Cross-lingual, Character-Level Neural Morphological Tagging
1708.09157
0
0
🧠
Abstract
Even for common NLP tasks, sufficient supervision is not available in many languages -- morphological tagging is no exception. In the work presented here, we explore a transfer learning scheme, whereby we train character-level recurrent neural taggers to predict morphological taggings for high-resource languages and low-resource languages together. Learning joint character representations among multiple related languages successfully enables knowledge transfer from the high-resource languages to the low-resource ones, improving accuracy by up to 30% over a monolingual model.
Create account to get full access
Overview
- Morphological tagging is a common natural language processing (NLP) task that is challenging in low-resource languages due to lack of supervision data.
- This paper explores a transfer learning approach to improve morphological tagging in low-resource languages.
- The key idea is to train character-level recurrent neural taggers jointly on high-resource and low-resource languages, enabling knowledge transfer from high-resource to low-resource languages.
- This approach can improve accuracy by up to 30% over monolingual models for low-resource languages.
Plain English Explanation
Morphological tagging is the process of identifying the grammatical structure of words in a language, such as whether a word is a noun, verb, adjective, etc. This is an important task in natural language processing that helps computers better understand the meaning and structure of text.
However, for many languages around the world, there is not enough labeled training data available to build accurate morphological taggers. The researchers in this paper came up with a clever solution to this problem. They trained a single neural network model to do morphological tagging, but they trained it on data from both high-resource languages (languages with lots of data) and low-resource languages (languages with little data).
By learning the patterns and structures common across related languages, the model was able to transfer knowledge from the high-resource languages to significantly improve its performance on the low-resource languages - up to a 30% increase in accuracy compared to models trained only on the low-resource language data.
This is an important advance because it means we can now build better NLP tools for a wider range of languages, even if we don't have a lot of data for them. It's a great example of how transfer learning can be used to overcome the challenges of working with limited data.
Technical Explanation
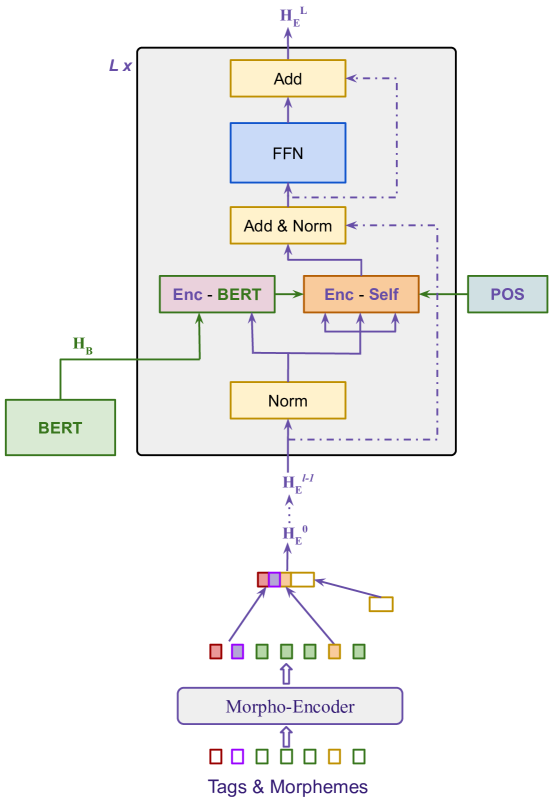
The key technical innovation in this paper is a character-level recurrent neural network architecture trained jointly on high-resource and low-resource languages for the task of morphological tagging.
The researchers hypothesized that by learning joint character representations across multiple related languages, the model would be able to effectively transfer knowledge from high-resource to low-resource languages, overcoming the lack of supervision data in the low-resource settings.
To test this, they trained their character-level recurrent neural tagger on a combination of high-resource and low-resource language data, using a multi-task learning setup where the model had to predict the morphological tags for each language. The model was able to learn shared patterns in the character sequences and morphological structures across the languages.
When evaluated on low-resource languages, this joint training approach resulted in accuracy improvements of up to 30% over monolingual models trained only on the low-resource language data. The researchers attribute this to the model's ability to leverage the higher-quality linguistic patterns learned from the high-resource languages.
Critical Analysis
The main strength of this research is its practical application in improving NLP capabilities for low-resource languages, which is a longstanding challenge in the field. By demonstrating the effectiveness of cross-lingual transfer learning for morphological tagging, the paper opens up new possibilities for building high-performing NLP models even when limited training data is available.
However, the paper also acknowledges some limitations. The experiments were conducted on a relatively small set of languages, so further research is needed to evaluate the broader applicability of the approach. Additionally, the types of languages and language families included may have influenced the degree of transferability, so the performance gains may vary depending on the specific languages involved.
