Cross-Domain Learning for Video Anomaly Detection with Limited Supervision

0

Sign in to get full access
Overview
- This paper presents a cross-domain learning approach for video anomaly detection with limited supervision.
- The method aims to leverage knowledge from a source domain with abundant labeled data to improve anomaly detection in a target domain with limited labeled data.
- The proposed approach uses contrastive learning to align feature representations across domains and incorporates a new consistency regularization technique to enhance the model's performance.
Plain English Explanation
The paper focuses on the problem of video anomaly detection, which is the task of identifying unusual or abnormal events in video footage. This is an important task with applications in areas like security, surveillance, and autonomous systems.
One of the challenges in video anomaly detection is that it can be difficult to obtain a large amount of labeled training data, especially for the "anomalous" events that the system needs to detect. The researchers propose a cross-domain learning approach to address this issue.
The key idea is to leverage knowledge from a "source" domain where there is abundant labeled data, and use it to improve anomaly detection in a "target" domain where labeled data is scarce. The researchers use a contrastive learning approach to align the feature representations across the two domains, so that the model can effectively transfer knowledge from the source to the target.
Additionally, the researchers introduce a new "consistency regularization" technique to further enhance the model's performance. This helps ensure that the model's predictions are consistent across different views or transformations of the same input video.
By combining these cross-domain and consistency-based techniques, the researchers demonstrate improved anomaly detection results on several benchmark datasets, even when the target domain has limited labeled data available.
Technical Explanation
The paper proposes a Cross-domain Learning for Video Anomaly Detection with Limited Supervision (CLVAD) approach. The key components of the method are:
-
Cross-domain Contrastive Learning: The model learns a shared feature representation across the source and target domains by optimizing a contrastive loss function. This encourages the model to capture domain-invariant features that are useful for anomaly detection.
-
Consistency Regularization: The researchers introduce a new consistency regularization term that encourages the model's predictions to be consistent across different transformations of the same input video. This helps improve the model's robustness and generalization.
-
Anomaly Detection: The model uses the learned feature representations to detect anomalies in the target domain. Specifically, the researchers employ a one-class classification approach, where the model learns a decision boundary around the normal events and identifies deviations from this boundary as anomalies.
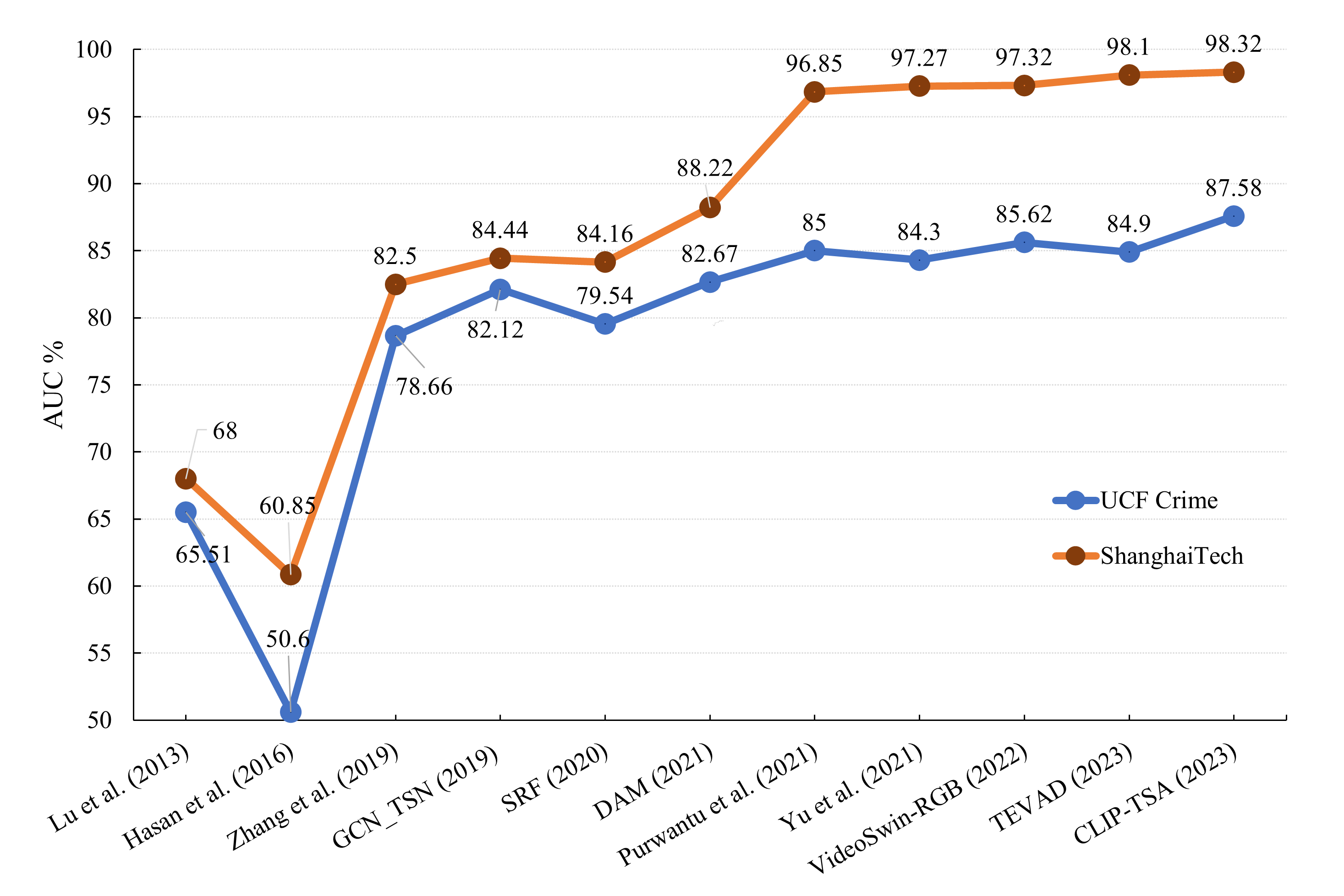
The paper evaluates the proposed CLVAD approach on several video anomaly detection datasets, including ShanghaiTech, UCSDPed2, and CUHK Avenue. The results demonstrate that CLVAD outperforms various baselines, including state-of-the-art unsupervised domain adaptation and anomaly detection methods, especially when the target domain has limited labeled data available.
Critical Analysis
The paper presents a novel and promising approach for video anomaly detection with limited supervision. The key strengths of the method are:
-
Cross-domain Learning: The ability to leverage knowledge from a source domain with abundant labeled data can be highly valuable, especially in scenarios where target domain data is scarce.
