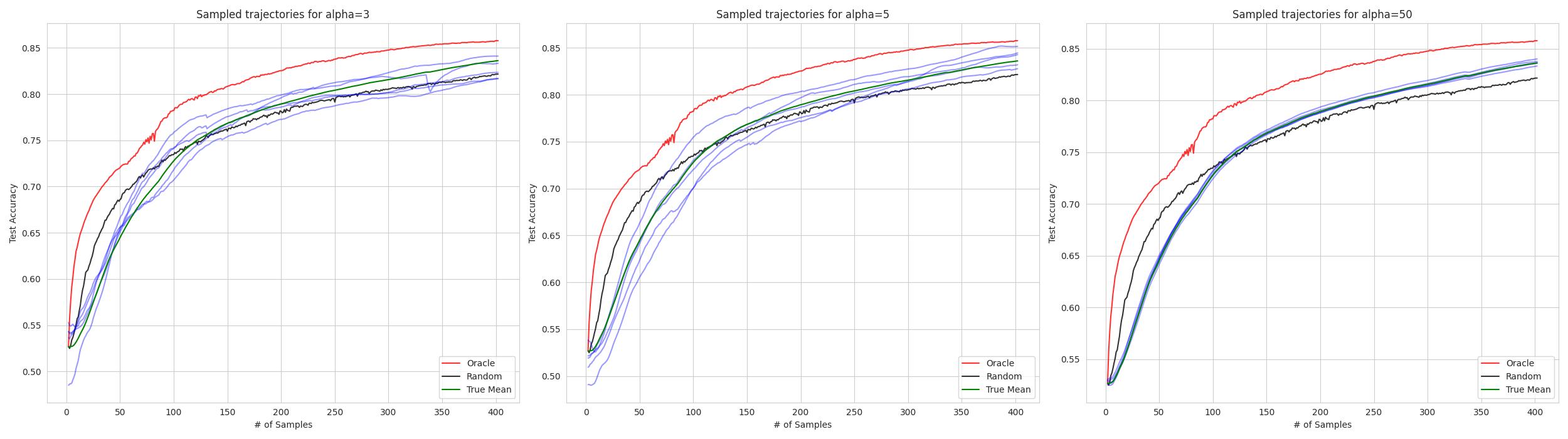
Active Learning (AL) deals with identifying the most informative samples for labeling to reduce data annotation costs for supervised learning tasks. AL research suffers from the fact that lifts from literature generalize poorly and that only a small number of repetitions of experiments are conducted. To overcome these obstacles, we propose emph{CDALBench}, the first active learning benchmark which includes tasks in computer vision, natural language processing and tabular learning. Furthermore, by providing an efficient, greedy oracle, emph{CDALBench} can be evaluated with 50 runs for each experiment. We show, that both the cross-domain character and a large amount of repetitions are crucial for sophisticated evaluation of AL research. Concretely, we show that the superiority of specific methods varies over the different domains, making it important to evaluate Active Learning with a cross-domain benchmark. Additionally, we show that having a large amount of runs is crucial. With only conducting three runs as often done in the literature, the superiority of specific methods can strongly vary with the specific runs. This effect is so strong, that, depending on the seed, even a well-established method's performance can be significantly better and significantly worse than random for the same dataset.
Read more8/2/2024

0
On the Fragility of Active Learners
Abhishek Ghose, Emma Thuong Nguyen
Active learning (AL) techniques optimally utilize a labeling budget by iteratively selecting instances that are most valuable for learning. However, they lack ``prerequisite checks'', i.e., there are no prescribed criteria to pick an AL algorithm best suited for a dataset. A practitioner must pick a technique they emph{trust} would beat random sampling, based on prior reported results, and hope that it is resilient to the many variables in their environment: dataset, labeling budget and prediction pipelines. The important questions then are: how often on average, do we expect any AL technique to reliably beat the computationally cheap and easy-to-implement strategy of random sampling? Does it at least make sense to use AL in an ``Always ON'' mode in a prediction pipeline, so that while it might not always help, it never under-performs random sampling? How much of a role does the prediction pipeline play in AL's success? We examine these questions in detail for the task of text classification using pre-trained representations, which are ubiquitous today. Our primary contribution here is a rigorous evaluation of AL techniques, old and new, across setups that vary wrt datasets, text representations and classifiers. This unlocks multiple insights around warm-up times, i.e., number of labels before gains from AL are seen, viability of an ``Always ON'' mode and the relative significance of different factors. Additionally, we release a framework for rigorous benchmarking of AL techniques for text classification.
Read more7/18/2024
🤿
0
A Survey on Deep Active Learning: Recent Advances and New Frontiers
Dongyuan Li, Zhen Wang, Yankai Chen, Renhe Jiang, Weiping Ding, Manabu Okumura
Active learning seeks to achieve strong performance with fewer training samples. It does this by iteratively asking an oracle to label new selected samples in a human-in-the-loop manner. This technique has gained increasing popularity due to its broad applicability, yet its survey papers, especially for deep learning-based active learning (DAL), remain scarce. Therefore, we conduct an advanced and comprehensive survey on DAL. We first introduce reviewed paper collection and filtering. Second, we formally define the DAL task and summarize the most influential baselines and widely used datasets. Third, we systematically provide a taxonomy of DAL methods from five perspectives, including annotation types, query strategies, deep model architectures, learning paradigms, and training processes, and objectively analyze their strengths and weaknesses. Then, we comprehensively summarize main applications of DAL in Natural Language Processing (NLP), Computer Vision (CV), and Data Mining (DM), etc. Finally, we discuss challenges and perspectives after a detailed analysis of current studies. This work aims to serve as a useful and quick guide for researchers in overcoming difficulties in DAL. We hope that this survey will spur further progress in this burgeoning field.
Read more7/16/2024

0
Active Learning of Molecular Data for Task-Specific Objectives
Kunal Ghosh, Milica Todorovi'c, Aki Vehtari, Patrick Rinke
Active learning (AL) has shown promise for being a particularly data-efficient machine learning approach. Yet, its performance depends on the application and it is not clear when AL practitioners can expect computational savings. Here, we carry out a systematic AL performance assessment for three diverse molecular datasets and two common scientific tasks: compiling compact, informative datasets and targeted molecular searches. We implemented AL with Gaussian processes (GP) and used the many-body tensor as molecular representation. For the first task, we tested different data acquisition strategies, batch sizes and GP noise settings. AL was insensitive to the acquisition batch size and we observed the best AL performance for the acquisition strategy that combines uncertainty reduction with clustering to promote diversity. However, for optimal GP noise settings, AL did not outperform randomized selection of data points. Conversely, for targeted searches, AL outperformed random sampling and achieved data savings up to 64%. Our analysis provides insight into this task-specific performance difference in terms of target distributions and data collection strategies. We established that the performance of AL depends on the relative distribution of the target molecules in comparison to the total dataset distribution, with the largest computational savings achieved when their overlap is minimal.
Read more8/22/2024