Another potential concern is the interpretability of the learned character-level representations. While the results show the effectiveness of the approach, it's not entirely clear what linguistic patterns the model is capturing and leveraging for transfer learning. Lemmatization and other analysis techniques could provide additional insights into the model's inner workings.
Overall, this research represents an important step forward in addressing the challenge of building robust NLP capabilities for low-resource languages. The findings encourage further exploration of cross-lingual transfer learning and other techniques to enhance the accessibility and performance of language technologies worldwide.
Conclusion
This paper presents a novel transfer learning approach to improve morphological tagging in low-resource languages. By training a character-level recurrent neural network jointly on high-resource and low-resource languages, the model is able to leverage shared linguistic patterns and effectively transfer knowledge from high-resource to low-resource settings.
The results demonstrate significant accuracy gains of up to 30% over monolingual models, highlighting the power of cross-lingual transfer learning to overcome the lack of supervision data in many languages. This research opens up new possibilities for building high-performing NLP tools that can benefit a wider range of language communities globally.
As the field of natural language processing continues to advance, techniques like the one presented in this paper will be crucial for ensuring that the benefits of these technologies are accessible to all, regardless of the availability of language resources.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Low-Resource Named Entity Recognition with Cross-Lingual, Character-Level Neural Conditional Random Fields
Ryan Cotterell, Kevin Duh
0
0
Low-resource named entity recognition is still an open problem in NLP. Most state-of-the-art systems require tens of thousands of annotated sentences in order to obtain high performance. However, for most of the world's languages, it is unfeasible to obtain such annotation. In this paper, we present a transfer learning scheme, whereby we train character-level neural CRFs to predict named entities for both high-resource languages and low resource languages jointly. Learning character representations for multiple related languages allows transfer among the languages, improving F1 by up to 9.8 points over a loglinear CRF baseline.
4/16/2024
Low-resource neural machine translation with morphological modeling
Antoine Nzeyimana
0
0
Morphological modeling in neural machine translation (NMT) is a promising approach to achieving open-vocabulary machine translation for morphologically-rich languages. However, existing methods such as sub-word tokenization and character-based models are limited to the surface forms of the words. In this work, we propose a framework-solution for modeling complex morphology in low-resource settings. A two-tier transformer architecture is chosen to encode morphological information at the inputs. At the target-side output, a multi-task multi-label training scheme coupled with a beam search-based decoder are found to improve machine translation performance. An attention augmentation scheme to the transformer model is proposed in a generic form to allow integration of pre-trained language models and also facilitate modeling of word order relationships between the source and target languages. Several data augmentation techniques are evaluated and shown to increase translation performance in low-resource settings. We evaluate our proposed solution on Kinyarwanda - English translation using public-domain parallel text. Our final models achieve competitive performance in relation to large multi-lingual models. We hope that our results will motivate more use of explicit morphological information and the proposed model and data augmentations in low-resource NMT.
4/4/2024
💬
Heidelberg-Boston @ SIGTYP 2024 Shared Task: Enhancing Low-Resource Language Analysis With Character-Aware Hierarchical Transformers
Frederick Riemenschneider, Kevin Krahn
0
0
Historical languages present unique challenges to the NLP community, with one prominent hurdle being the limited resources available in their closed corpora. This work describes our submission to the constrained subtask of the SIGTYP 2024 shared task, focusing on PoS tagging, morphological tagging, and lemmatization for 13 historical languages. For PoS and morphological tagging we adapt a hierarchical tokenization method from Sun et al. (2023) and combine it with the advantages of the DeBERTa-V3 architecture, enabling our models to efficiently learn from every character in the training data. We also demonstrate the effectiveness of character-level T5 models on the lemmatization task. Pre-trained from scratch with limited data, our models achieved first place in the constrained subtask, nearly reaching the performance levels of the unconstrained task's winner. Our code is available at https://github.com/bowphs/SIGTYP-2024-hierarchical-transformers
5/31/2024
📈
A Simple Joint Model for Improved Contextual Neural Lemmatization
Chaitanya Malaviya, Shijie Wu, Ryan Cotterell
0
0
English verbs have multiple forms. For instance, talk may also appear as talks, talked or talking, depending on the context. The NLP task of lemmatization seeks to map these diverse forms back to a canonical one, known as the lemma. We present a simple joint neural model for lemmatization and morphological tagging that achieves state-of-the-art results on 20 languages from the Universal Dependencies corpora. Our paper describes the model in addition to training and decoding procedures. Error analysis indicates that joint morphological tagging and lemmatization is especially helpful in low-resource lemmatization and languages that display a larger degree of morphological complexity. Code and pre-trained models are available at https://sigmorphon.github.io/sharedtasks/2019/task2/.
5/29/2024