-
Consistency Regularization: The introduced consistency regularization technique appears to be an effective way to improve the model's robustness and generalization.
However, the paper also has a few potential limitations:
-
Domain Shift: While the cross-domain learning approach aims to address the domain shift between the source and target domains, the paper does not provide a thorough analysis of the types of domain shifts that the method can handle. Further research may be needed to understand the limitations and boundaries of the proposed approach.
-
Computational Complexity: The additional components introduced in the CLVAD method, such as the contrastive learning and consistency regularization, may increase the computational complexity of the model. The practicality of the approach for real-world, large-scale applications should be further investigated.
-
Generalization to Other Tasks: The paper focuses solely on video anomaly detection, and it is unclear how the proposed techniques could be generalized to other computer vision or machine learning tasks that also suffer from limited supervision.
Overall, the paper presents a well-designed and promising approach for addressing the challenge of video anomaly detection with limited labeled data. Further research exploring the method's broader applicability and addressing the identified limitations would be valuable contributions to the field.
Conclusion
This paper introduces a cross-domain learning approach for video anomaly detection that can effectively leverage knowledge from a source domain with abundant labeled data to improve performance in a target domain with limited labeled data. The key innovations include the use of contrastive learning to align feature representations across domains and a new consistency regularization technique to enhance the model's robustness.
The experimental results demonstrate the effectiveness of the proposed CLVAD approach, particularly in scenarios where the target domain has limited labeled data available. This work highlights the potential of cross-domain learning techniques to address the challenge of limited supervision in computer vision tasks, and the insights gained could have broader implications for other applications facing similar data scarcity issues.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Cross-Domain Learning for Video Anomaly Detection with Limited Supervision
Yashika Jain, Ali Dabouei, Min Xu
Video Anomaly Detection (VAD) automates the identification of unusual events, such as security threats in surveillance videos. In real-world applications, VAD models must effectively operate in cross-domain settings, identifying rare anomalies and scenarios not well-represented in the training data. However, existing cross-domain VAD methods focus on unsupervised learning, resulting in performance that falls short of real-world expectations. Since acquiring weak supervision, i.e., video-level labels, for the source domain is cost-effective, we conjecture that combining it with external unlabeled data has notable potential to enhance cross-domain performance. To this end, we introduce a novel weakly-supervised framework for Cross-Domain Learning (CDL) in VAD that incorporates external data during training by estimating its prediction bias and adaptively minimizing that using the predicted uncertainty. We demonstrate the effectiveness of the proposed CDL framework through comprehensive experiments conducted in various configurations on two large-scale VAD datasets: UCF-Crime and XD-Violence. Our method significantly surpasses the state-of-the-art works in cross-domain evaluations, achieving an average absolute improvement of 19.6% on UCF-Crime and 12.87% on XD-Violence.
Read more8/12/2024
0
Video Anomaly Detection in 10 Years: A Survey and Outlook
Moshira Abdalla, Sajid Javed, Muaz Al Radi, Anwaar Ulhaq, Naoufel Werghi
Video anomaly detection (VAD) holds immense importance across diverse domains such as surveillance, healthcare, and environmental monitoring. While numerous surveys focus on conventional VAD methods, they often lack depth in exploring specific approaches and emerging trends. This survey explores deep learning-based VAD, expanding beyond traditional supervised training paradigms to encompass emerging weakly supervised, self-supervised, and unsupervised approaches. A prominent feature of this review is the investigation of core challenges within the VAD paradigms including large-scale datasets, features extraction, learning methods, loss functions, regularization, and anomaly score prediction. Moreover, this review also investigates the vision language models (VLMs) as potent feature extractors for VAD. VLMs integrate visual data with textual descriptions or spoken language from videos, enabling a nuanced understanding of scenes crucial for anomaly detection. By addressing these challenges and proposing future research directions, this review aims to foster the development of robust and efficient VAD systems leveraging the capabilities of VLMs for enhanced anomaly detection in complex real-world scenarios. This comprehensive analysis seeks to bridge existing knowledge gaps, provide researchers with valuable insights, and contribute to shaping the future of VAD research.
Read more7/2/2024
0
Deep Learning for Video Anomaly Detection: A Review
Peng Wu, Chengyu Pan, Yuting Yan, Guansong Pang, Peng Wang, Yanning Zhang
Video anomaly detection (VAD) aims to discover behaviors or events deviating from the normality in videos. As a long-standing task in the field of computer vision, VAD has witnessed much good progress. In the era of deep learning, with the explosion of architectures of continuously growing capability and capacity, a great variety of deep learning based methods are constantly emerging for the VAD task, greatly improving the generalization ability of detection algorithms and broadening the application scenarios. Therefore, such a multitude of methods and a large body of literature make a comprehensive survey a pressing necessity. In this paper, we present an extensive and comprehensive research review, covering the spectrum of five different categories, namely, semi-supervised, weakly supervised, fully supervised, unsupervised and open-set supervised VAD, and we also delve into the latest VAD works based on pre-trained large models, remedying the limitations of past reviews in terms of only focusing on semi-supervised VAD and small model based methods. For the VAD task with different levels of supervision, we construct a well-organized taxonomy, profoundly discuss the characteristics of different types of methods, and show their performance comparisons. In addition, this review involves the public datasets, open-source codes, and evaluation metrics covering all the aforementioned VAD tasks. Finally, we provide several important research directions for the VAD community.
Read more9/10/2024
🤷
0
Video Unsupervised Domain Adaptation with Deep Learning: A Comprehensive Survey
Yuecong Xu, Haozhi Cao, Zhenghua Chen, Xiaoli Li, Lihua Xie, Jianfei Yang
Video analysis tasks such as action recognition have received increasing research interest with growing applications in fields such as smart healthcare, thanks to the introduction of large-scale datasets and deep learning-based representations. However, video models trained on existing datasets suffer from significant performance degradation when deployed directly to real-world applications due to domain shifts between the training public video datasets (source video domains) and real-world videos (target video domains). Further, with the high cost of video annotation, it is more practical to use unlabeled videos for training. To tackle performance degradation and address concerns in high video annotation cost uniformly, the video unsupervised domain adaptation (VUDA) is introduced to adapt video models from the labeled source domain to the unlabeled target domain by alleviating video domain shift, improving the generalizability and portability of video models. This paper surveys recent progress in VUDA with deep learning. We begin with the motivation of VUDA, followed by its definition, and recent progress of methods for both closed-set VUDA and VUDA under different scenarios, and current benchmark datasets for VUDA research. Eventually, future directions are provided to promote further VUDA research. The repository of this survey is provided at https://github.com/xuyu0010/awesome-video-domain-adaptation.
Read more7/30/2024